Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Atsushi Hayakawa
8,340 views
再発事象の解析をやってみる
Technology
◦
Design
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
TokyoR98_BeginnersSession1.pdf
by
kotora_0507
PDF
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PDF
マーケティングサイエンス徹底入門と実践Part2
by
宏喜 佐野
PDF
ggplot2によるグラフ化@HijiyamaR#2
by
nocchi_airport
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
三角関数の加法定理と関連公式(人間科学のための基礎数学 補足資料)
by
Masahiro Okano
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
TokyoR98_BeginnersSession1.pdf
by
kotora_0507
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
マーケティングサイエンス徹底入門と実践Part2
by
宏喜 佐野
ggplot2によるグラフ化@HijiyamaR#2
by
nocchi_airport
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
三角関数の加法定理と関連公式(人間科学のための基礎数学 補足資料)
by
Masahiro Okano
What's hot
PPTX
統計的検定と例数設計の基礎
by
Senshu University
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
適切な研究課題の設定が論文掲載の第一歩
by
英文校正エディテージ
PDF
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
PDF
三角関数(人間科学のための基礎数学)
by
Masahiro Okano
PDF
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
PDF
自動定理証明の紹介
by
Masahiro Sakai
PDF
時系列解析の使い方 - TokyoWebMining #17
by
horihorio
PDF
中断時系列分析の書き方
by
Shuhei Ichikawa
PDF
R Study Tokyo03
by
Yohei Sato
PPTX
データベース時代の疫学研究デザイン
by
Koichiro Gibo
PDF
正準相関分析
by
Akisato Kimura
PDF
[Tokyor08] Rによるデータサイエンス 第2部 第3章 対応分析
by
Yohei Sato
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PPTX
ADVENTURE_Mates Ver.0.5b データ生成
by
ADVENTURE Project
PDF
1 4.回帰分析と分散分析
by
logics-of-blue
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PPTX
2SAT(充足可能性問題)の解き方
by
Tsuneo Yoshioka
PDF
因果関係を時系列変化で分析
by
DaikiNagamine
統計的検定と例数設計の基礎
by
Senshu University
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
Stanコードの書き方 中級編
by
Hiroshi Shimizu
適切な研究課題の設定が論文掲載の第一歩
by
英文校正エディテージ
混合モデルを使って反復測定分散分析をする
by
Masaru Tokuoka
三角関数(人間科学のための基礎数学)
by
Masahiro Okano
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
by
hirokazutanaka
自動定理証明の紹介
by
Masahiro Sakai
時系列解析の使い方 - TokyoWebMining #17
by
horihorio
中断時系列分析の書き方
by
Shuhei Ichikawa
R Study Tokyo03
by
Yohei Sato
データベース時代の疫学研究デザイン
by
Koichiro Gibo
正準相関分析
by
Akisato Kimura
[Tokyor08] Rによるデータサイエンス 第2部 第3章 対応分析
by
Yohei Sato
バンディットアルゴリズム入門と実践
by
智之 村上
ADVENTURE_Mates Ver.0.5b データ生成
by
ADVENTURE Project
1 4.回帰分析と分散分析
by
logics-of-blue
統計的因果推論勉強会 第1回
by
Hikaru GOTO
2SAT(充足可能性問題)の解き方
by
Tsuneo Yoshioka
因果関係を時系列変化で分析
by
DaikiNagamine
Viewers also liked
PPTX
Zansa第12回資料 「ソーシャルゲームでは、データがユーザーを理解する!」
by
Shota Kubo
PPTX
121218 zansa13 for web
by
Zansa
PPTX
Zansa アト テクノロシ-ー業界の分析という仕事について http://zansa.info/materials-11.html
by
Zansa
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PPTX
Zansa0802
by
Yoshifumi Seki
PDF
【Zansa】第17回 ブートストラップ法入門
by
Zansa
PDF
ビジネスの現場のデータ分析における理想と現実
by
Takashi J OZAKI
PDF
社会の意見のダイナミクスを物理モデルとして考えてみる
