Downloaded 33 times






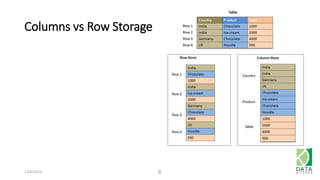
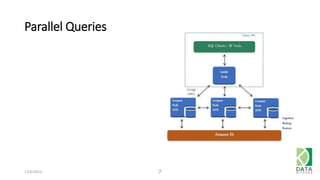
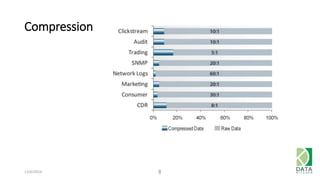



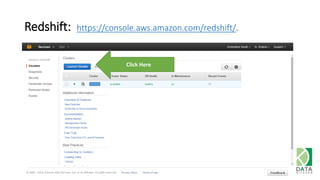

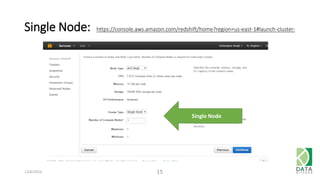


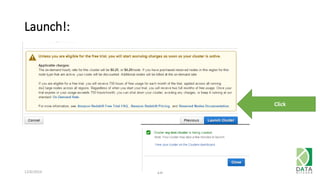
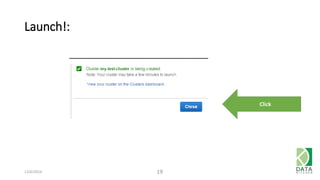




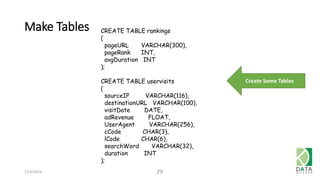



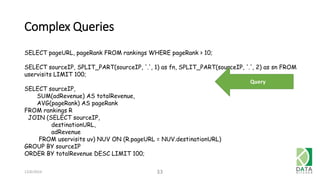
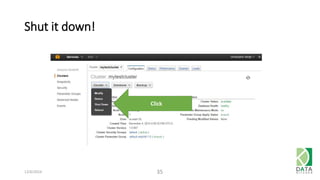
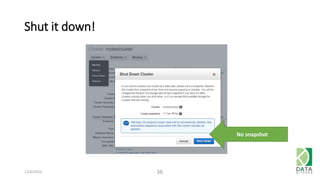
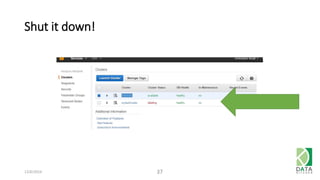


The document outlines an agenda for a workshop on Amazon Redshift conducted on December 6, 2014, covering topics such as the advantages of analytic databases, specific features of Redshift, and hands-on exercises for loading data and performing queries. Participants are guided on the necessary preparations, including AWS account setup and SQL Workbench installation, to effectively use Redshift. The session concludes with instructions on shutting down the database and resources for further learning.














































































