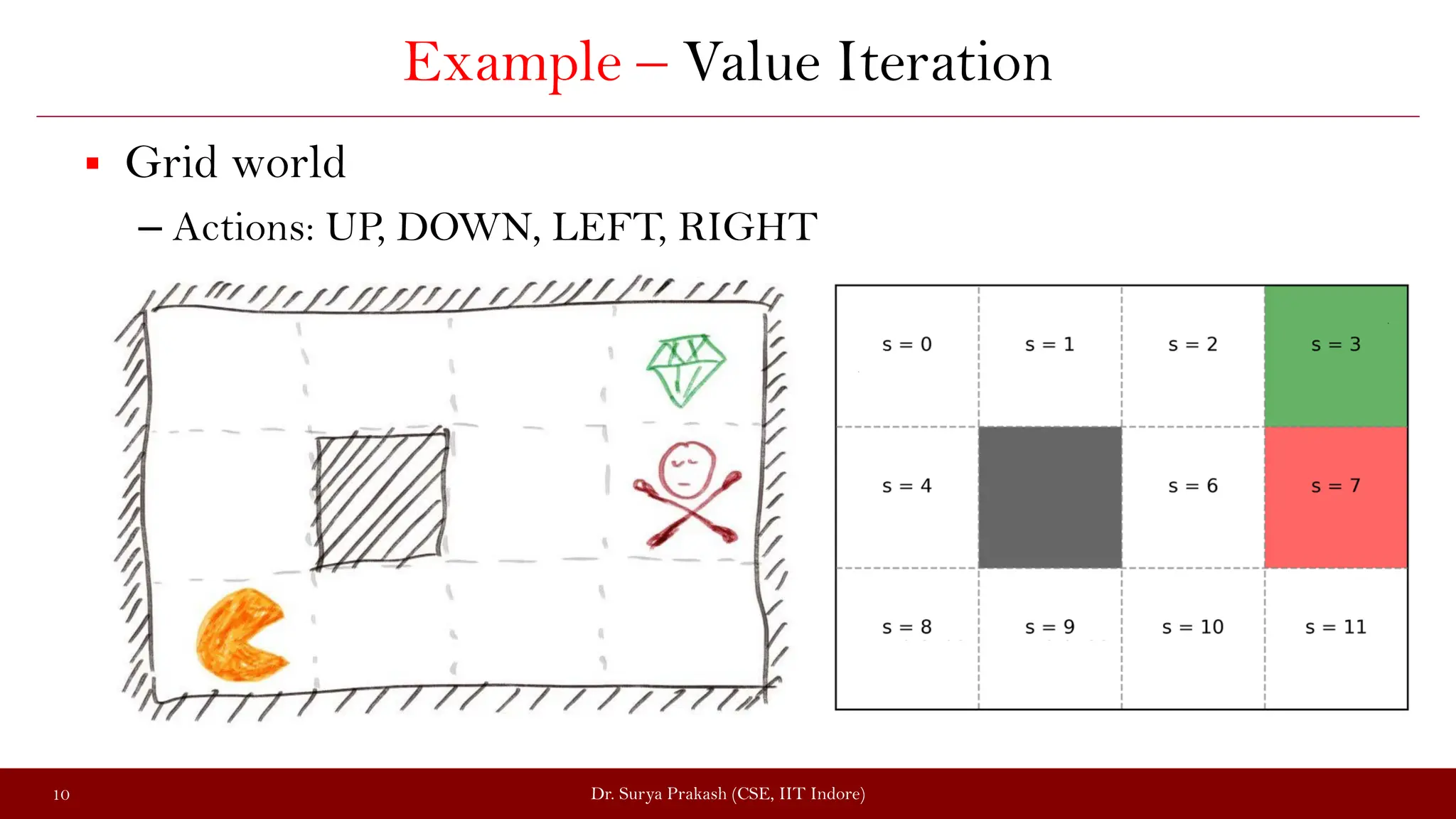
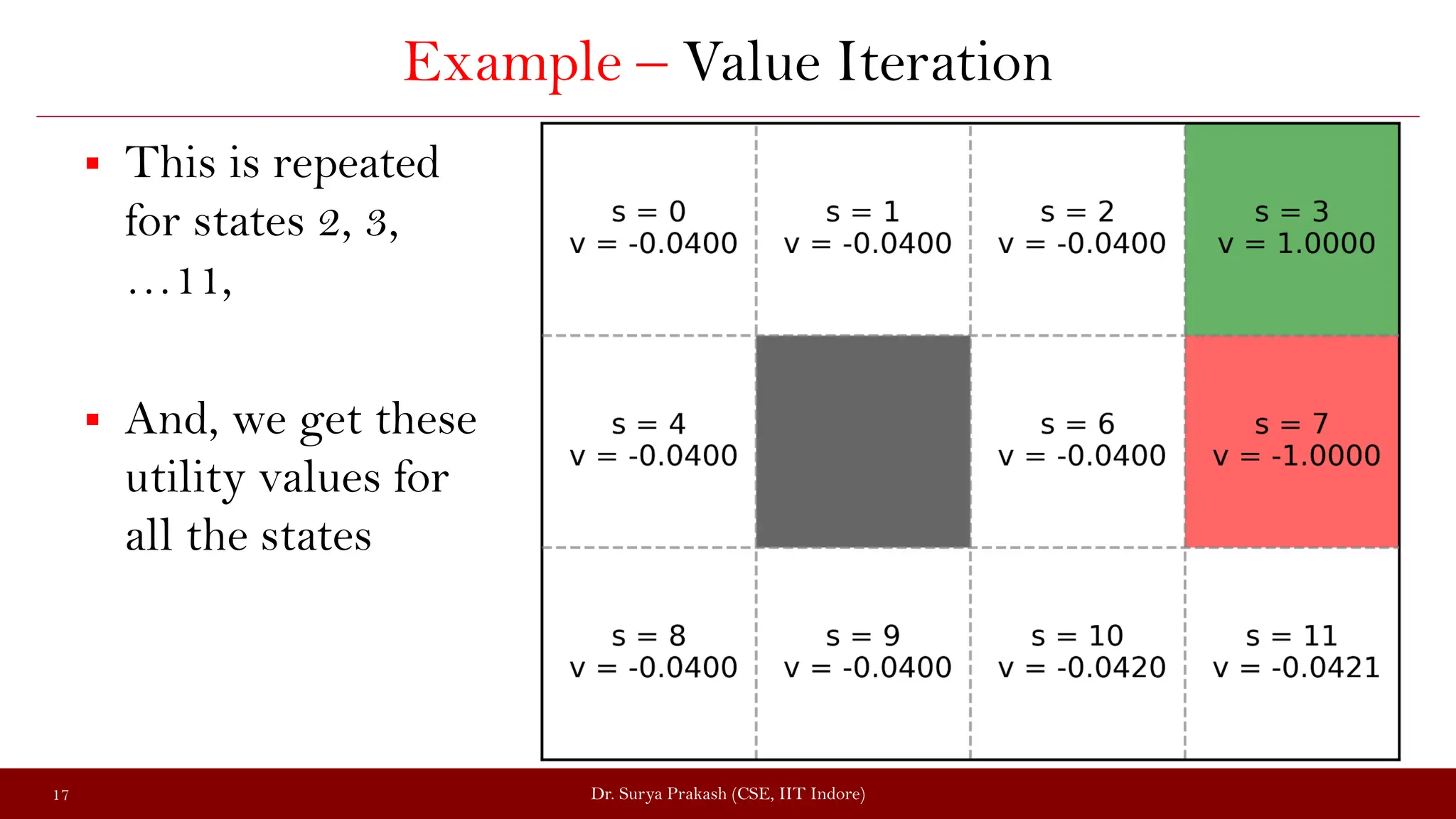
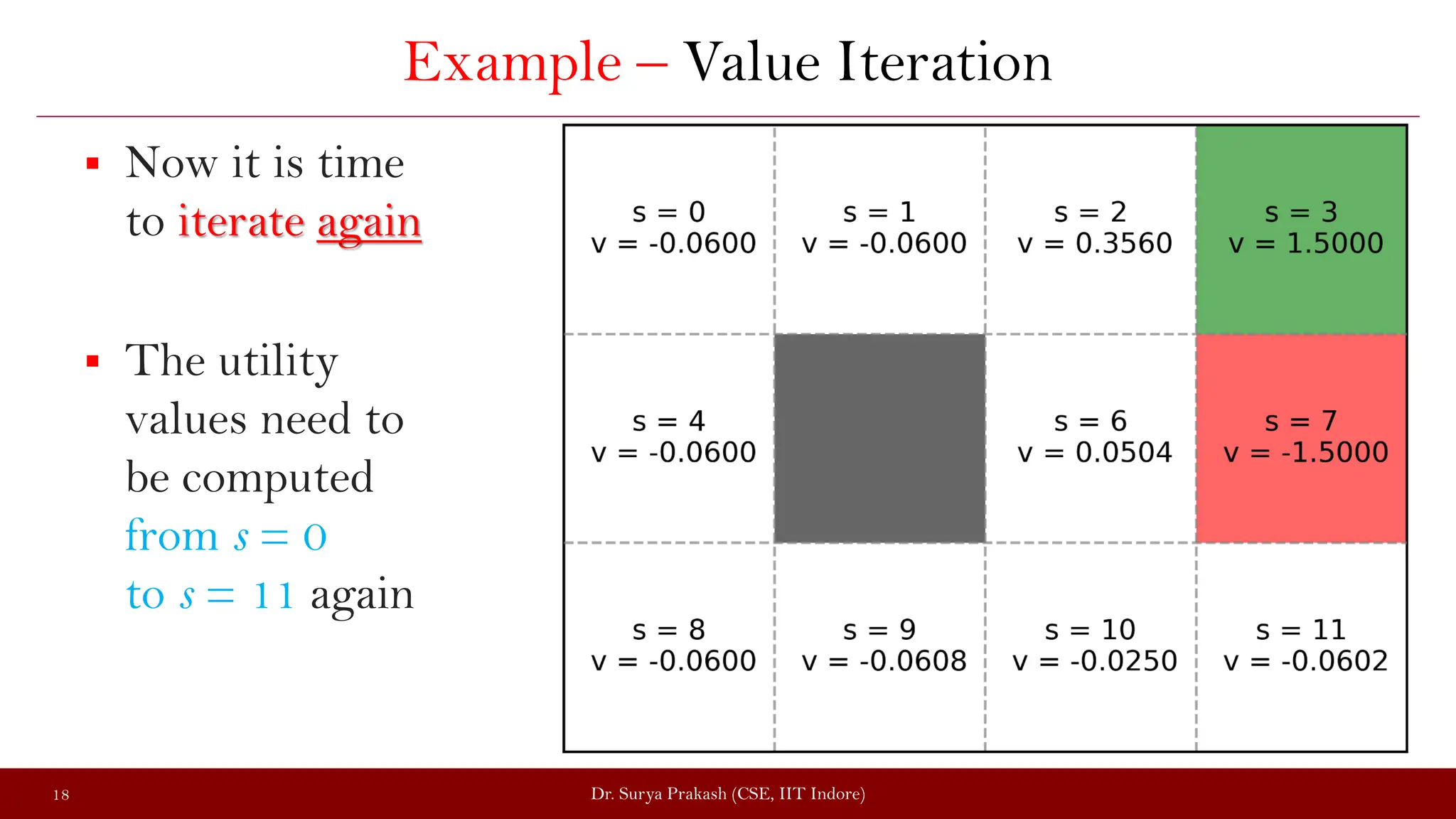
