陳昇瑋 / 從大數據走向人工智慧3
Academia Sinica
= Chinese Academy
32 research institutes in 3 major divisions
1) mathematics, physics, and applied sciences;
2) life sciences;
3) humanities and social sciences.
1,000 tenure-tracked research fellows
6,000 assistants, students, and technicians
陳昇瑋 / 從大數據走向人工智慧
Collecting& storing data is much economic now
New types and wide deployed sensors
Advances in machine learning (esp. for analyzing
unstructured data)
Why Big Data?
16.
陳昇瑋 / 從大數據走向人工智慧
Seethrough walls with WiFi!
34
applies to 8” concrete walls,
6” hollow walls, and
1.75” solid wooden doors.
陳昇瑋 / 從大數據走向人工智慧
MachineLearning
50
A type of algorithms that gives computers the
ability to learn rules from experience, rather than
being hard coded.
Find the common patterns
from the left waveforms
It seems impossible to
write a program for
speech recognition
你好 你好
你好 你好
You quickly get lost in the
exceptions and special cases.
(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 從大數據走向人工智慧
Letthe machine learn by itself
你好
大家好
人帥真好
You said
“你好”
A large amount of
audio data
You only have to write the
learning algorithm ONCE
Derive rules
from datasets
(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 從大數據走向人工智慧
MachineReading
Machine learn the meaning of words from reading a lot
of documents without supervision
Machine learns to
understand netizens via
reading the posts on PTT
(Slide Credit: Hung-Yi Lee)
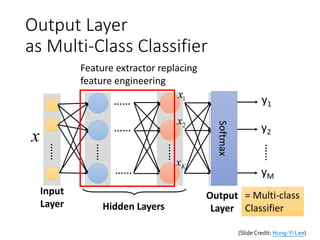
Example Application
Input Output
16x 16 = 256
1x
2x
256x
……
Ink → 1
No ink → 0
……
y1
y2
y10
Each dimension represents
the confidence of a digit.
is 1
is 2
is 0
……
0.1
0.7
0.2
The image
is “2”
(Slide Credit: Hung-Yi Lee)
63.
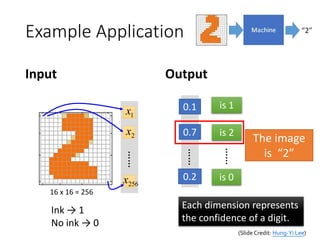
Example Application
• HandwritingDigit Recognition
Machine “2”
1x
2x
256x
……
……
y1
y2
y10
is 1
is 2
is 0
……
What is needed is a
function ……
Input:
256-dim vector
output:
10-dim vector
Neural
Network
(Slide Credit: Hung-Yi Lee)
64.
Sheng-Wei Chen /From Data Science to Artificial Intelligence
Learning to do XOR
(Credit: Deep Learning Book)
ReLU (Rectified Linear Unit)
Y = aX + b?
65.
Sheng-Wei Chen /From Data Science to Artificial Intelligence
XW + c =
ReLU(XW + c) = w (ReLU(XW + c)) =
(Credit: Deep Learning Book)
ReLU (Rectified Linear Unit)
66.
Sheng-Wei Chen /From Data Science to Artificial Intelligence
XW + c =
ReLU(XW + c) = w (ReLU(XW + c)) =
(Credit: Deep Learning Book)
Modularization
• Deep →Modularization
1x
2x ……
Nx
……
……
……
……
……
……
The most basic
classifiers
Use 1st layer as module
to build classifiers
Use 2nd layer as
module ……
The modularization is
automatically learned from data.
→ Less training data?
(Slide Credit: Hung-Yi Lee)
70.
Modularization - Image
•Deep → Modularization
1x
2x
……
Nx
……
……
……
……
……
……
The most basic
classifiers
Use 1st layer as module
to build classifiers
Use 2nd layer as
module ……
Reference: Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding
convolutional networks. In Computer Vision–ECCV 2014 (pp. 818-833)
(Slide Credit: Hung-Yi Lee)
71.
陳昇瑋 / 從大數據走向人工智慧
Multi-layerpatterns learned from faces
93
(Credit: https://www.slideshare.net/WillStanton/deep-learning-with-text-v4)
Fat + Shortv.s. Thin + Tall
1x 2x …… Nx
Deep
1x 2x …… Nx
……
Shallow
Which one is better?
The same number
of parameters
(Slide Credit: Hung-Yi Lee)
74.
