Downloaded 27 times


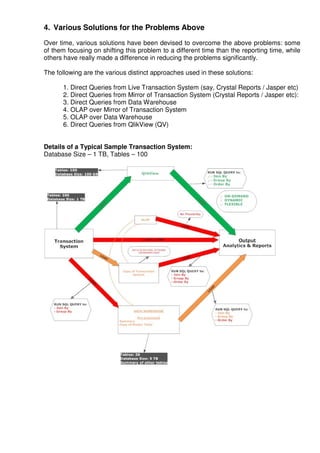



This document compares various analytics and reporting architectures for generating reports from transaction systems. It discusses 6 approaches: 1) direct queries from the live transaction system, 2) direct queries from a mirror of the transaction system, 3) direct queries from a data warehouse, 4) OLAP over a mirror, 5) OLAP over a data warehouse, and 6) direct queries from QlikView. Each approach is evaluated in terms of potential response time and flexibility for ad-hoc reporting. QlikView is identified as a potentially quick, flexible and cost-effective solution by extracting and compressing data into QVD files for in-memory querying.































![]project-open[ Reporting & Indicators Options](https://cdn.slidesharecdn.com/ss_thumbnails/po-dev-reporting-options-101006-101013110238-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![]project-open[ Reporting & Indicators Options](https://cdn.slidesharecdn.com/ss_thumbnails/po-dev-reporting-options-101006-101013103725-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![]po[ Developers: Reporting, Indicators & Dashboards](https://cdn.slidesharecdn.com/ss_thumbnails/po-dev-reporting-options-130406-130430111251-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

