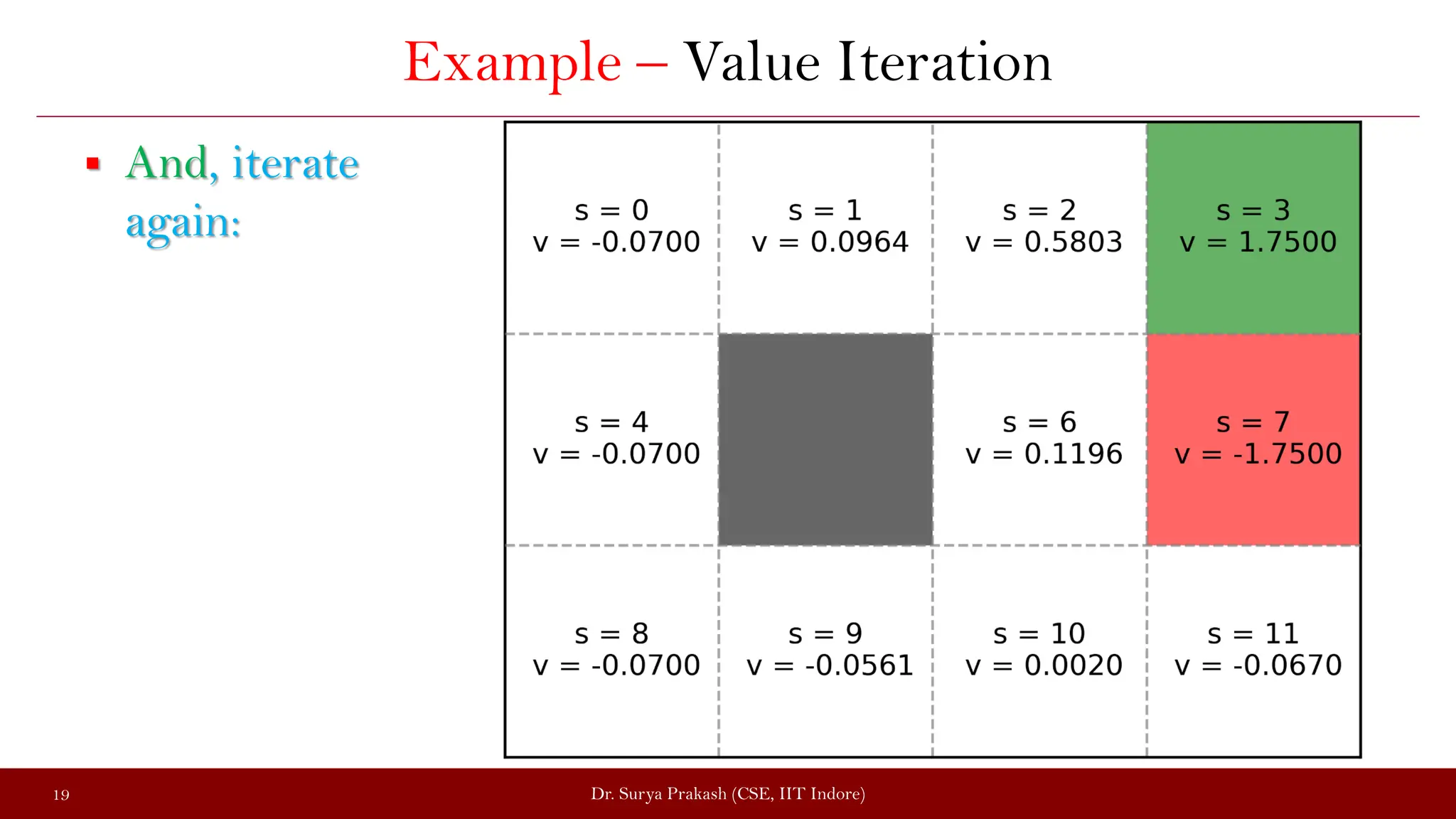
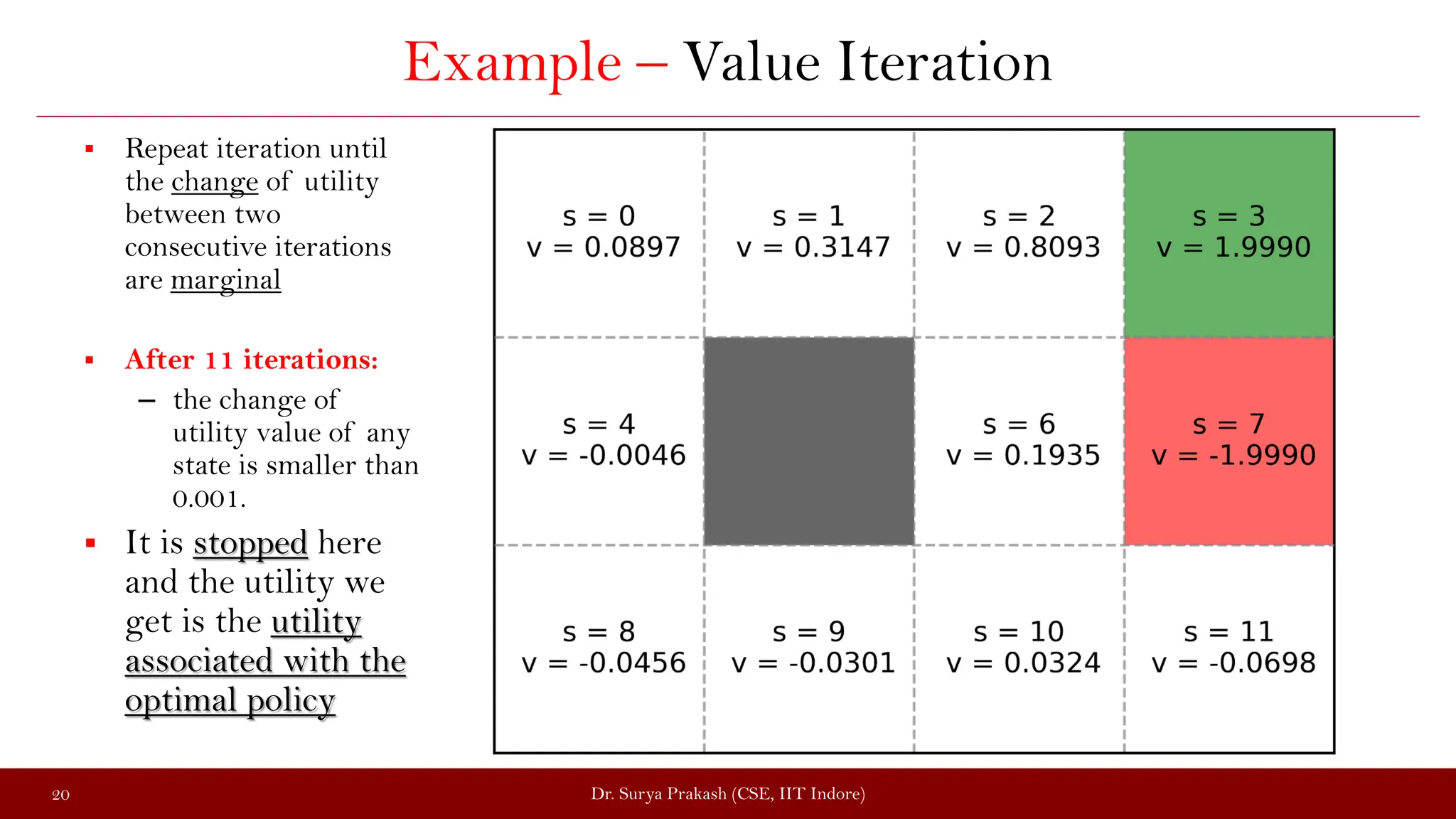