Fat + Shortv.s. Thin + Tall
Seide, Frank, Gang Li, and Dong Yu. "Conversational Speech Transcription
Using Context-Dependent Deep Neural Networks." Interspeech. 2011.
Layer X Size
Word Error
Rate (%)
Layer X Size
Word Error
Rate (%)
1 X 2k 24.2
2 X 2k 20.4
3 X 2k 18.4
4 X 2k 17.8
5 X 2k 17.2 1 X 3772 22.5
7 X 2k 17.1 1 X 4634 22.6
1 X 16k 22.1
(Slide Credit: Hung-Yi Lee)
A Straightforward Answer
•Do Deep Nets Really Need To Be Deep? (by Rich Caruana)
• http://research.microsoft.com/apps/video/default.aspx?id=
232373&r=1
keynote of Rich Caruana at ASRU 2015
(Slide Credit: Hung-Yi Lee)
77.
陳昇瑋 / 網路購書大數據
DeepNeural Networks
99
1. Deep = many layers
2. Deep = hierarchical of concepts
Does not “memorize”millions of viewed samples
Extracts greatly reduced number of features that
are vital to classify different classes of data
Classifying data becomes a simple task when the
features measured are “”good”
What do DNNs learn?
(Slide Credit: AlbertY. C. Chen)
陳昇瑋 / 從大數據走向人工智慧
1958:Perceptron (linear model)
1969: Perceptron has limitation
1980s: Multi-layer perceptron
Do not have significant difference from DNN today
1986: Backpropagation
Usually more than 3 hidden layers is not helpful
1989: 1 hidden layer is “good enough”, why deep?
2006: RBM initialization
2009: GPU
2011: Start to be popular in speech recognition
2012: win ILSVRC image competition
2015.2: Image recognition surpassing human-level performance
2016.3: Alpha GO beats Lee Sedol
2016.10: Speech recognition system as good as humans
Ups and downs of Deep Learning
(Slide Credit: Hung-Yi Lee)
85.
What was actuallywrong with backprop
in 1986?
We all drew the wrong conclusions about why it
failed. The real reasons were:
Our labeled datasets were thousands of times too
small.
Our computers were millions of times too slow.
We initialized the weights in a stupid way.
We used the wrong type of non-linearity.
107
(Credit: Geoff Hinton,What Was ActuallyWrongWith Backpropagation in 1986?)
陳昇瑋 / 從大數據走向人工智慧
NNbreakthroughs since 1970’s
Network structure
Optimization method
Dataset
Computation power!
More modeling variants
113
91.
1. Better NetworkStructure
Convolutional Neural Network greatly reduces the number of variables in
NN’s designed for images and videos. —> Improved convergence speed,
reduced data requirements.
Upper-left corner
Bird Beak Detector
Center Bird Beak
Detector
Almost identical, can be shared across regions
(Slide Credit: AlbertY. C. Chen)
陳昇瑋 / 從大數據走向人工智慧
Convolutional
NeuralNetworks
Convolution
Max Pooling
Convolution
Max Pooling
Flatten
Can repeat
many times
Some patterns are much
smaller than the whole image
The same patterns appear in
different regions.
Subsampling the pixels will
not change the object
Property 1
Property 2
Property 3
(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 從大數據走向人工智慧
CNN– Max Pooling
1 0 0 0 0 1
0 1 0 0 1 0
0 0 1 1 0 0
1 0 0 0 1 0
0 1 0 0 1 0
0 0 1 0 1 0
6 x 6 image
3 0
13
-1 1
30
2 x 2 image
Each filter
is a channel
New image
but smaller
Conv
Max
Pooling
(Slide Credit: Hung-Yi Lee)
99.
陳昇瑋 / 從大數據走向人工智慧
1.Network Structure
Each filter of C1 has a 5x5 receptive field in the input layer
(5*5+1)*6=156 parameters to learn for the 1st layer
If it was fully connected we had (32*32+1)*(28*28)*6 = 4,821,600
parameters
(Slide Credit: AlbertY. C. Chen)
100.
2. Improved ActivationFunctions
Large
input
Small
output
……
……
……
……
……
……
……
……
y1
y2
yM
(Slide Credit: AlbertY. C. Chen)
101.
