Download as PDF, PPTX




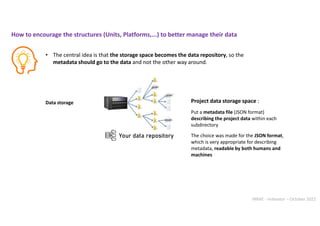
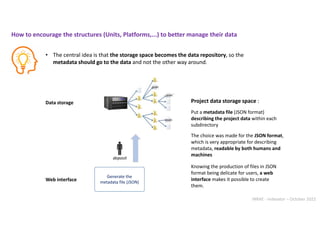
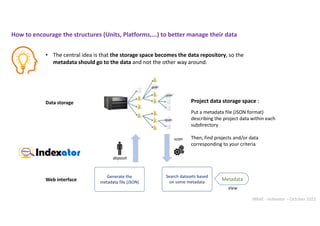



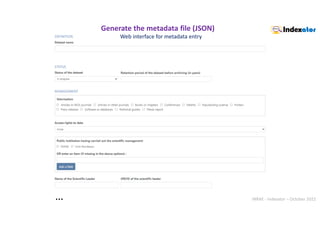




![INRAE - Indexator – October 2022
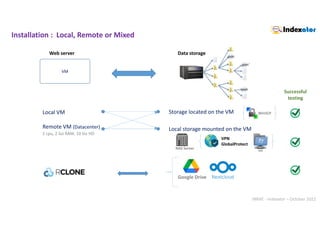
web/js/autocomplete/cities.js
Web interface
Example with
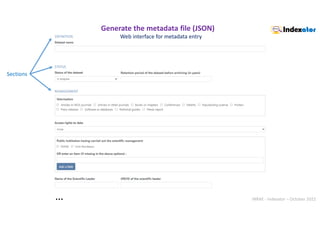
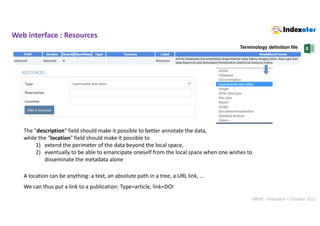
Web interface : autocompletion
.
.
API « Découpage administratif » (Administrative division)
var cities=[];
$.getJSON("https://geo.api.gouv.fr/communes", function (data) {
$.each(data, function (index, value) { cities.push(value['nom']); });
});
. Terminology definition file](https://image.slidesharecdn.com/indexatoroct2022-221010102047-bdbb412b/85/Indexator_oct2022-pdf-26-320.jpg)
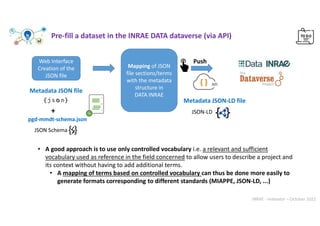
![INRAE - Indexator – October 2022
// Get all descendant classes from 'Data' classe
edam_data=[];
get_terms_from_bioportal('EDAM', 'http://edamontology.org/data_0006', 'edam_data');
web/js/autocomplete/edam_data.js
To get information about the BioPortal API : https://data.bioontology.org/documentation
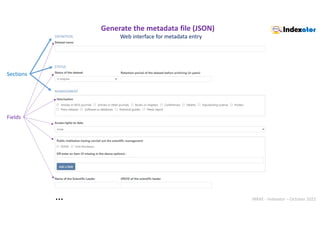
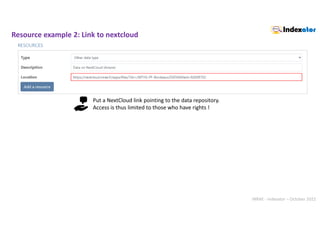
Web interface : autocompletion Example with
https://bioportal.bioontology.org/ontologies/EDAM/?p=classes
“datatype":{
"titre":"Data type",
"autocomplete":"edam_data",
"width":"350px“
}
web/json/config_terms.json
.
Web interface
.
.
Choose from 947 terms
autocompletion](https://image.slidesharecdn.com/indexatoroct2022-221010102047-bdbb412b/85/Indexator_oct2022-pdf-27-320.jpg)
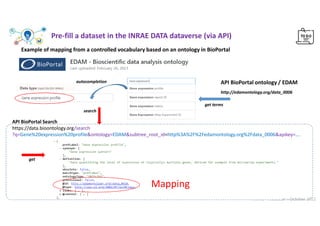
![INRAE - Indexator – October 2022
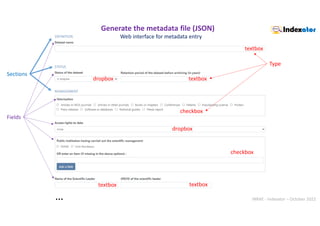
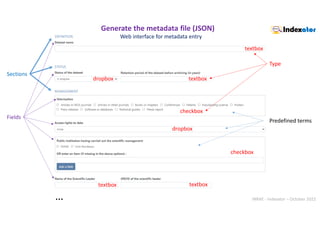
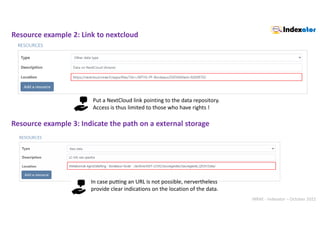
Web interface : autocompletion Example with
https://consultation.vocabulaires-ouverts.inrae.fr/api/
web/js/autocomplete/VOvocab.js
.
Terminology definition file
keywords = [
'data', 'report','simulation', 'model', 'image','script',
'omics', 'statistic','scientific', 'research', ‘document',
'experiment','video', 'spatial', 'instrument'
]
VOvocab=[];
get_terms_from_voinrae(keywords,'VOvocab')
Choose from 405 terms
autocompletion](https://image.slidesharecdn.com/indexatoroct2022-221010102047-bdbb412b/85/Indexator_oct2022-pdf-29-320.jpg)

