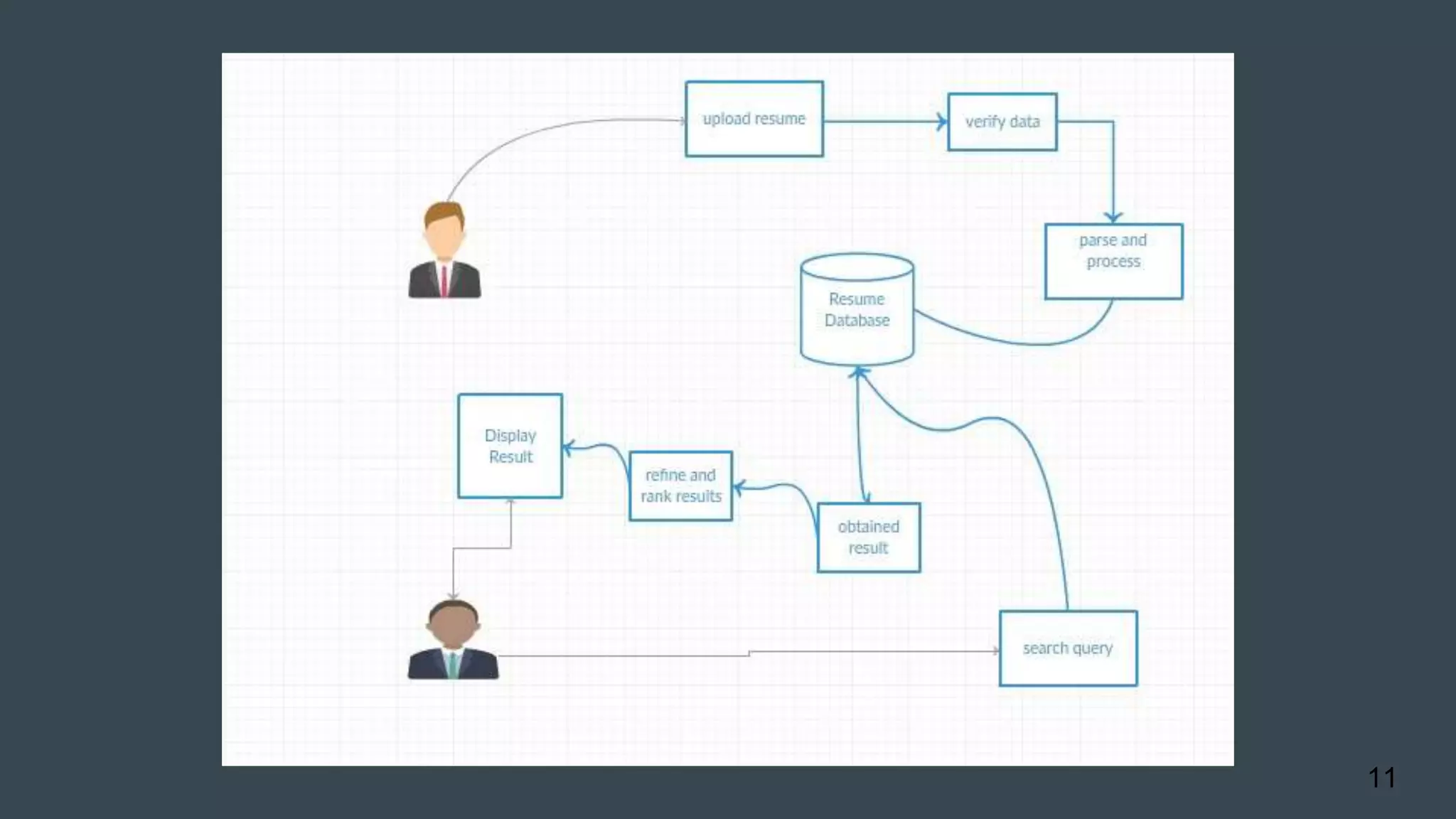
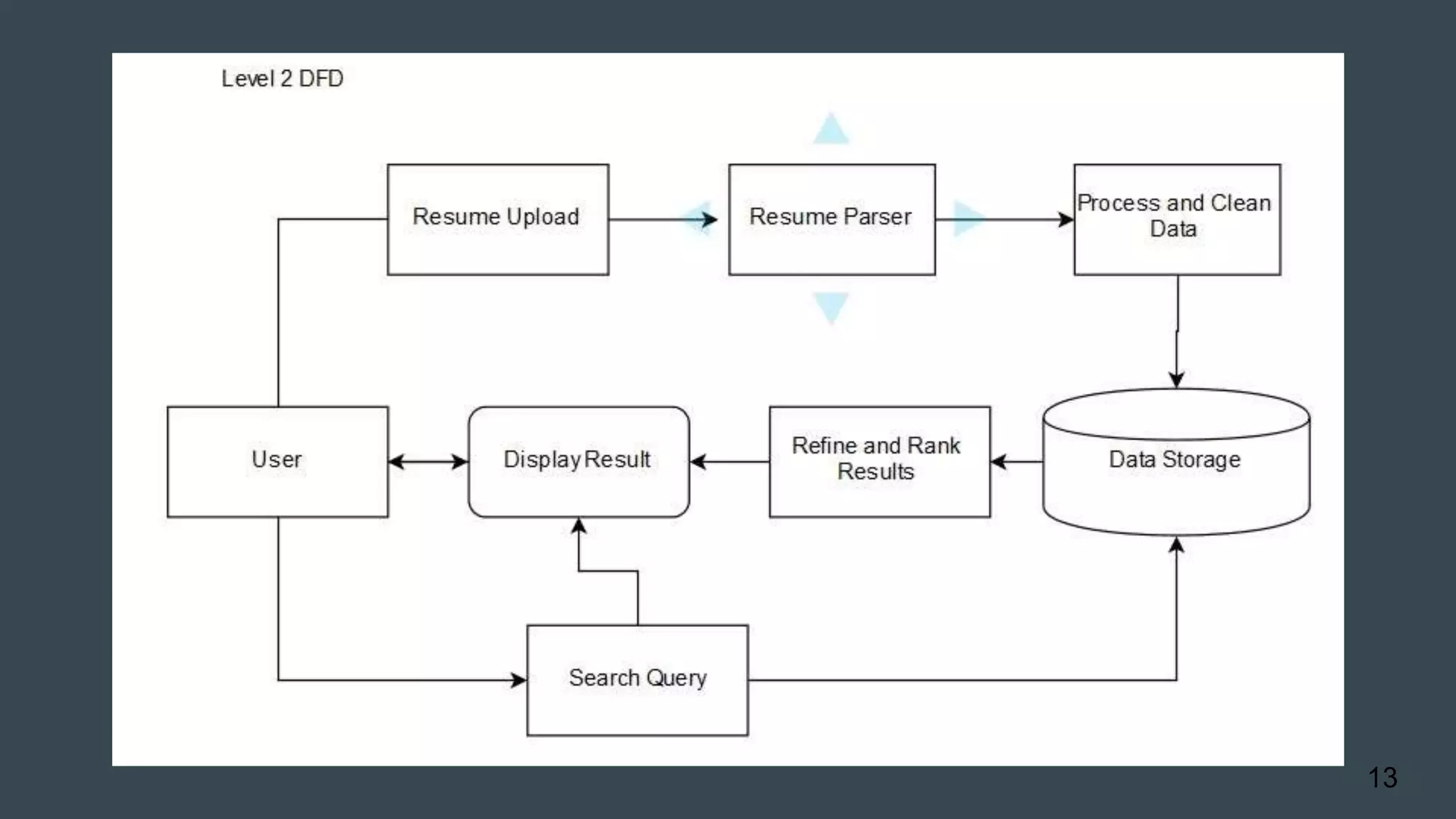
The document details a project aimed at automating the parsing and searching of resumes by converting unstructured resume files into a structured format suitable for storage and retrieval. It outlines the architecture, technologies used (Java, Hadoop, MySQL), and the workflow for processing input resumes and executing search queries. Future enhancements include expanding supported formats and integrating machine learning for improved data extraction.
























![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)











































