陳昇瑋 / 從大數據走向人工智慧
ReLU
RectifiedLinear Unit (ReLU)
Reasons:
1. Fast to compute
2. Biological reason
3. Infinite sigmoid
with different biases
4.Vanishing gradient
problem
𝑧𝑧
𝑎𝑎
𝑎𝑎 = 𝑧𝑧
𝑎𝑎 = 0
𝜎𝜎 𝑧𝑧
[Xavier Glorot, AISTATS’11]
[Andrew L. Maas, ICML’13]
[Kaiming He, arXiv’15]
(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 從大數據走向人工智慧
Dropout
Training:
Each time before updating the parameters
Each neuron has p% to dropout
Using the new network for training
The structure of the network is changed.
Thinner!
For each mini-batch, we resample the dropout neurons
(Slide Credit: Hung-Yi Lee)
107.
陳昇瑋 / 從大數據走向人工智慧
Dropoutcan be considered a form of
bagging
130
Bagging stands for bootstrap aggregating
A technique of model averaging / ensemble models for
reducing generalization errors
108.
陳昇瑋 / 從大數據走向人工智慧
DeepNeural Networks (DNN)
are way more complex and capable!
(Slide Credit: AlbertY. C. Chen)
陳昇瑋 / 從大數據走向人工智慧
Whatdo CNNs learn?
Neurons act like “custom-trained filters”;
react to very different visual cues, depending on data.
(Slide Credit: AlbertY. C. Chen)
112.
陳昇瑋 / 從大數據走向人工智慧
Whatdo CNNs learn?
Neurons act like “custom-trained filters”; react to
very different visual cues, depending on data.
(Slide Credit: AlbertY. C. Chen)
陳昇瑋 / 從大數據走向人工智慧
如果你想“深度學習 深度學習”
“Deep Learning”
Written by Yoshua Bengio,
Ian J. Goodfellow and Aaron Courville
http://www.iro.umontreal.ca/~bengioy/
dlbook/
“Neural Networks and Deep Learning”
written by Michael Nielsen
http://neuralnetworksanddeeplearning.com/
Course: Machine learning and having it deep and
structured
http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLSD15_
2.html
(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 從大數據走向人工智慧
ColorfulImage Colorization
152
Zhang, Richard, Phillip Isola, and Alexei A. Efros. "Colorful image colorization." European
Conference on Computer Vision. Springer International Publishing, 2016.
128.
陳昇瑋 / 從大數據走向人工智慧
ColorfulImage Colorization
153
http://richzhang.github.io/colorization/
A 313-class classification problem
Input: 224x224x1 (L)
Model output: 64x64x313
Pixel values: annealed mean of 313
colors
陳昇瑋 / 從大數據走向人工智慧
Typesof Machine Learning Methods
192
Machine
Learning
Supervised UnsupervisedReinforcement
Task driven
(Regression /
Classification)
Data driven
(Clustering,
Dimension Reduction)
Learning by reacting
to feedback
155.
陳昇瑋 / 從大數據走向人工智慧
WhySupervised Learning is Not Enough
193
https://www.reddit.com/r/MachineLearning/comments/2lmo0l/ama_geoffrey_hinton/
The brain has about 1014 synapses and we only live for about
109 seconds. So we have a lot more parameters than data.
This motivates the idea that we must do a lot of
unsupervised learning since the perceptual input (including
proprioception) is the only place we can get 105 dimensions
of constraint per second.
-- Geoffrey Hinton
陳昇瑋 / 從大數據走向人工智慧
ApproachesTo Reinforcement Learning
Policy-based RL
Search directly for the optimal policy
This is the policy achieving maximum future reward
Value-based RL
Estimate the optimal value function
This is the maximum value achievable under any policy
Model-based RL
Build a transition model of the environment
Plan (e.g. by lookahead) using model
Of course you can combine any of the above
196
158.
陳昇瑋 / 從大數據走向人工智慧
TypicalApplications of RL
Play games: Atari, poker, Go, ...
Explore worlds: 3D worlds, Labyrinth, ...
Control physical systems: manipulate, walk, swim, ...
Interact with users: recommend, optimize, personalize,
...
197
(Slide credit: David Silver)
陳昇瑋 / 從大數據走向人工智慧
MoreRL Applications
Flying Helicopter
Driving
Google Cuts Its Giant Electricity Bill With DeepMind-
Powered AI
Parameter tuning in manufacturing lines
Text generation
Hongyu Guo, “Generating Text with Deep Reinforcement
Learning”, NIPS, 2015
Marc'AurelioRanzato,SumitChopra,Michael Auli,Wojciech
Zaremba, “Sequence Level Training with Recurrent Neural
Networks”, ICLR, 2016
201(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 從大數據走向人工智慧
DataScience vs. Big Data
Data Science is a superset of Big Data.
