Downloaded 10 times






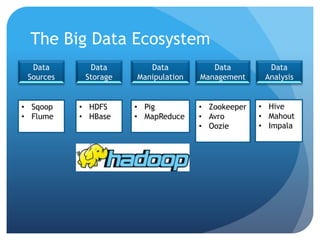

![Example : Log File Processing
xxx.16.23.133 - - [15/Jul/2013:04:03:01 -0400] "POST /update-channels HTTP/1.1" 500 378 "-" "Zend_Http_Client" 53051 65921 617
- - - - [15/Jul/2013:04:03:02 -0400] "GET /server-status?auto HTTP/1.1" 200 411 "-" "collectd/5.1.0" 544 94 590
xxx.16.23.133 - - [15/Jul/2013:04:04:00 -0400] "POST /update-channels HTTP/1.1" 200 104 "-" "Zend_Http_Client" 617786 4587 360
- - - [15/Jul/2013:04:04:02 -0400] "GET /server-status?auto HTTP/1.1" 200 411 "-" "collectd/5.1.0" 568 94 590
- - - [15/Jul/2013:04:05:02 -0400] "GET /server-status?auto HTTP/1.1" 200 412 "-" "collectd/5.1.0" 560 94 591
xxx.16.23.70 - - [15/Jul/2013:04:05:09 -0400] "POST /fetch-channels HTTP/1.1" 200 3718 "-" "-" 452811 536 3975
xxx.16.23.70 - - [15/Jul/2013:04:05:10 -0400] "POST /fetch-channels HTTP/1.1" 200 6598 "-" "-" 333213 536 6855
xxx.16.23.70 - - [15/Jul/2013:04:05:11 -0400] "POST /fetch-channels HTTP/1.1" 200 5533 "-" "-" 282445 536 5790
xxx.16.23.70 - - [15/Jul/2013:04:05:12 -0400] "POST /fetch-channels HTTP/1.1" 200 8266 "-" "-" 462575 536 8542
xxx.16.23.70 - - [15/Jul/2013:04:05:12 -0400] "POST /fetch-channels HTTP/1.1" 200 42640 "-" "-" 1773203 536 42916](https://image.slidesharecdn.com/codecamp2014-ternent-bigdata-140323210744-phpapp01/85/Intro-to-Big-Data-Orlando-Code-Camp-2014-10-320.jpg)
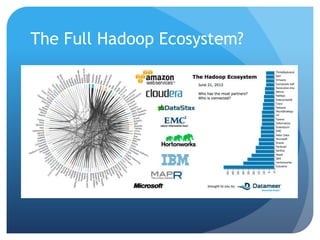
![Example : Log File Processing
A = LOAD '/Users/jternent/Documents/logs/api*' USING TextLoader as (line:chararray);
B = FOREACH A GENERATE FLATTEN(
(tuple(chararray, chararray, chararray, chararray, chararray, int, int, chararray, chararray, int,
int, int))
REGEX_EXTRACT_ALL(line,'^(S+) (S+) (S+) [([w:/]+s[+-]d{4})] "(.+?)" (S+) (S+)
"([^"]*)" "([^"]*)" (d+) (d+) (d+)'))
as (forwarded_ip:chararray, rem_log:chararray,rem_user:chararray, ts:chararray,
req_url:chararray, result:int, resp_size:int, referrer:chararray, user_agent:chararray,
svc_time:int, rec_bytes:int, resp_bytes:int);
B1 = FILTER B BY ts IS NOT NULL;
B2 = FILTER B BY req_url MATCHES '.*[fetch|update].*';
B3 = FOREACH B2 GENERATE *, REGEX_EXTRACT(req_url, '^w+ /(S+)[?]* S+',1) as req;
C = FOREACH B3 GENERATE forwarded_ip, GetMonth(ToDate(ts,'d/MMM/yyyy:HH:mm:ss Z')) as
month, GetDay(ToDate(ts,'d/MMM/yyyy:HH:mm:ss Z')) as day,
GetHour(ToDate(ts,'d/MMM/yyyy:HH:mm:ss Z')) as hour, req, result, svc_time;
D = GROUP C BY (month, day, hour, req, result);
E = FOREACH D GENERATE flatten(group), MAX(C.svc_time) as max, MIN(C.svc_time) as min,
COUNT(C) as count;
STORE E INTO '/Users/jternent/Documents/logs/ezy-logs-output' USING PigStorage](https://image.slidesharecdn.com/codecamp2014-ternent-bigdata-140323210744-phpapp01/85/Intro-to-Big-Data-Orlando-Code-Camp-2014-11-320.jpg)




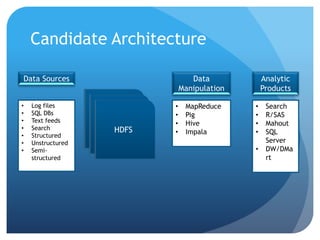
![Return to SQL
Many SQL dialects are being/have been ported to
Hadoop
Hive : Create DDL Tables on top of HDFS structures
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^]*) ([^]*) ([^]*) (-|[^]*]) ([^
"]*|"[^"]*") (-|[0-9]*) (-|[0-9]*)(?: ([^ "]*|".*") ([^
"]*|".*"))?"
)
STORED AS TEXTFILE;
SELECT host, COUNT(*)
FROM apachelog
GROUP BY host;](https://image.slidesharecdn.com/codecamp2014-ternent-bigdata-140323210744-phpapp01/85/Intro-to-Big-Data-Orlando-Code-Camp-2014-17-320.jpg)
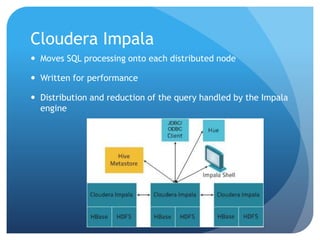





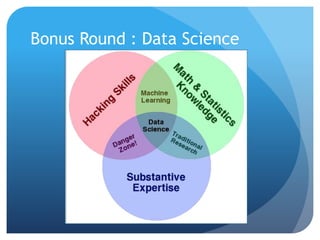


This document provides an overview of big data concepts and the Hadoop ecosystem. It discusses the 3-4 V's model of big data, defines Hadoop as an implementation of Google's MapReduce framework, and outlines the components of the Hadoop ecosystem including HDFS, MapReduce, Pig, Hive, HBase and Impala. It also provides examples of log file processing using Pig Latin and discusses scaling analytics to big data through tools like Mahout, ElasticSearch and Kibana.



































