by
takeshi0406
PDF
幾何を使った統計のはなし
by
Toru Imai
PDF
PythonによるDeep Learningの実装
by
Shinya Akiba
PDF
補足資料 財務3表の基礎知識
by
horihorio
PDF
統計と会計 - Zansa#19
by
horihorio
PDF
Google's r style guideのすゝめ
by
Takashi Kitano
PDF
独立成分分析 ICA
by
Daisuke Yoneoka
PDF
tokyor29th
by
Mikiya Tanizawa
PDF
独立成分分析とPerfume
by
Yurie Oka
Zansa第12回資料 「ソーシャルゲームでは、データがユーザーを理解する!」
by
Shota Kubo
121218 zansa13 for web
by
Zansa
Zansa アト テクノロシ-ー業界の分析という仕事について http://zansa.info/materials-11.html
by
Zansa
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
Zansa0802
by
Yoshifumi Seki
【Zansa】第17回 ブートストラップ法入門
by
Zansa
ビジネスの現場のデータ分析における理想と現実
by
Takashi J OZAKI
社会の意見のダイナミクスを物理モデルとして考えてみる
by
takeshi0406
幾何を使った統計のはなし
by
Toru Imai
PythonによるDeep Learningの実装
by
Shinya Akiba
補足資料 財務3表の基礎知識
by
horihorio
統計と会計 - Zansa#19
by
horihorio
Google's r style guideのすゝめ
by
Takashi Kitano
独立成分分析 ICA
by
Daisuke Yoneoka
tokyor29th
by
Mikiya Tanizawa
独立成分分析とPerfume
by
Yurie Oka
More from Atsushi Hayakawa
PDF
tidyverse.orgの翻訳
by
Atsushi Hayakawa
PDF
Zepp play soccerで測ってみた
by
Atsushi Hayakawa
PDF
dataclassとtypehintを使ってますか?
by
Atsushi Hayakawa
PDF
トライアスロンとgepuro task views V2.0 Japan.R 2018
by
Atsushi Hayakawa
PPTX
バンクーバー旅行記
by
Atsushi Hayakawa
PPTX
Analyze The Community Of Tokyo.R
by
Atsushi Hayakawa
PPTX
Visual Studio CodeでRを使う
by
Atsushi Hayakawa
PDF
トライアスロンと僕 - Japan.R 2017
by
Atsushi Hayakawa
PDF
simputatoinで欠損値補完 - Tokyo.R #65
by
Atsushi Hayakawa
PDF
useR!2017 in Brussels
by
Atsushi Hayakawa
PPTX
Japan.R 2016の運営
by
Atsushi Hayakawa
PPTX
Rstudio上でのパッケージインストールを便利にするaddin4githubinstall
by
Atsushi Hayakawa
PDF
統計的学習の基礎 4.4~
by
Atsushi Hayakawa
PDF
Splatoon界での壮絶な戦い&Japan.Rの宣伝
by
Atsushi Hayakawa
PDF
最近のクラウドストレージの事情と私情
by
Atsushi Hayakawa
PDF
gepuro task views
by
Atsushi Hayakawa
PDF
nginxのログを非スケーラブルに省メモリな方法で蓄積する
by
Atsushi Hayakawa
PDF
implyを用いたアクセスログの可視化
by
Atsushi Hayakawa
PDF
イケてる分析基盤をつくる
by
Atsushi Hayakawa
PDF
らずぱいラジコン
by
Atsushi Hayakawa
tidyverse.orgの翻訳
by
Atsushi Hayakawa
Zepp play soccerで測ってみた
by
Atsushi Hayakawa
dataclassとtypehintを使ってますか?
by
Atsushi Hayakawa
トライアスロンとgepuro task views V2.0 Japan.R 2018
by
Atsushi Hayakawa
バンクーバー旅行記
by
Atsushi Hayakawa
Analyze The Community Of Tokyo.R
by
Atsushi Hayakawa
Visual Studio CodeでRを使う
by
Atsushi Hayakawa
トライアスロンと僕 - Japan.R 2017
by
Atsushi Hayakawa
simputatoinで欠損値補完 - Tokyo.R #65
by
Atsushi Hayakawa
useR!2017 in Brussels
by
Atsushi Hayakawa
Japan.R 2016の運営
by
Atsushi Hayakawa
Rstudio上でのパッケージインストールを便利にするaddin4githubinstall
by
Atsushi Hayakawa
統計的学習の基礎 4.4~
by
Atsushi Hayakawa
Splatoon界での壮絶な戦い&Japan.Rの宣伝
by
Atsushi Hayakawa
最近のクラウドストレージの事情と私情
by
Atsushi Hayakawa
gepuro task views
by
Atsushi Hayakawa
nginxのログを非スケーラブルに省メモリな方法で蓄積する
by
Atsushi Hayakawa
implyを用いたアクセスログの可視化
by
Atsushi Hayakawa
イケてる分析基盤をつくる
by
Atsushi Hayakawa
らずぱいラジコン
by
Atsushi Hayakawa
再発事象の解析をやってみる
1.