However, the rise of Big Data draws people’s
attention to Data Science.
205
Data
Science
Big Data
Machine
Learning
Data
Mining
Deep
Learning
陳昇瑋 / 從大數據走向人工智慧
Datavs. Machine learning vs. AI
Data: records of experience
Machine learning: “A type of algorithms
that gives computers the ability to learn
from data, rather than being explicitly
programmed."
Artificial intelligence
Turing test
209
陳昇瑋 / 從大數據走向人工智慧
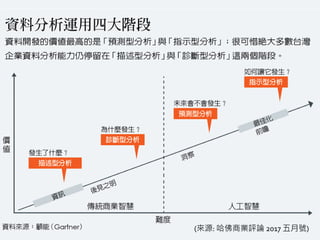
DataVisualization vs. Data Analysis
214
Visualization is the act or process of interpreting in visual
terms or of putting into visible form.
Analysis indicates a careful study of something to learn
about its parts, what they do, and how they are related to
each other.
—Merriam-Webster's Dictionary
陳昇瑋 / 從大數據走向人工智慧
AI能做什麼
258
Smart R&D and
forecasting
Project
Optimized
production with
lower cost and
higher efficiency
Produce
Products and
services at the
right price, time,
and targets
Promote
Enriched and
tailored user
experience
Provide
人工智慧發展策略建議
An Example ofIndustry-wide Problem:
Human Operators for Optical Inspection
A sad story that AI-assisted AOI can help avoid
“流水線工作是流動人口最容易獲得的工作,像 … 這樣的工廠只招29周歲
以下的工人,工廠就像割韭菜,一茬一茬地收割這些流動勞動力的青春。"
29-year old or younger wanted
“她在流水線上的工作是檢查產品是否有劃痕,一整天機械重複同一個簡單
枯燥的動作兩千八百八十次"
This means 4 times
per minute assuming
12 working hours per day
https://theinitium.com/article/20170802-mainland-Foxconn-factorygirl/
陳昇瑋 / 從大數據走向人工智慧
DeepLearning for Detection of Diabetic
Eye Disease (2016)
355
https://research.googleblog.com/2016/11/deep-
learning-for-detection-of-diabetic.html
128,000 images
Each image was evaluated by 3-7 ophthalmologists from
a panel of 54
A separate validation set of 12,000 images
200.
陳昇瑋 / 從大數據走向人工智慧
DeepLearning for Detection of Diabetic
Eye Disease (2016)
356
Algorithm’s F1-score: 0.95
Median F1-score of 8 ophthalmologists : 0.91
201.
陳昇瑋 / 從大數據走向人工智慧357
1007 posteroanterior chest radiographs
AUC = 0.99 when AlexNet and GoogLeNet are combined using
ensemble.
Cardiologist-Level Arrhythmia Detection
withConvolutional Neural Networks
360
Goal: diagnose irregular heart rhythms, also known as
arrhythmias, from single-lead ECG signals better than a
cardiologist
205.
陳昇瑋 / 從大數據走向人工智慧
Inputand Output
Sequence-to-sequence
Input: a time-series of raw ECG signal
The 30 second long ECG signal is sampled at 200 Hz
Output: a sequence of rhythm classes
The model outputs a new prediction once every second
Total 14 rhythm classes are identified
361
陳昇瑋 / 從大數據走向人工智慧
Dataset
Trainingdataset
Collect a dataset of 64,121 ECG records from 29,163 patients
Each ECG record is 30 seconds long and sampled at 200 Hz
Annotations are done by a group of Certified Cardiographic
Technicians
Testing dataset
336 records from 328 unique patients
Annotations are obtained by a committee of three board-
certified cardiologists
363
208.
陳昇瑋 / 從大數據走向人工智慧
Model
34layers NN
16 residual blocks
2 conv layers per block
Filter length = 16 samples
# filter = 64*k, k start from 1 and is
incremented every 4-th residual block
Every residual block subsamples
its input by a factor of 2
364
陳昇瑋 / 從大數據走向人工智慧
RecurrentNeural Network (RNN)
1x 2x
2y1y
1a 2a
Memory can be considered
as another input.
The output of hidden layer
are stored in the memory.
store
(Slide Credit: Hung-Yi Lee)
212.
Memory
Cell
Long Short-term Memory(LSTM)
Input Gate
Output Gate
Signal control
the input gate
Signal control
the output gate
Forget
Gate
Signal control
the forget gate
Other part of the network
Other part of the network
(Other part of
the network)
(Other part of
the network)
(Other part of
the network)
LSTM
Special Neuron:
4 inputs,
1 output
(Slide Credit: Hung-Yi Lee)
213.
