Downloaded 10 times
















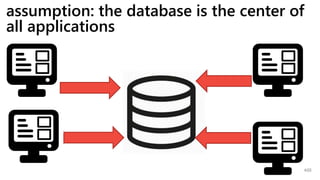

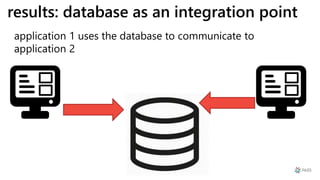

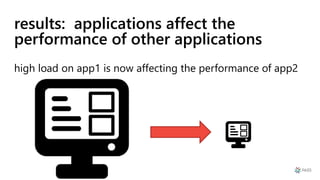

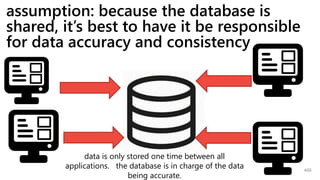




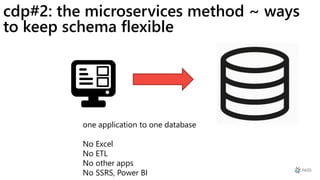
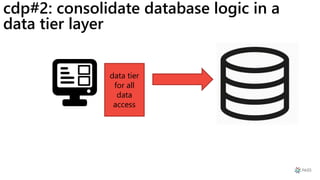
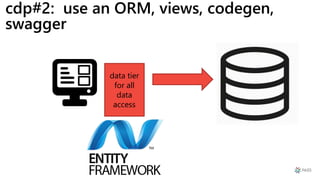
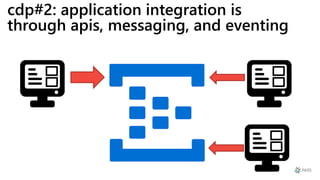

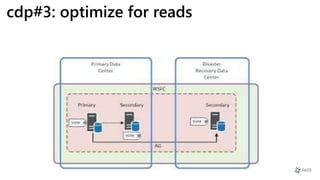





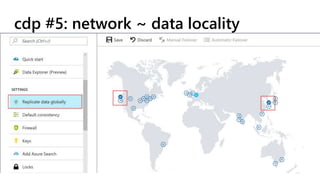



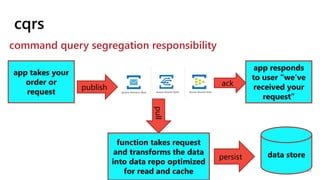


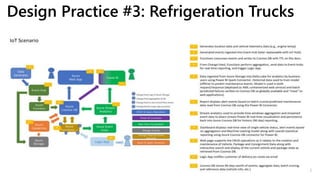




This document provides a summary of Ike Ellis's presentation on data modeling priorities and design patterns for transactional applications. The presentation discusses how data modeling priorities have changed from focusing on writes and normalization to emphasizing reads, flexibility, and performance. It outlines several current design priorities including optimizing the schema for reads, making it easy to change and discoverable, and designing for the network instead of the disk. The presentation concludes with practicing modeling data for example transactional applications like a blog, online store, and refrigeration trucks.












































![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)










