第16回 zansaの会 再発事象の解析をやってみる @gepuro
3.
データサイエンティスト界を騒がす 話題の本
4.
発表前の様子
5.
発表後の様子 俺達もデータサイエンティストに!!
6.
本題に入ります。
7.
再発事象(recurrent events)とは ● 時間をかけて、何度も繰り返し発生するような事象 のことを言う。 ●
例:がんの再発、ソフトウェアのバグが出る、クレー ムが何度もあるetc
8.
Rで再発事象を解析しよう ● 利用するパッケージは、”survival” ● サンプルデータ: ●
bladder: 個人の再来院データ ● rats: ねずみの乳腺腫瘍のデータ ← 今回はこれ! ● などなど
9.
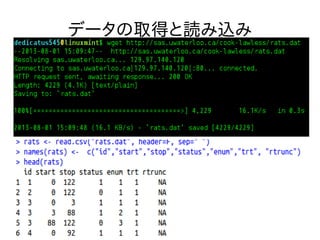
データの取得と読み込み
10.
データの説明 ● Id: ねずみの個体番号 ●
Start: 観測開始 ● Stop: 観測終了 ● Status: 1=腫瘍, 0=打ち切り ● Trt : 1=drug, 0=control ● ...
11.
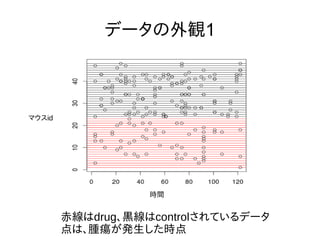
データの外観1 赤線はdrug、黒線はcontrolされているデータ 点は、腫瘍が発生した時点 時間 マウスid
12.
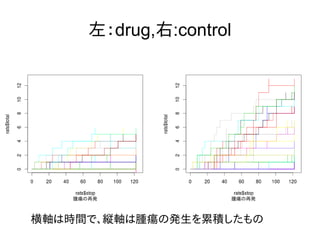
左:drug,右:control 横軸は時間で、縦軸は腫瘍の発生を累積したもの
13.
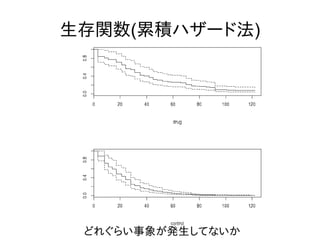
生存関数(累積ハザード法) どれぐらい事象が発生してないか
14.
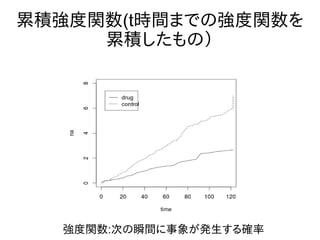
累積強度関数(t時間までの強度関数を 累積したもの) 強度関数:次の瞬間に事象が発生する確率
15.
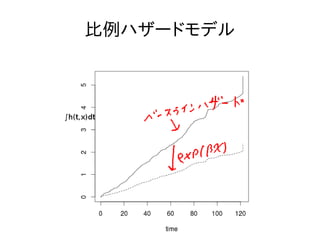
手法 ● 比例ハザードモデルを利用する。
16.
結果
17.
比例ハザードモデル
19.
参考 ● The Statistical
Analysis of Recurrent Events http://sas.uwaterloo.ca/cook-lawless/ ● 講義ノートhttp://stat.inf.uec.ac.jp/dokuwiki/doku.php? id=dm:2013 ● 比例ハザードモデルはとってもtricky! http://www.slideshare.net/takehikoihayashi/tricky ● 信頼性概論 http://avalonbreeze.web.fc2.com/38_01_02_reliability outline.html
20.
