Download as PDF, PPTX














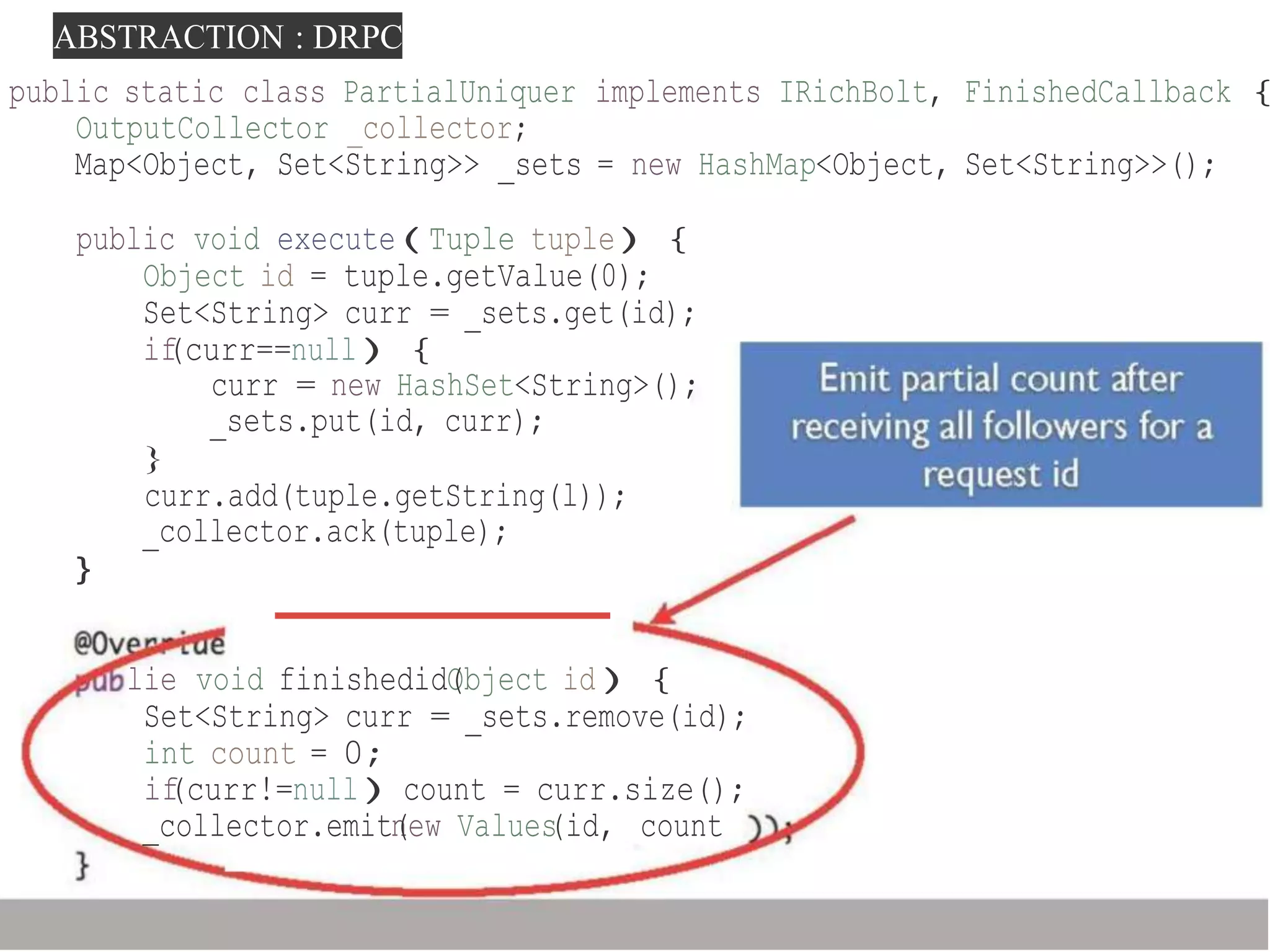
![ABSTRACTION : DRPC
)
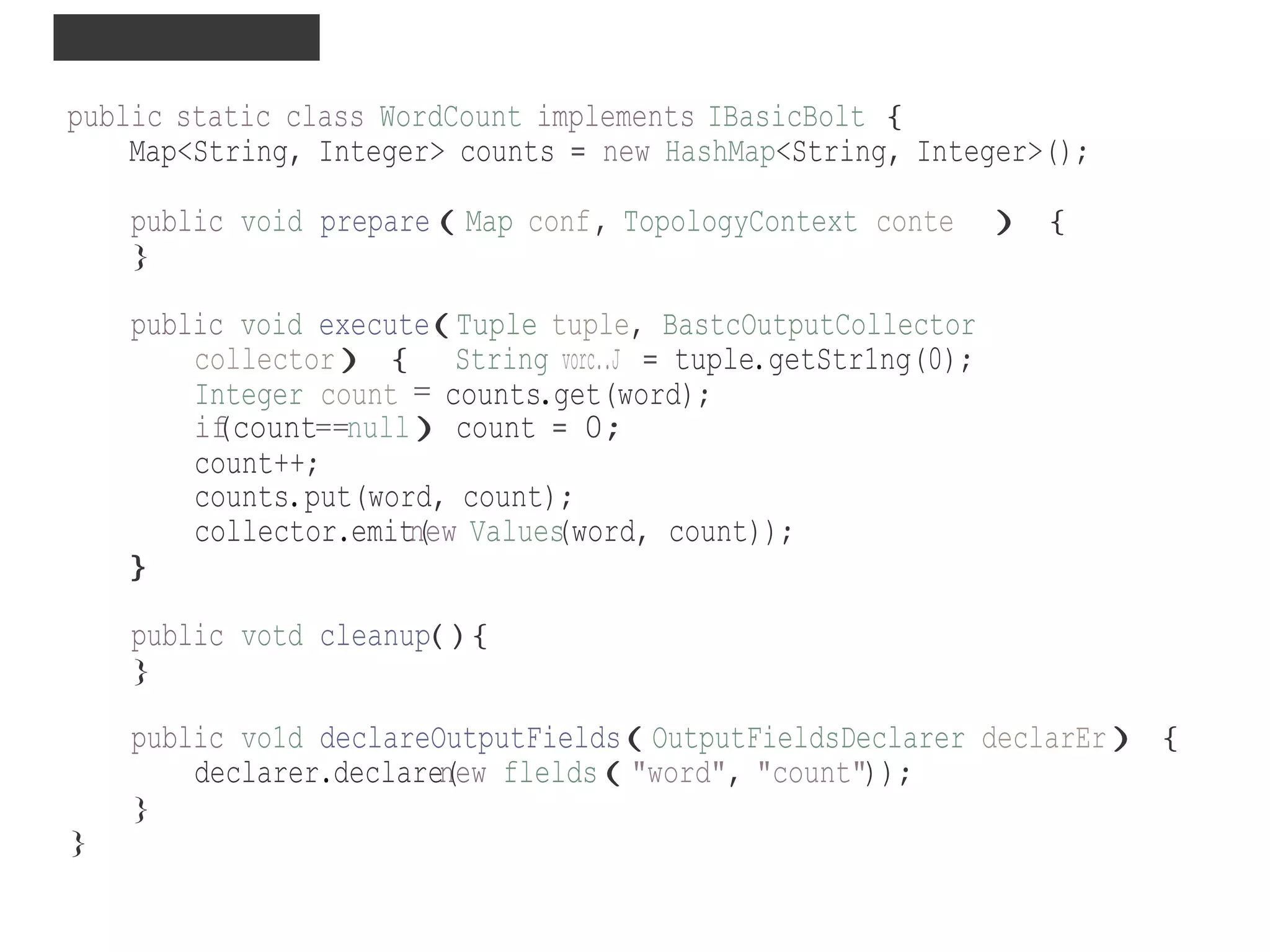
public static class SplttSentence extends ShellBolt implements IRtchBolt {
public SplttSentence()
super("python", "splltsentence.pyH);
}
public votd declareOutputF1elds(OutputF1eldsDeclarer declare!){
declarer.declaren(ew Fields ''word''));
}
}
'import storm
class SplttSentenceBolts(torm.BastcBolt):
def process(self, tup):
words = tup.values[0].spl1t"( 11
for word tn words:
storm.emit([word])](https://image.slidesharecdn.com/stormsercppt-130715151410-phpapp02/75/Storm-Real-Time-Computation-31-2048.jpg)




![ABSTRACTION : DRPC
f
/
l["request-id"',..result"]
,-----
+''result.. - DRPC
-"args.. Server
::.,
Topology
[..request-id"1· "args' "return-info..]
