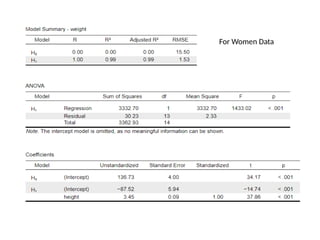
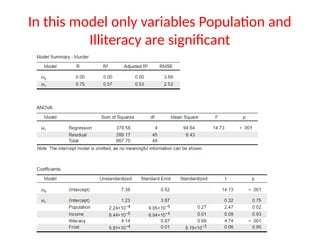
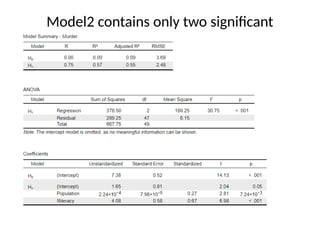
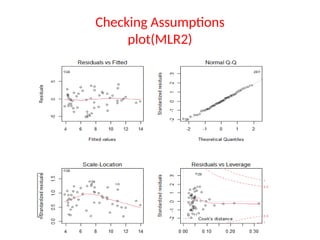
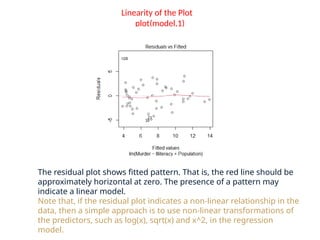
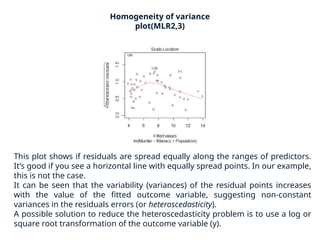
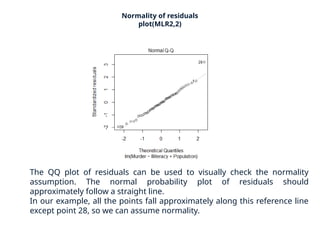
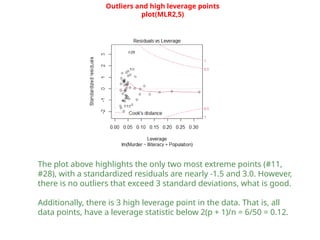
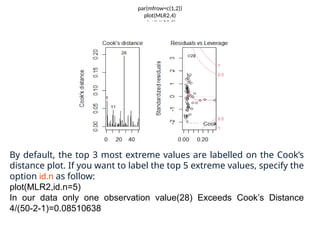
The document provides a comprehensive overview of regression analysis, including definitions of dependent and independent variables, and details on simple and multiple linear regression models. It discusses the statistical assumptions necessary for ordinary least squares (OLS) regression, the interpretation of regression coefficients, and methods for checking model assumptions like linearity, normality, and homoscedasticity. Additionally, it outlines how to identify outliers, high leverage points, and influential values in regression analysis.