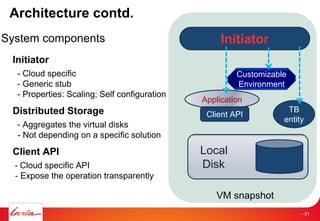
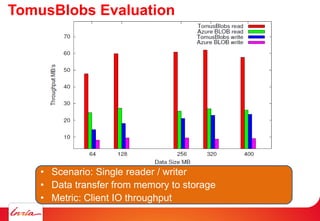
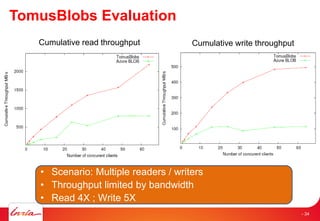
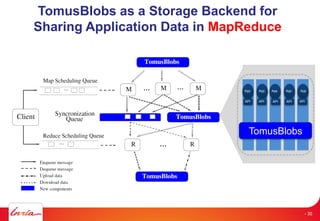
Downloaded 27 times















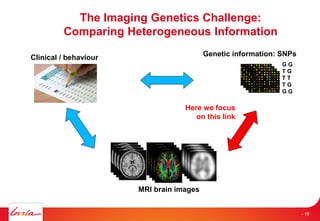




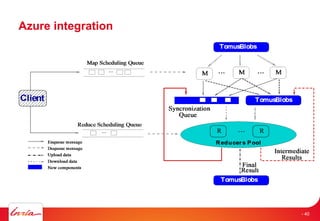

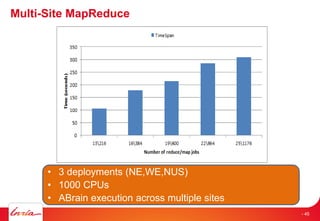

![Data access patterns for workflows [1]
[1] Vairavanathan et al.
A Workflow-Aware Storage
System: An Opportunity Study
http://ece.ubc.ca/~matei/paper
s/ccgrid2012.pdf
Pipeline
Caching
Data informed workflow
Input
Output
Broadcast
Replication
Data size
Input
Output
Reduce/Gather
Co-placement of all data
Data informed workflow
Input
Output
Scatter
File size awareness
Data informed workflow
Input
Output
- 47](https://image.slidesharecdn.com/rec201-mstechdays-final-130213033305-phpapp02-130423104418-phpapp01/85/Azure-Brain-4th-paradigm-scientific-discovery-really-big-data-46-320.jpg)
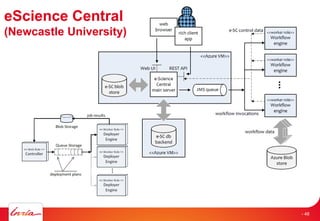
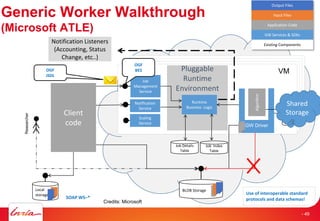
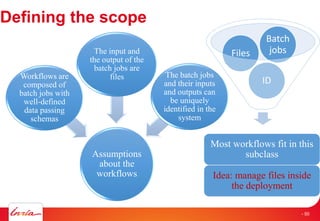
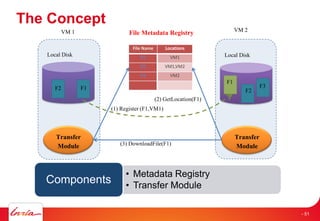

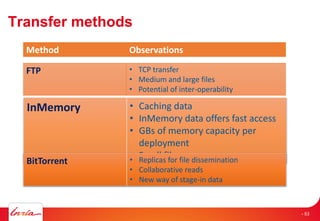
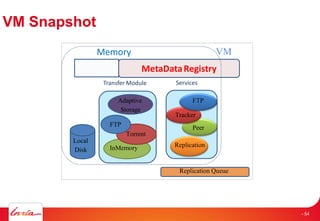
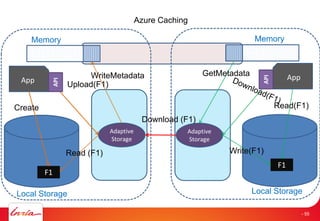
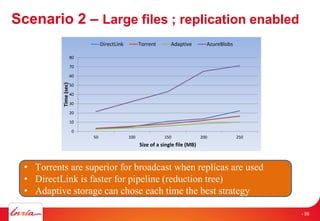

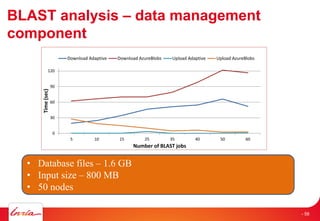




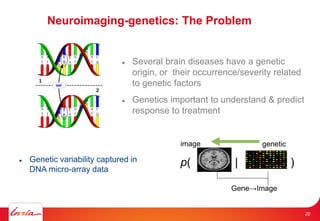
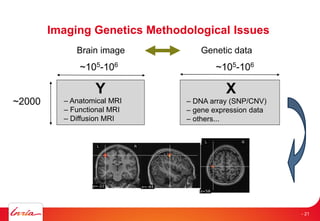
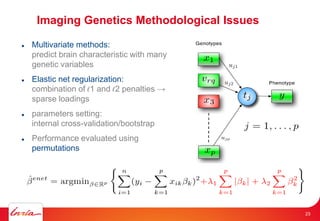
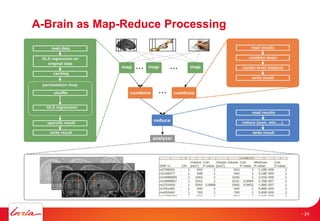
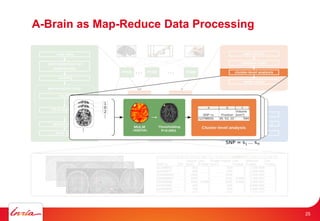
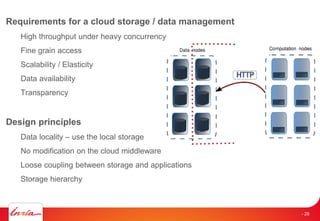
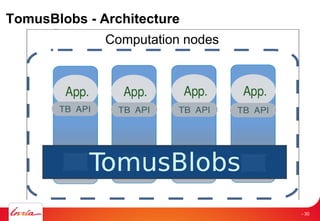
The document discusses INRIA's strategic involvement in cloud computing and big data research, emphasizing its multidisciplinary approach and collaborations with industry. Key initiatives include the development of various project teams focused on cloud infrastructure, data management, and high-performance computing. Notable projects mentioned are the A-Brain project leveraging Microsoft Azure for genetic and neuroimaging data analysis, as well as the Blobseer platform for scalable data management.










































































