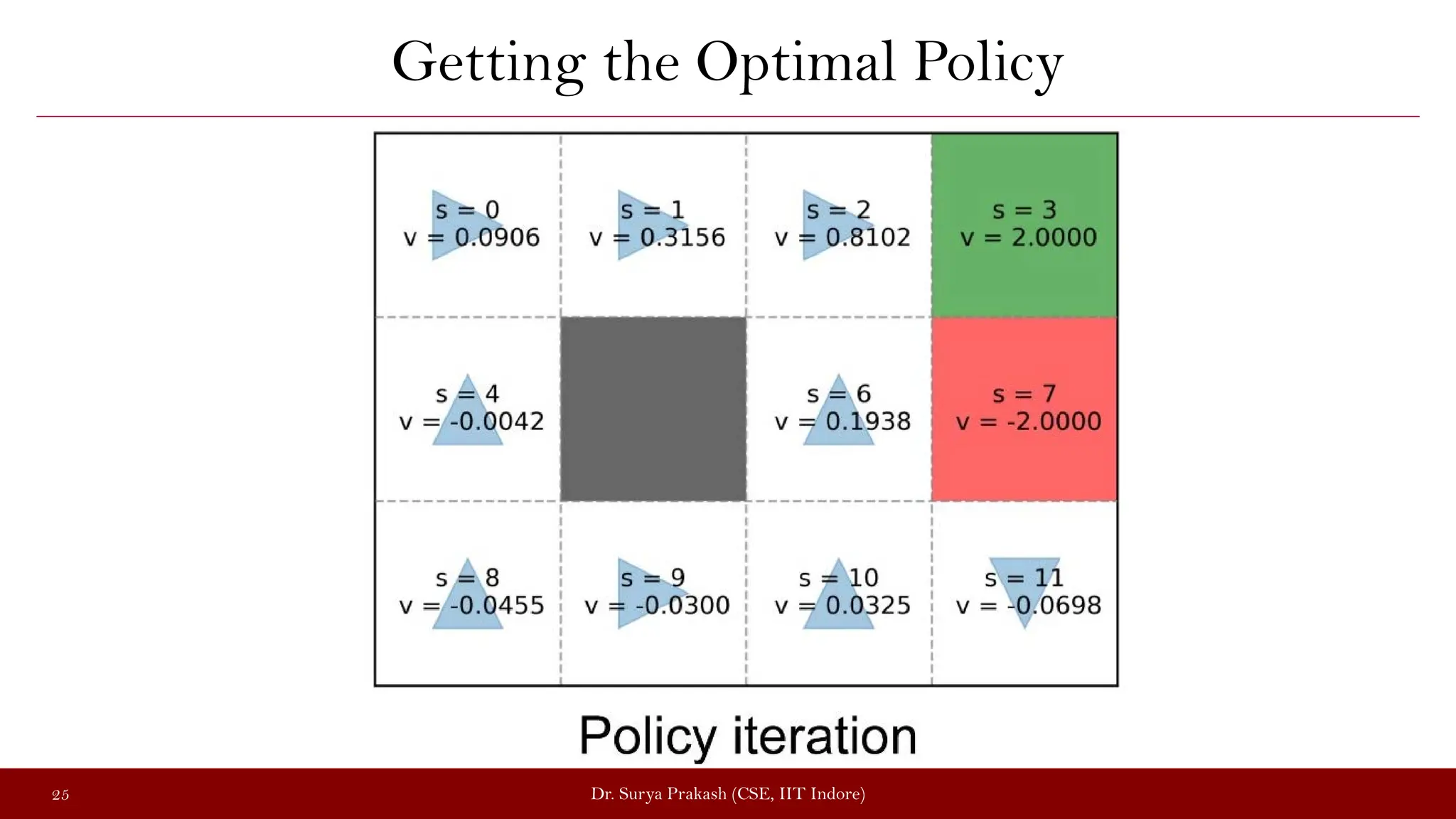
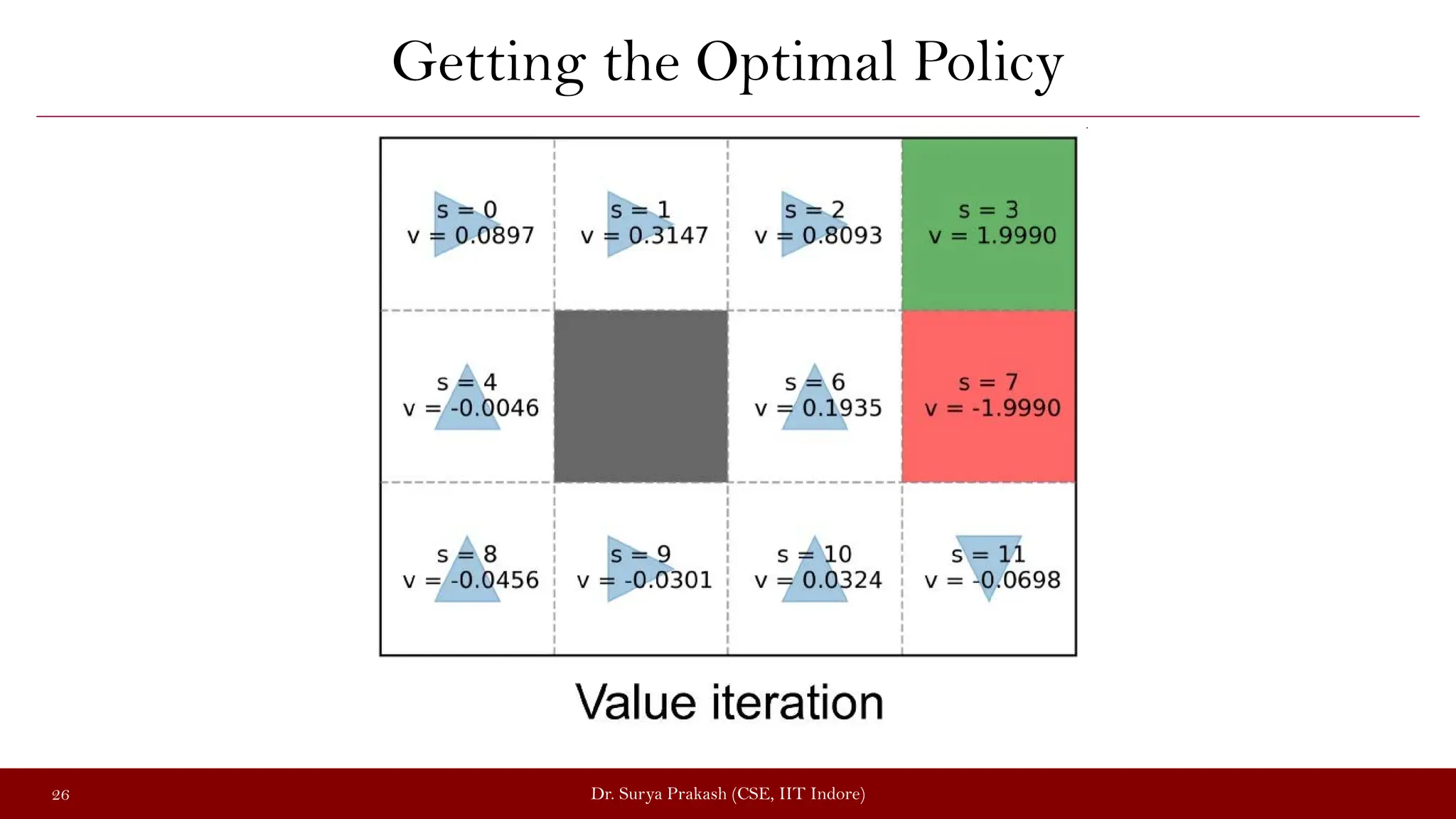
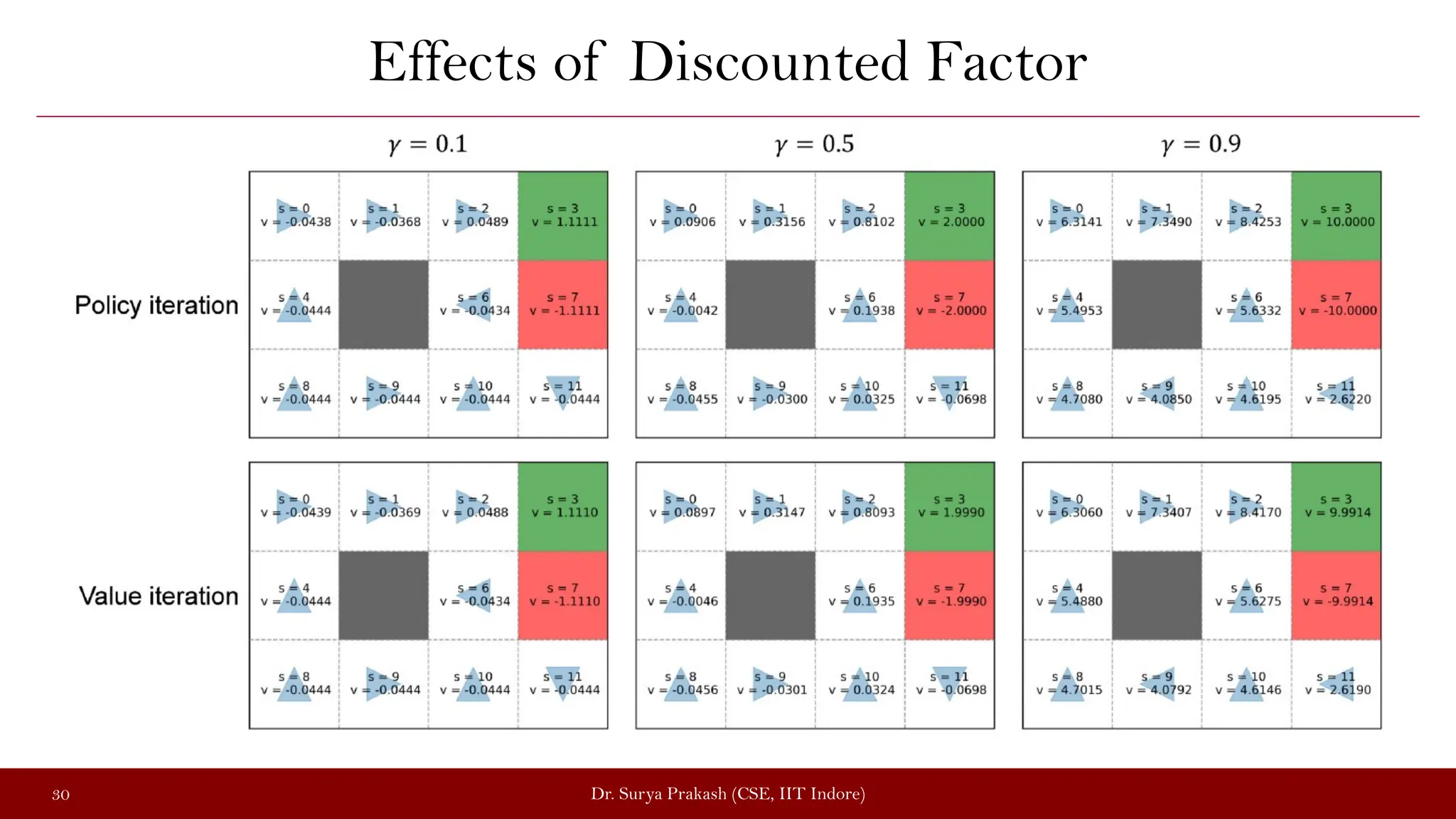
