Downloaded 48 times






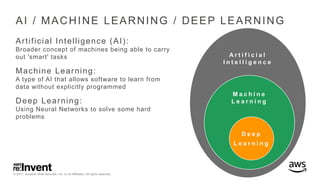


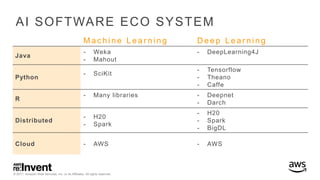
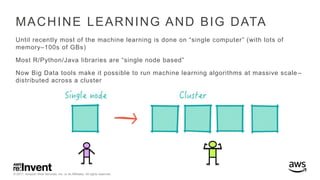







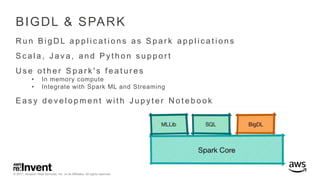
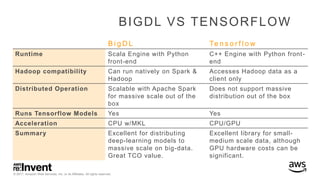





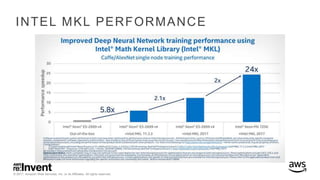








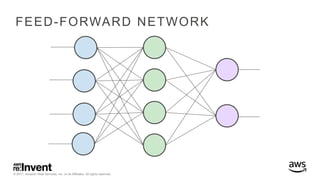

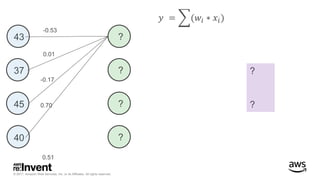
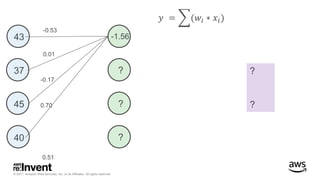
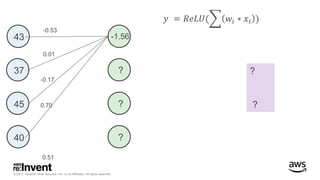
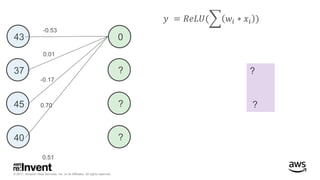
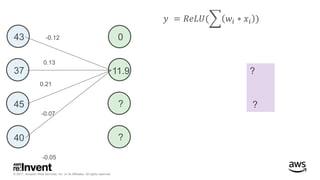
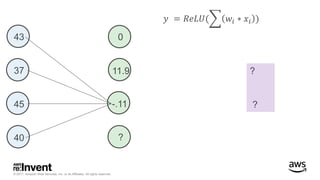
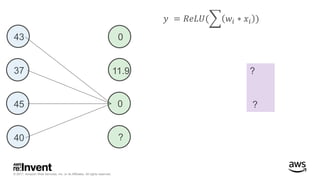
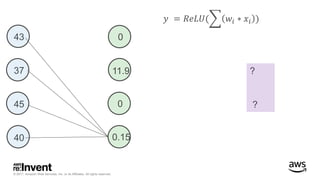
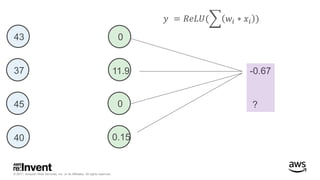
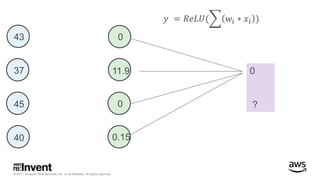
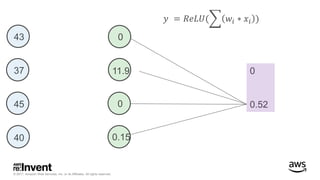
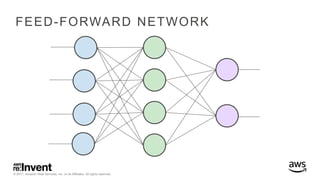



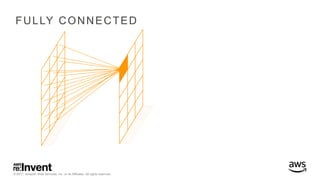
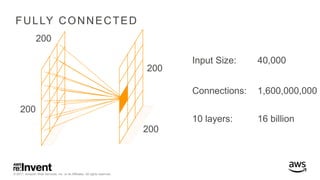

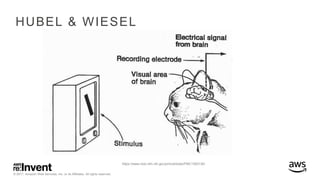
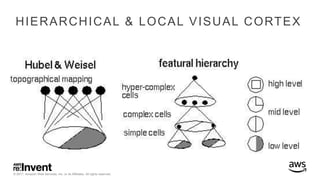
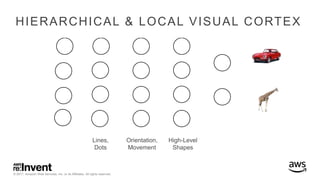

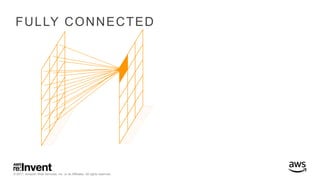
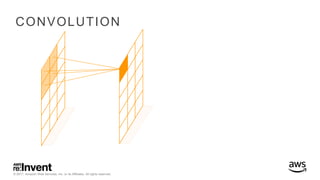
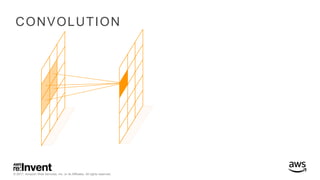
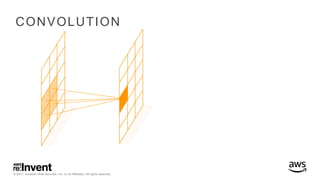
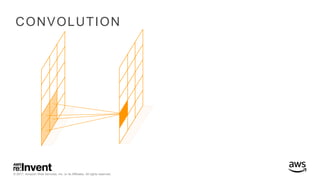
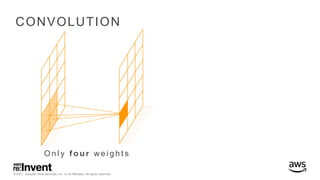

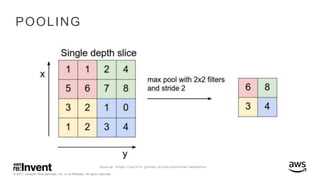
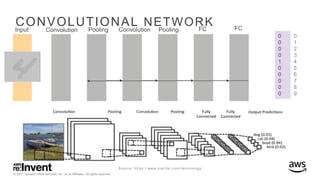
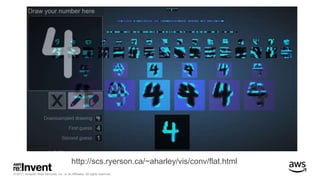











The document outlines large-scale deep learning using BigDL, a distributed deep learning library for Apache Spark. It discusses the evolution and applications of artificial intelligence, machine learning, and deep learning, emphasizing modern frameworks and tools like TensorFlow and Amazon Machine Learning. BigDL enables scalable deep learning operations while integrating with big data ecosystems, offering high performance and cost-effective solutions for processing large datasets.
























