Ill
Ill
Distributed RPC Architecture](https://image.slidesharecdn.com/stormsercppt-130715151410-phpapp02/75/Storm-Real-Time-Computation-39-2048.jpg)
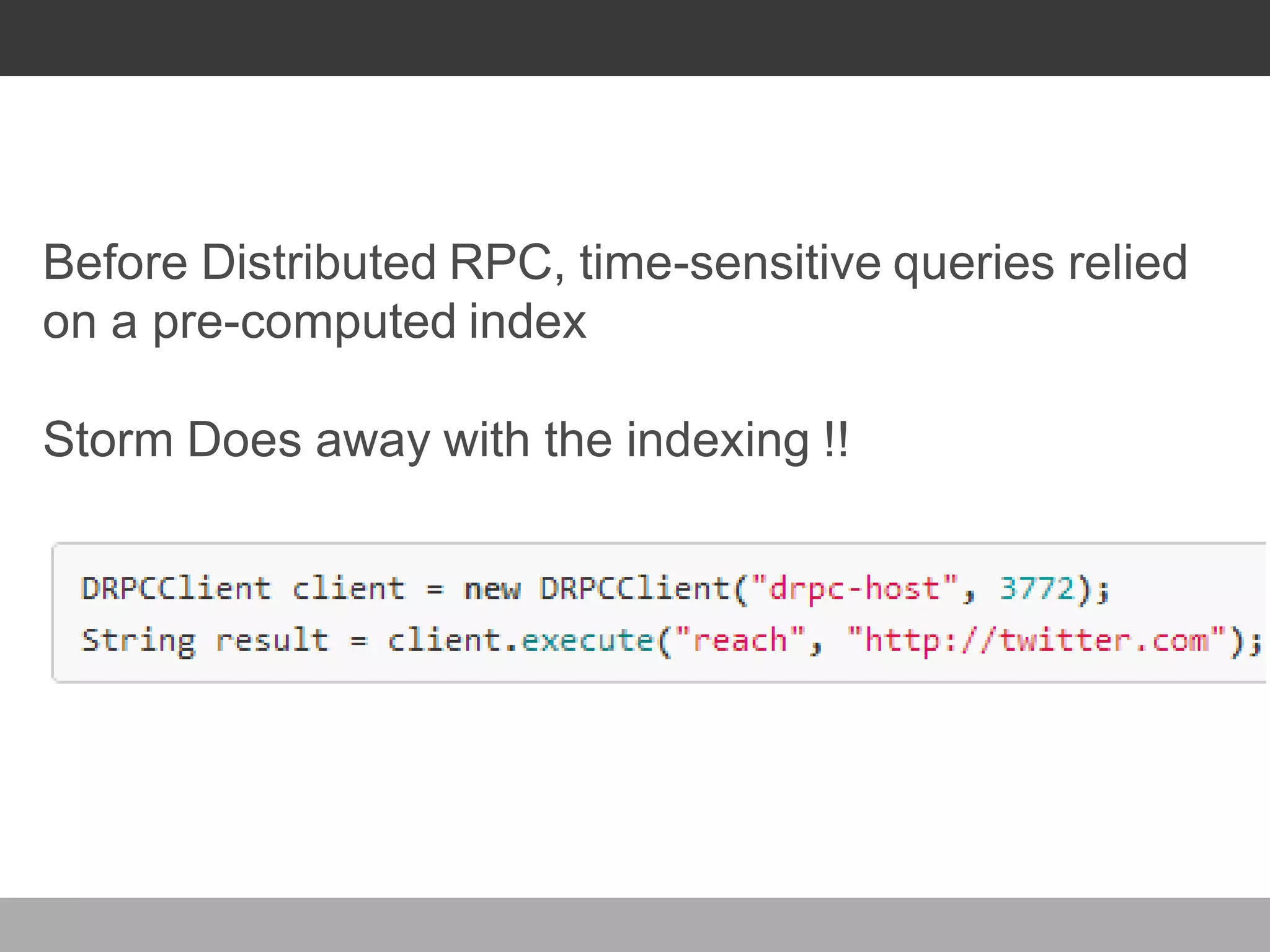

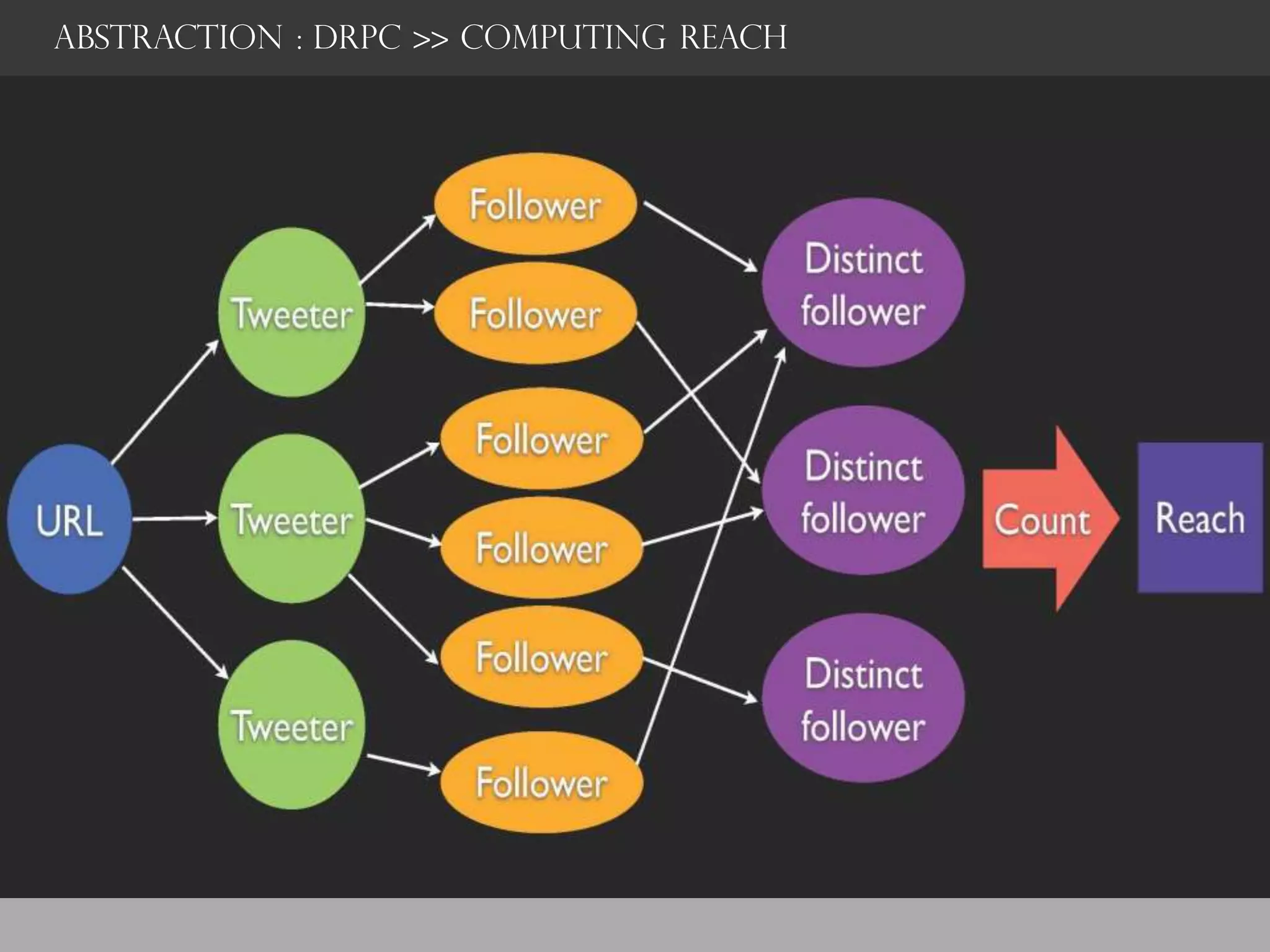
![ABSTRACTION : DRPC >> REACH TOPOLOGY
Spout - shuffle
["follower-id"]
+
global