𝑧𝑧
𝑧𝑧𝑖𝑖
𝑧𝑧𝑓𝑓
𝑧𝑧𝑜𝑜
𝑔𝑔 𝑧𝑧
𝑓𝑓 𝑧𝑧𝑖𝑖
multiply
multiply
Activationfunction f is
usually a sigmoid function
Between 0 and 1
Mimic open and close gate
c
𝑐𝑐′
= 𝑔𝑔 𝑧𝑧 𝑓𝑓 𝑧𝑧𝑖𝑖 + 𝑐𝑐𝑐𝑐 𝑧𝑧𝑓𝑓
ℎ 𝑐𝑐′𝑓𝑓 𝑧𝑧𝑜𝑜
𝑎𝑎 = ℎ 𝑐𝑐′
𝑓𝑓 𝑧𝑧𝑜𝑜
𝑔𝑔 𝑧𝑧 𝑓𝑓 𝑧𝑧𝑖𝑖
𝑐𝑐′
𝑓𝑓 𝑧𝑧𝑓𝑓
𝑐𝑐𝑐𝑐 𝑧𝑧𝑓𝑓
𝑐𝑐
(Slide Credit: Hung-Yi Lee)
214.
Multiple-layer
LSTM
This is quite
standardnow.
https://img.komicolle.org/2015-09-20/src/14426967627131.gif
Don’t worry if you cannot understand this.
Keras can handle it.
Keras supports
“LSTM”, “GRU”, “SimpleRNN” layers
(Slide Credit: Hung-Yi Lee)
陳昇瑋 / 從大數據走向人工智慧
AIvs. BI
AI systems make decisions for users
BI systems help users make the right decisions,
based on the available data
Key difference
AI systems are based on generalized models
BI systems require humans to generalize
Best practice: AI + BI work together
393
218.
陳昇瑋 / 從大數據走向人工智慧395
Google Search Frequency on
“Big Data” and “Data Science”
Data Science
Big Data
219.
陳昇瑋 / 從大數據走向人工智慧397
Google Search Frequency on
“Machine Learning” and “Deep Learning”
Deep Learning
Machine Learning


































































































![陳昇瑋 / 從大數據走向人工智慧
ReLU
Rectified Linear Unit (ReLU)
Reasons:
1. Fast to compute
2. Biological reason
3. Infinite sigmoid
with different biases
4.Vanishing gradient
problem
𝑧𝑧
𝑎𝑎
𝑎𝑎 = 𝑧𝑧
𝑎𝑎 = 0
𝜎𝜎 𝑧𝑧
[Xavier Glorot, AISTATS’11]
[Andrew L. Maas, ICML’13]
[Kaiming He, arXiv’15]
(Slide Credit: Hung-Yi Lee)](https://image.slidesharecdn.com/datatoai-171202110808/85/slide-101-320.jpg)
![陳昇瑋 / 從大數據走向人工智慧
w1
w2
Clipping
[Razvan Pascanu, ICML’13]
3. Effective Backpropagation
(Slide Credit: AlbertY. C. Chen)](https://image.slidesharecdn.com/datatoai-171202110808/85/slide-102-320.jpg)






























































































































































![[台灣人工智慧學校] 主題演講: 人工智慧產業發展趨勢](https://cdn.slidesharecdn.com/ss_thumbnails/180929kungming-hsin-181001064957-thumbnail.jpg?width=640&height=640&fit=bounds)


![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)








![[台灣人工智慧學校] 人工智慧民主化在台灣](https://cdn.slidesharecdn.com/ss_thumbnails/aidemocratization180512sw-180515030532-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)



























