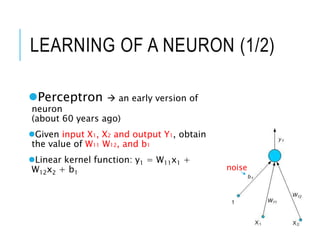
LEARNING OF ANEURON (1/2)
Perceptron an early version of
neuron
(about 60 years ago)
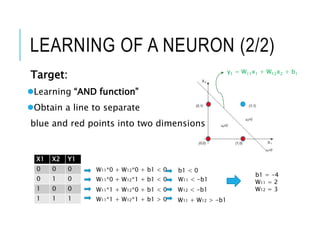
Given input X1, X2 and output Y1, obtain
the value of W11 W12, and b1
Linear kernel function: y1 = W11x1 +
W12x2 + b1
noise
9.
LEARNING OF ANEURON (2/2)
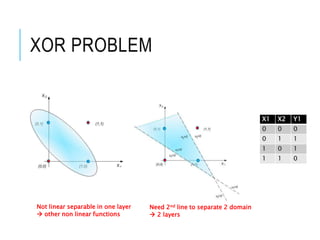
X1 X2 Y1
0 0 0
0 1 0
1 0 0
1 1 1
W11*0 + W12*0 + b1 < 0
W11*0 + W12*1 + b1 < 0
W11*1 + W12*0 + b1 < 0
W11*1 + W12*1 + b1 > 0
b1 = -4
W11 = 2
W12 = 3
W11 < -b1
W12 < -b1
W11 + W12 > -b1
y1 = W11x1 + W12x2 + b1
b1 < 0
Target:
Learning “AND function”
Obtain a line to separate
blue and red points into two dimensions
10.
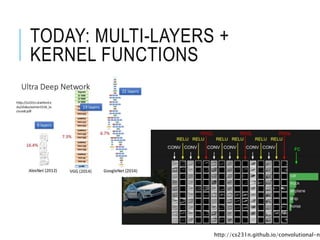
XOR PROBLEM
X1 X2Y1
0 0 0
0 1 1
1 0 1
1 1 0
Not linear separable in one layer
other non linear functions
Need 2nd line to separate 2 domain
2 layers
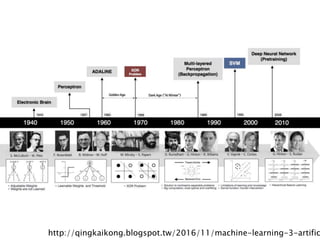
#6 AI -> Machine learning -> Supervised -> NN
Deep learning = Deep NN in Machine learning
有不deep的learning 嗎? Shallow learning
SVM -> 低維度不可分, 那就拉到高維度分看看









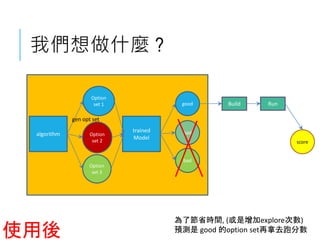








![資料怎麼接到TENSORFLOW ?
我要準備準備哪些資料 ? it depends
我的NN網路長怎樣 ? keras exampmle
我的資料怎麼送到NN網路當input ?
option set轉成option總表中的0 or 1
ex: -O3 -funroll-loops -finline -fweb …..
[0,0,1,0,1.......]
我要預測什麼 ? 要預測exactly 優化幾%做不出來。
把要預測的值簡化成8個。](https://image.slidesharecdn.com/hellodnnpptx-170515052920/85/Hello-DNN-27-320.jpg)
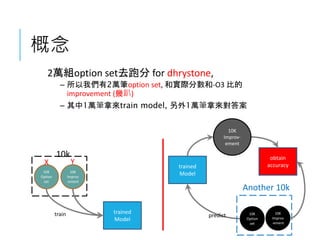
![資料怎麼接到TENSORFLOW ?
我要準備準備哪些資料 ? it depends
我的NN網路長怎樣 ? start from mnist_mlp
我的資料怎麼送到NN網路當input ?
option set轉成option總表中的0 or 1
ex: -O3 -funroll-loops -finline -fweb …..
[0,0,1,0,1.......]
我要預測什麼 ? 要預測exactly 優化幾%做不出來。
把要預測的值簡化成8個。](https://image.slidesharecdn.com/hellodnnpptx-170515052920/85/Hello-DNN-28-320.jpg)
![資料怎麼接到TENSORFLOW ?
我要準備準備哪些資料 ? it depends
我的NN網路長怎樣 ? keras exampmle
我的資料怎麼送到NN網路當input ?
option set轉成option總表中的0 or 1
ex: -O3 -funroll-loops -finline -fweb …..
[0,0,1,0,1.......]
我要預測什麼 ? 要預測exactly 優化幾%做不出來。
把要預測的值簡化成8個。](https://image.slidesharecdn.com/hellodnnpptx-170515052920/85/Hello-DNN-29-320.jpg)
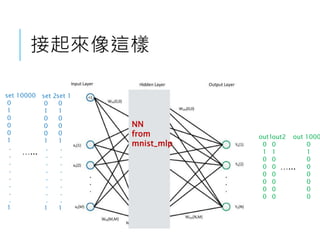
![資料怎麼接到TENSORFLOW ?
我要準備準備哪些資料 ? it depends
我的NN網路長怎樣 ? keras exampmle
我的資料怎麼送到NN網路當input ?
option set轉成option總表中的0 or 1
ex: -O3 -funroll-loops -finline -fweb …..
[0,0,1,0,1.......]
我要預測什麼 ? 要預測exactly 優化幾%做不出來。
把要預測的值簡化成8個。
Y[4]Y[5]Y[6]Y[7]
0.02 0.04
Y[1]
Y[2]
Y[3]
Y[0] = 沒分數, build or run 壞了](https://image.slidesharecdn.com/hellodnnpptx-170515052920/85/Hello-DNN-30-320.jpg)

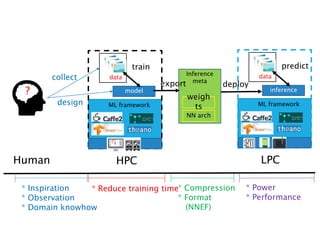
![實驗結果
是good我們才想真的下去跑
也就是說有預測到落在Y[1], Y[2], Y[3]對我們來說就是猜到了
猜中good的準確率71%
Train好的model拿去預測eembc1.1 的automotive也是
68~71%準確率
Y[4]Y[5]Y[6]Y[7]
0.02 0.04
Y[1]
Y[2]
Y[3]
Y[0] = 做不出來](https://image.slidesharecdn.com/hellodnnpptx-170515052920/85/Hello-DNN-33-320.jpg)


























![[台灣人工智慧學校] 人工智慧民主化在台灣](https://cdn.slidesharecdn.com/ss_thumbnails/aidemocratization180512sw-180515030532-thumbnail.jpg?width=640&height=640&fit=bounds)




![[students AI workshop] Pytorch](https://cdn.slidesharecdn.com/ss_thumbnails/pytorch1-170911183243-thumbnail.jpg?width=640&height=640&fit=bounds)