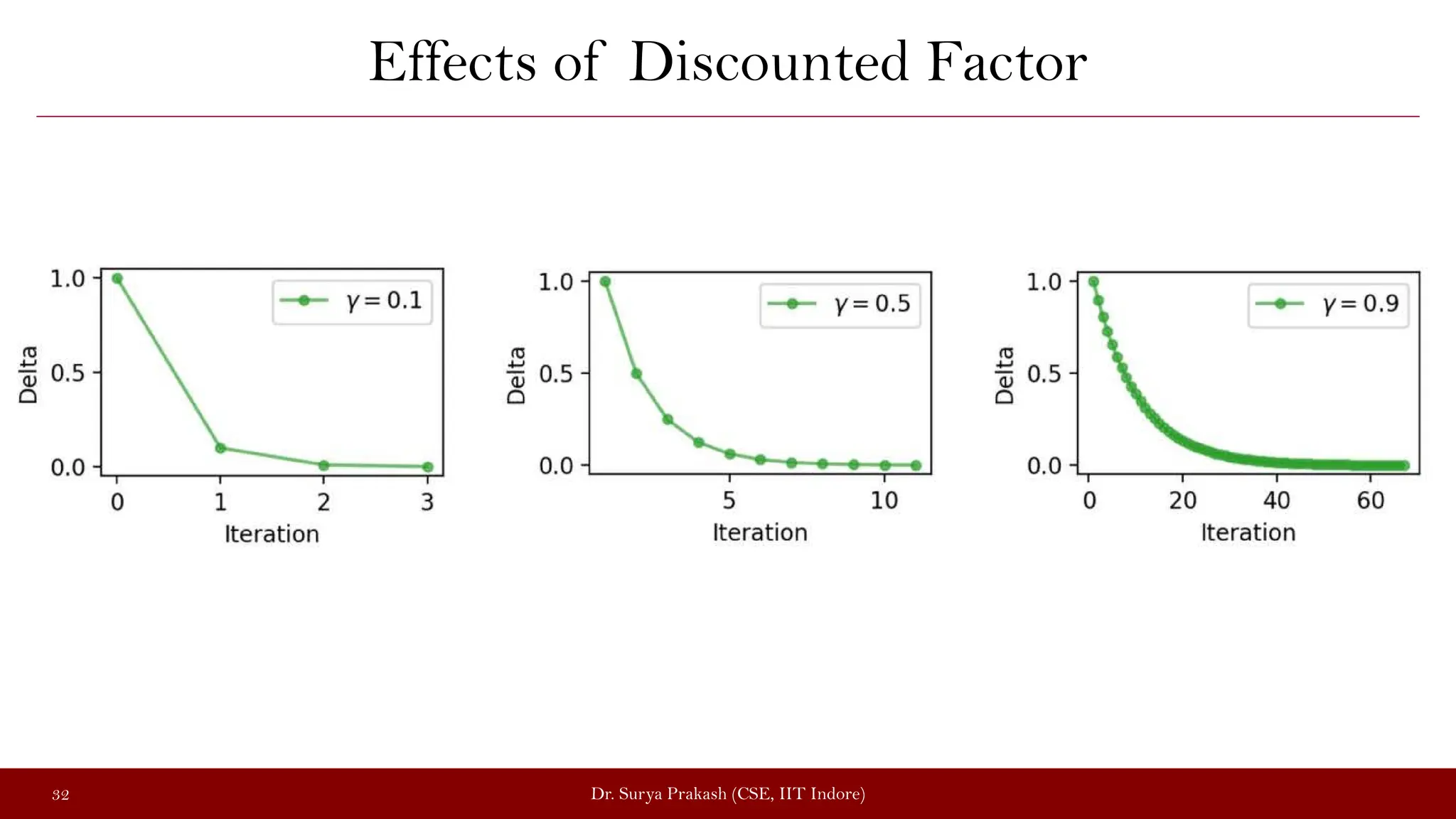
The document discusses the value iteration algorithm in the context of Markov Decision Processes (MDPs), comparing it with the policy iteration algorithm. It outlines how value iteration combines policy evaluation and improvement through iterative processes, using examples such as a grid world with stochastic elements. Additionally, it emphasizes the challenges and applications of reinforcement learning when transitioning from MDPs to real-world scenarios.