About me
• Education
•NCU (MIS)、NCCU (CS)
• Work Experience
• Telecom big data Innovation
• AI projects
• Retail marketing technology
• User Group
• TW Spark User Group
• TW Hadoop User Group
• Taiwan Data Engineer Association Director
• Research
• Big Data/ ML/ AIOT/ AI Columnist
2
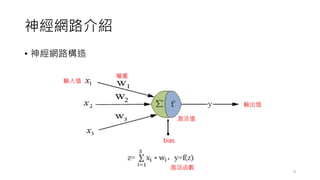
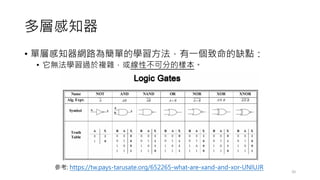
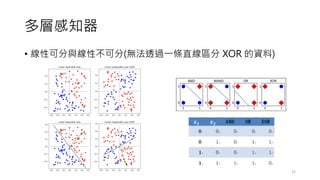
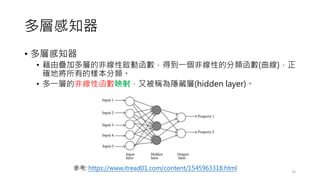
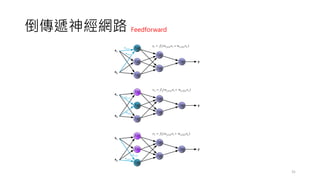
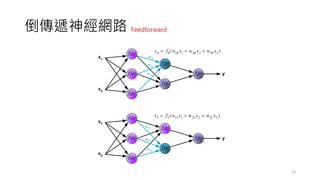
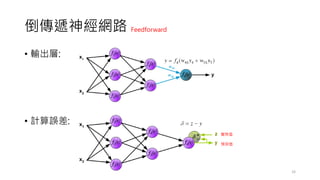
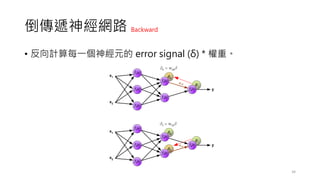
前饋神經網路
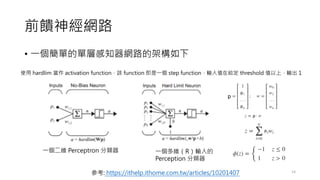
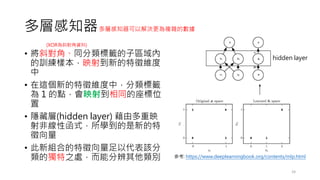
• 一個簡單的單層感知器網路的架構如下
14
一個二維 Perceptron分類器 一個多維(R)輸入的
Perception 分類器
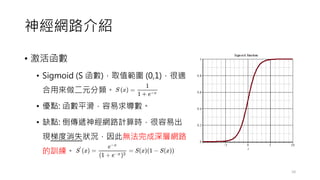
使用 hardlim 當作 activation function,該 function 即是一個 step function,輸入值在給定 threshold 值以上,輸出 1
參考: https://ithelp.ithome.com.tw/articles/10201407
p
p
p
p
p
15.
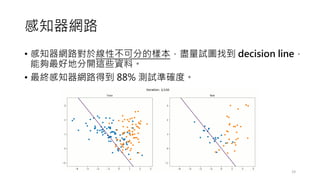
感知器網路
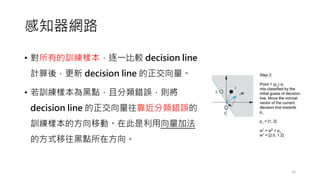
• 黑點的分類標籤被標註為 1,而白點的分類標
籤被標註為-1。
• 產生隨機初始化 decision line 的法線向量 w。
• 藍色實線為該步驟所計算得到的 decision line
和它的法線(藍色箭頭)。
• 當 bias 為零, decision line 就必須通過原點。
15
參考: https://vocus.cc/article/5cc914d6fd8978000171ac06
16.
感知器網路
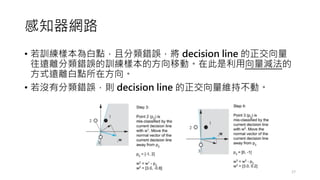
• 對所有的訓練樣本,逐一比較 decisionline
計算後,更新 decision line 的正交向量。
• 若訓練樣本為黑點,且分類錯誤,則將
decision line 的正交向量往靠近分類錯誤的
訓練樣本的方向移動。在此是利用向量加法
的方式移往黑點所在方向。
16
















![Homework
• 請描述神經網路結構與功能描述
• 請說明激活函數的目的
• 請說明優化器的目的
• 利用多層感知器網路進行iris.csv 分類,嘗試對不同參數的理解
• https://goo.gl/281mPF
• [加分題]利用深度學習進行 iris.csv 分類
• Keras: 第10章 项目:多类花朵分类 ·深度学习:Python教程
(cnbeining.github.io)
• Pytorch: Day23-pytorch(6)iris資料集示範classifier模型pytorch完整訓練過
程 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)
40](https://image.slidesharecdn.com/5neuralnetwork-221211055823-82d551d5/85/5_Neural_network_-pdf-40-320.jpg)
















