おまけ
21.
library("survival") # wget http://sas.uwaterloo.ca/cook-lawless/rats.dat rats
<- read.csv("rats.dat", header=F, sep=" ") names(rats) <- c("id","start","stop","status","enum","trt", "rtrunc") head(rats) rats$total <- NA for(i in unique(rats$id)){ rats.id <- subset(rats, rats$id==i) rats[which(rats$id==i),]$total <- cumsum(rats.id$status) } kaidan.plot <- function(rats){ plot(rats$stop, rats$total, xlim=c(0,125), ylim=c(0,13),sub="腫瘍の再発", type="n") for(j in 1:nrow(rats)){ rats.j <- rats[j,] segments(rats.j$start,rats.j$total-1, rats.j$stop, rats.j$total-1, col=rats.j$id) segments(rats.j$stop, rats.j$total-1, rats.j$stop, rats.j$total, col=rats.j$id) } } kaidan.plot(rats) kaidan.plot(subset(rats, rats$trt==1)) kaidan.plot(subset(rats, rats$trt==0)) data.plot <- function(rats){ plot(seq(1,max(rats$stop),length.out=48),1:48, type="n",xlab="",ylab="") abline(h=24:48) abline(h=1:23,col="red") rats.status1 <- subset(rats, rats$status==1) points(rats.status1$stop, rats.status1$id) } data.plot(rats)
22.
# 強度関数の推定 par(mfrow=c(2,1)) NPfit.1 <-
coxph(Surv(start,stop,status)~1, data=rats, subset=(trt==1),method="breslow") KM.1 <- survfit(NPfit.1, conf.int=.95, type="aalen") plot(KM.1,sub="drug") NPfit.2 <- coxph(Surv(start,stop,status)~1, data=rats, subset=(trt==0),method="breslow") KM.2 <- survfit(NPfit.2, conf.int=.95, type="aalen") plot(KM.2,sub="control") # 累積強度関数 par(mfrow=c(1,1)) NA.MF.1 <- data.frame(time=c(0,KM.1$time), na=-log(c(1,KM.1$surv))) plot(NA.MF.1, type="l", lty=1,ylim=c(0,8), xlim=c(0,120)) NA.MF.2 <- data.frame(time=c(0,KM.2$time), na=-log(c(1,KM.2$surv))) lines(NA.MF.2, type="l", lty=2) legend(locator(1), c("drug","control"), lty=1:2) # 比例ハザードモデル NPfit <- coxph(Surv(start, stop, status)~factor(trt)+cluster(id), data=rats, method="breslow") summary(NPfit) KM <- survfit(NPfit, type="aalen") NA.MF <- data.frame(time=c(0,KM$time), na=-log(c(1,KM$surv))) lines(NA.MF, type="l", lty=4) legend(locator(1), c("drug","control","全部"), lty=c(1:2,4))
Download















![library("survival")
# wget http://sas.uwaterloo.ca/cook-lawless/rats.dat
rats <- read.csv("rats.dat", header=F, sep=" ")
names(rats) <- c("id","start","stop","status","enum","trt", "rtrunc")
head(rats)
rats$total <- NA
for(i in unique(rats$id)){
rats.id <- subset(rats, rats$id==i)
rats[which(rats$id==i),]$total <- cumsum(rats.id$status)
}
kaidan.plot <- function(rats){
plot(rats$stop, rats$total, xlim=c(0,125), ylim=c(0,13),sub="腫瘍の再発", type="n")
for(j in 1:nrow(rats)){
rats.j <- rats[j,]
segments(rats.j$start,rats.j$total-1, rats.j$stop, rats.j$total-1, col=rats.j$id)
segments(rats.j$stop, rats.j$total-1, rats.j$stop, rats.j$total, col=rats.j$id)
}
}
kaidan.plot(rats)
kaidan.plot(subset(rats, rats$trt==1))
kaidan.plot(subset(rats, rats$trt==0))
data.plot <- function(rats){
plot(seq(1,max(rats$stop),length.out=48),1:48, type="n",xlab="",ylab="")
abline(h=24:48)
abline(h=1:23,col="red")
rats.status1 <- subset(rats, rats$status==1)
points(rats.status1$stop, rats.status1$id)
}
data.plot(rats)](https://image.slidesharecdn.com/recurrent-130809211423-phpapp02/85/slide-21-320.jpg)
































































