Downloaded 95 times




![Character Classes
• [ starts a character class
• ] ends a character class
– Any of the characters within [ ] will be matched
Note: ranges like [G-V] (letters g though v) or [1-10] (number 1 through
10) also work.
Example: hnaeyesdtlaeck
• [nedl] will result in “hnaeyesdtlaeck”
Example: Do you do SEO or SEM?
• SE[OM] will result in “Do you do SEO or SEM?”
COPYRIGHT 2014 CATALYST. ALL RIGHTS RESERVED. APRIL 29, 2014 | PAGE 7](https://image.slidesharecdn.com/regular-expressions-ci-140429091221-phpapp02/85/Regular-Expressions-for-Regular-Joes-and-SEOs-7-320.jpg)






![Lookarounds
COPYRIGHT 2014 CATALYST. ALL RIGHTS RESERVED. APRIL 29, 2014 | PAGE 16
• Positive Lookaheads will match a group after the main pattern
without actually including it in the result. The expression is
(?=)
Example: 1in 250px 2in 3em 40px
– [0-9]+(?=px) will result in “1in 250px 2in 3em 40px”
Everything WITH “px”
• A Negative Lookahead is used to specify a group that won’t
be matched after the main pattern. The expression is (?!)
Example: 1in 250px 2in 3em 40px
– [0-9]+(?!em) will result in “1in 250px 2in 3em 40px”
Everything BUT “em”](https://image.slidesharecdn.com/regular-expressions-ci-140429091221-phpapp02/85/Regular-Expressions-for-Regular-Joes-and-SEOs-16-320.jpg)


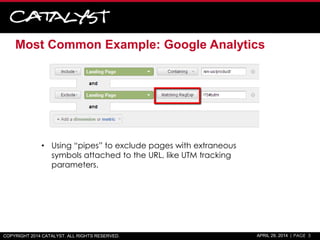
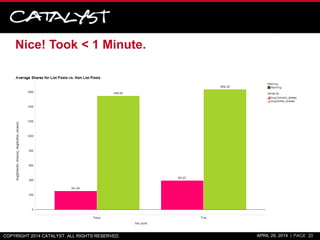
![Solution #1: SEO Tools for Excel Add-on w/ RegEx
• Is the post title a question?
– =RegexpIsMatch(A2,"?$")
• Is the post a listacle/list post?
– =RegexpIsMatch(A2,"^[0-9]*s|^[0-9],[0-9]*s")
• Extract publishing year from URL
– =RegexpFind(D2,"https?://(?:www.)?mashable.com/([0-
9]{4})/.+","$1")
• Presence of a year in the title
– =IFERROR(RegexpFind(A40,"([0-9]{4})","$1"),“N/A")
COPYRIGHT 2014 CATALYST. ALL RIGHTS RESERVED. APRIL 29, 2014 | PAGE 19](https://image.slidesharecdn.com/regular-expressions-ci-140429091221-phpapp02/85/Regular-Expressions-for-Regular-Joes-and-SEOs-19-320.jpg)




![Problem #4
• I want to quickly change a long list of keywords
into the exact match format with the keyword
surrounded by brackets, [ ].
What’s the fastest way?
COPYRIGHT 2014 CATALYST. ALL RIGHTS RESERVED. APRIL 29, 2014 | PAGE 26](https://image.slidesharecdn.com/regular-expressions-ci-140429091221-phpapp02/85/Regular-Expressions-for-Regular-Joes-and-SEOs-26-320.jpg)
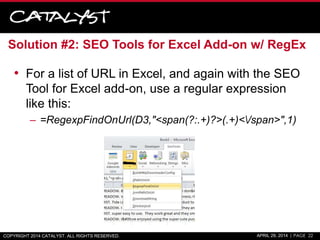
![Solution #4: Notepad++ Example
1. Copy a column of keywords
from Excel into Notepad++
2. Control + F and switch to the
“Replace” tab.
3. Switch the “Search Mode” to
“Regular Expression”
4. Enter ^ in the “Find what” field
and [ in the “Replace with” field.
5. Hit the “Replace All” button.
6. Then, enter $ in the “Find what”
field and ] in the “Replace with”
field.
7. Again, hit the “Replace All”
button.
COPYRIGHT 2014 CATALYST. ALL RIGHTS RESERVED. APRIL 29, 2014 | PAGE 27](https://image.slidesharecdn.com/regular-expressions-ci-140429091221-phpapp02/85/Regular-Expressions-for-Regular-Joes-and-SEOs-27-320.jpg)

![A Solution: Calculated Column with ~= Operator
• Create a calculated column with an expression
like the below:
If([keyword]~="unstopable|unstopables|unstoppable|unstoppables|inst
opable|instopabales|[ui]nstop[a-z]+?b[a-z]+?s?|(scent booster)|(scent
boosters)",true,false)
– This should find spellings/mis-spellings of Downy Unstopables
COPYRIGHT 2014 CATALYST. ALL RIGHTS RESERVED. APRIL 29, 2014 | PAGE 29](https://image.slidesharecdn.com/regular-expressions-ci-140429091221-phpapp02/85/Regular-Expressions-for-Regular-Joes-and-SEOs-29-320.jpg)
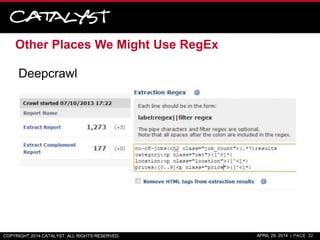
![Other Places We Might Use RegEx
.htaccess
– Redirect a set of URLs matching a certain pattern to a new URL
pattern:
Example:
RewriteRule ^/dir/index.php?id=(0-9+).htm$ file-$1 [L]
Screaming Frog
– URL Rewriting: RegEx Replace
– Spider Include/Exclude URLs
COPYRIGHT 2014 CATALYST. ALL RIGHTS RESERVED. APRIL 29, 2014 | PAGE 31](https://image.slidesharecdn.com/regular-expressions-ci-140429091221-phpapp02/85/Regular-Expressions-for-Regular-Joes-and-SEOs-31-320.jpg)



The document provides an overview of regular expressions (regex) and their applications, particularly for SEOs, highlighting their ability to match text patterns for various use cases. It explains regex basics, including anchors, character classes, special characters, quantifiers, groups, and practical applications in tools such as Google Analytics and Excel. Additionally, it includes various examples and solutions to specific problems encountered when using regex.



![[LondonSEO 2020] BigQuery & SQL for SEOs](https://cdn.slidesharecdn.com/ss_thumbnails/abuali-londonseomeetup-200115205008-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[BrightonSEO 2022] Unlocking the Hidden Potential of Product Listing Pages](https://cdn.slidesharecdn.com/ss_thumbnails/abuali-brightonseo2022slides-221003112121-157abb52-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![Buy Twitter Ads Account [ X Verified & Ready for Campaigns].docx](https://cdn.slidesharecdn.com/ss_thumbnails/buytwitteradsaccountxverifiedreadyforcampaigns-260114201150-9fcc4249-thumbnail.jpg?width=640&height=640&fit=bounds)

















