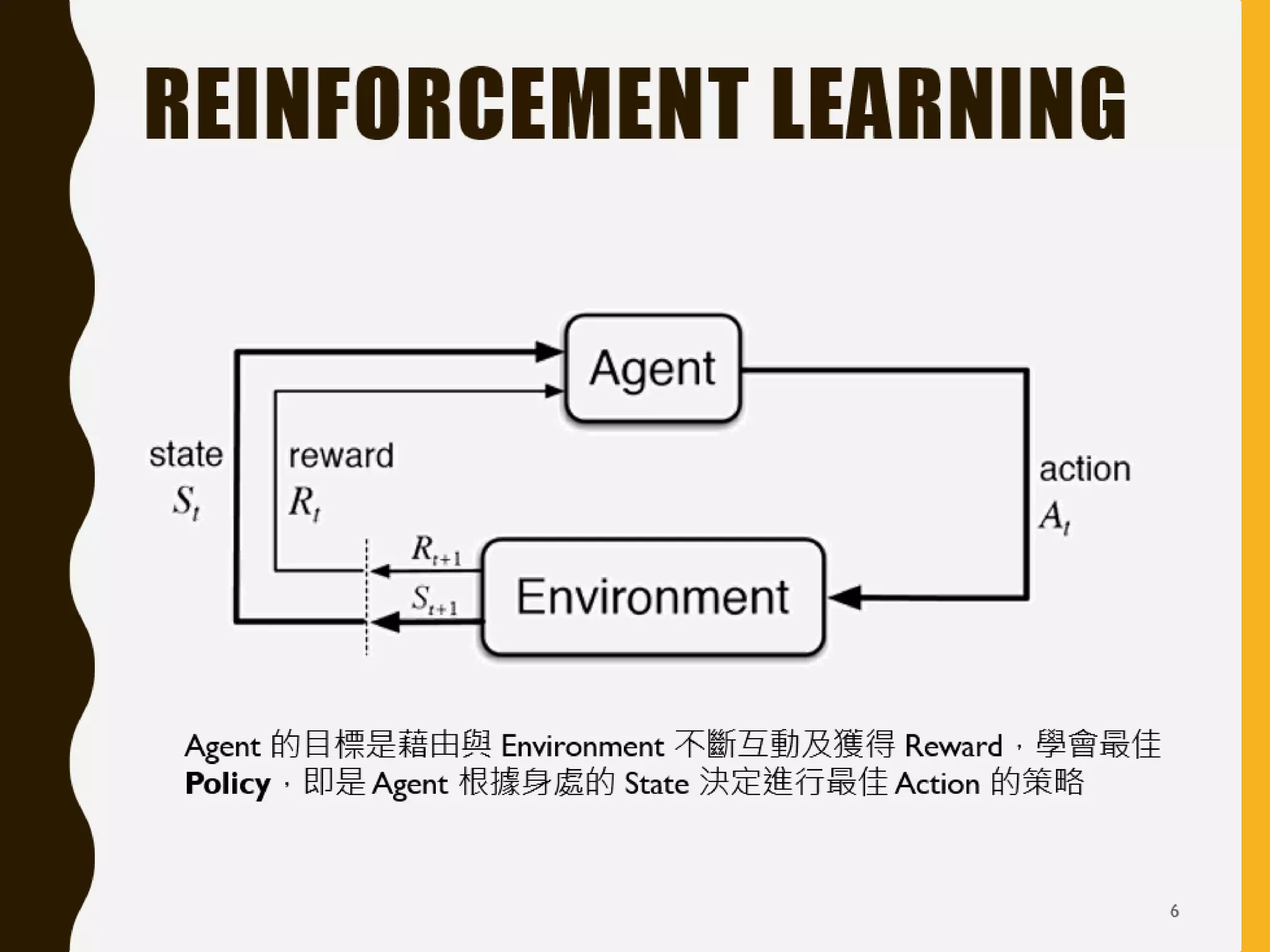
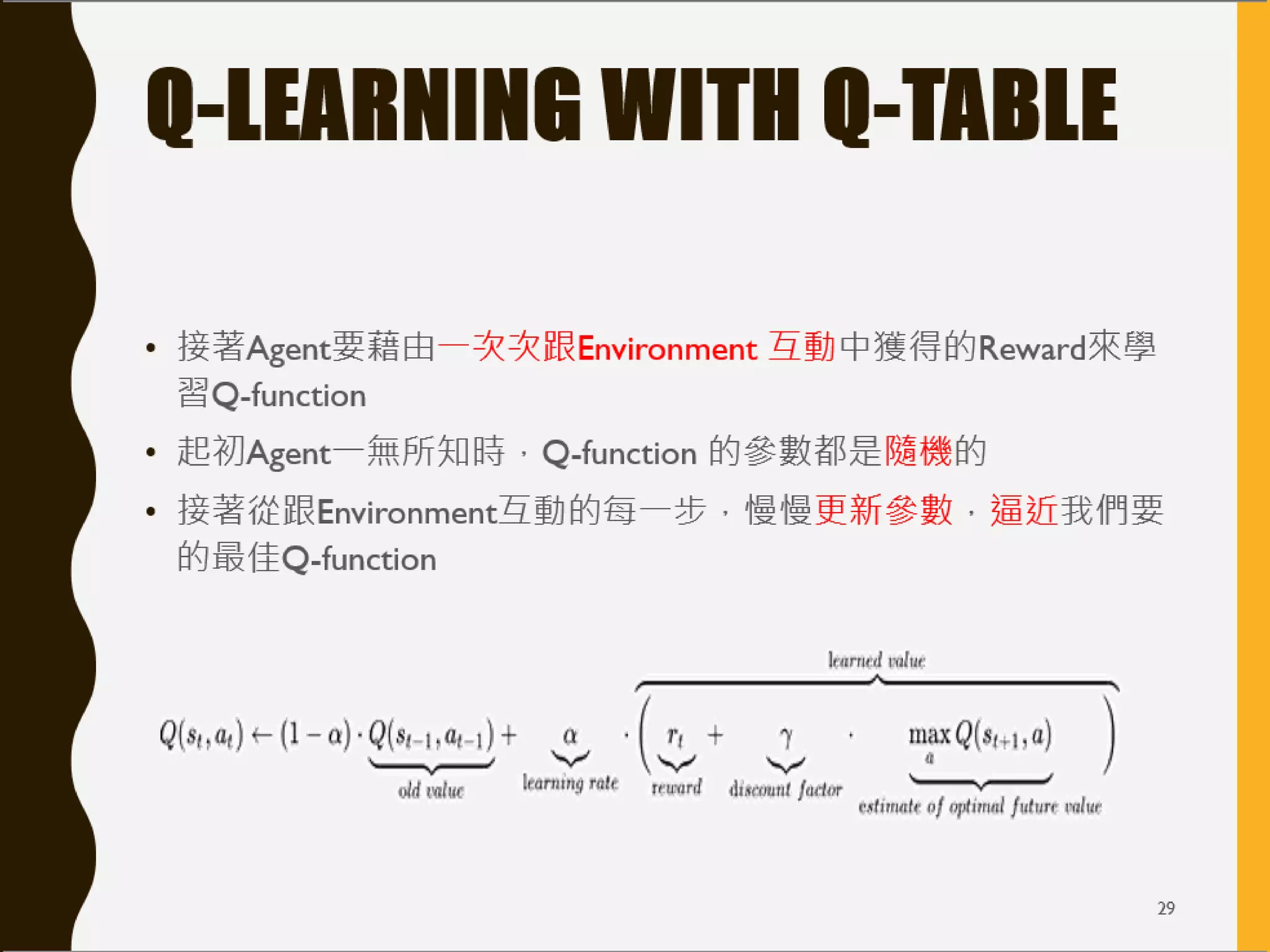
本文讨论了强化学习的基本原理和应用,包括Q学习和深度Q网络(DQN)。强调了强化学习通过奖励和惩罚机制来学习最佳决策策略,特别是在与环境交互中的探索与利用平衡。此外,介绍了OpenAI Gym和多种模拟环境供研究和实践使用。