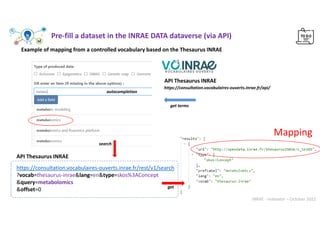
![INRAE - Indexator – October 2022
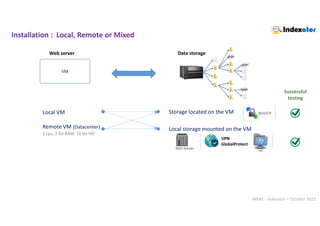
scan
[ncloud]
type = webdav
url = https://nextcloud.inrae.fr/remote.php/webdav/
vendor = nextcloud
user = XXXXX
Pass = XXXXX
rclone mount ncloud:MTH2-PF-Bordeaux/DATA/ /mnt/ncloud/
--allow-other --vfs-cache-mode minimal
--read-only --no-checksum --no-modtime
--daemon --daemon-wait 15s
https://pmb-bordeaux.fr/ncloud/search
https://nextcloud.inrae.fr/apps/files/?dir=/MTH2-PF-Bordeaux/DATA](https://image.slidesharecdn.com/indexatoroct2022-221010102047-bdbb412b/85/Indexator_oct2022-pdf-36-320.jpg)


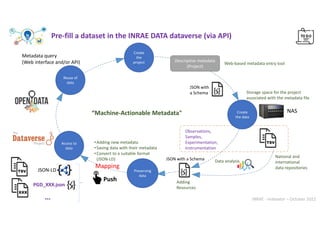



This document discusses the implementation of a Data Management Plan (DMP) for effective metadata management and data storage at INRAE. It emphasizes the importance of creating data repositories that employ JSON formatted metadata files, which are accessible via a web interface, to enhance organization and searchability of research data. The approach aims to be flexible, allowing diverse domains to utilize controlled vocabularies while standardizing best practices for metadata entry and storage.















