t](https://image.slidesharecdn.com/stormsercppt-130715151410-phpapp02/75/Storm-Real-Time-Computation-43-2048.jpg)

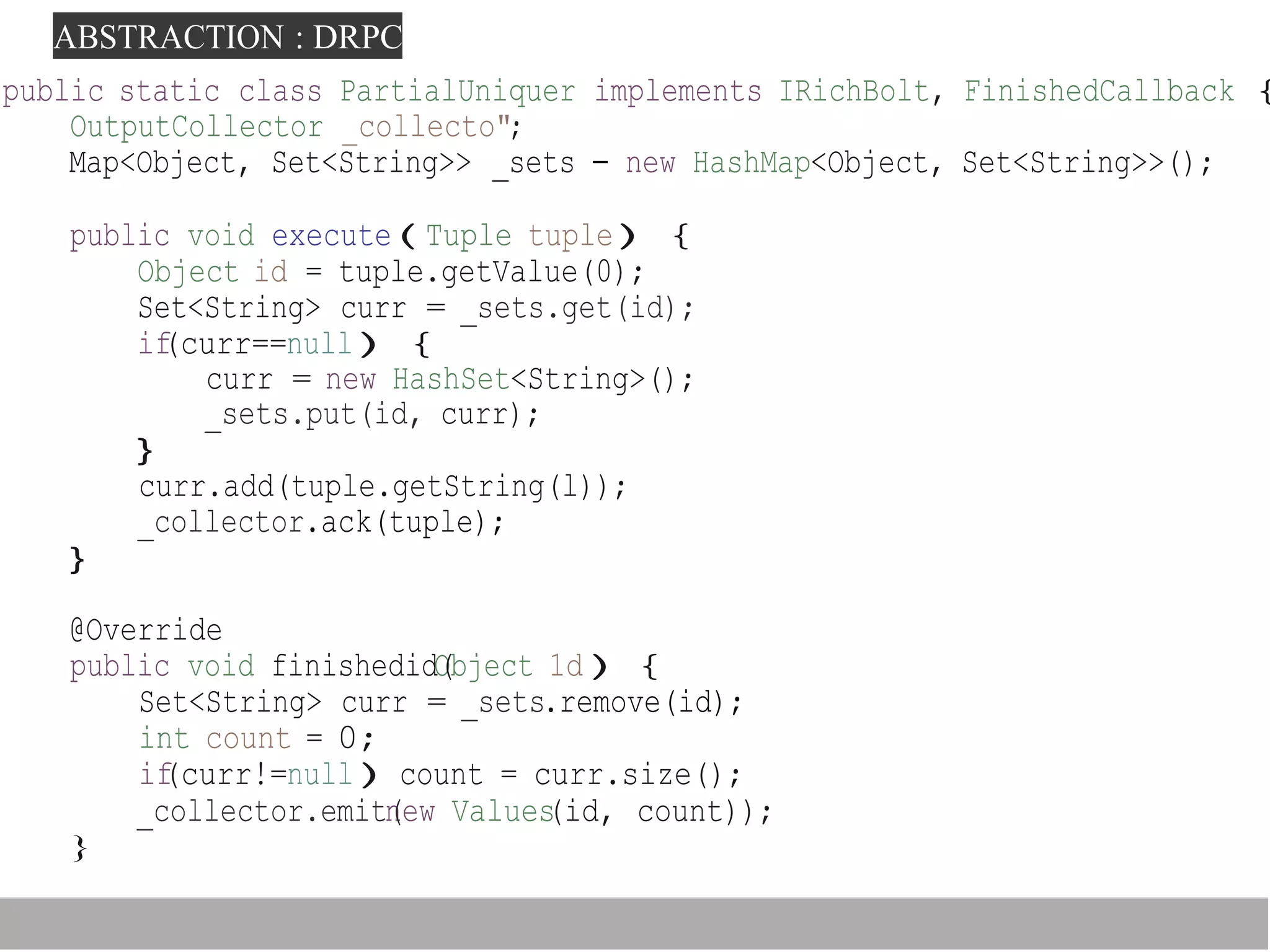
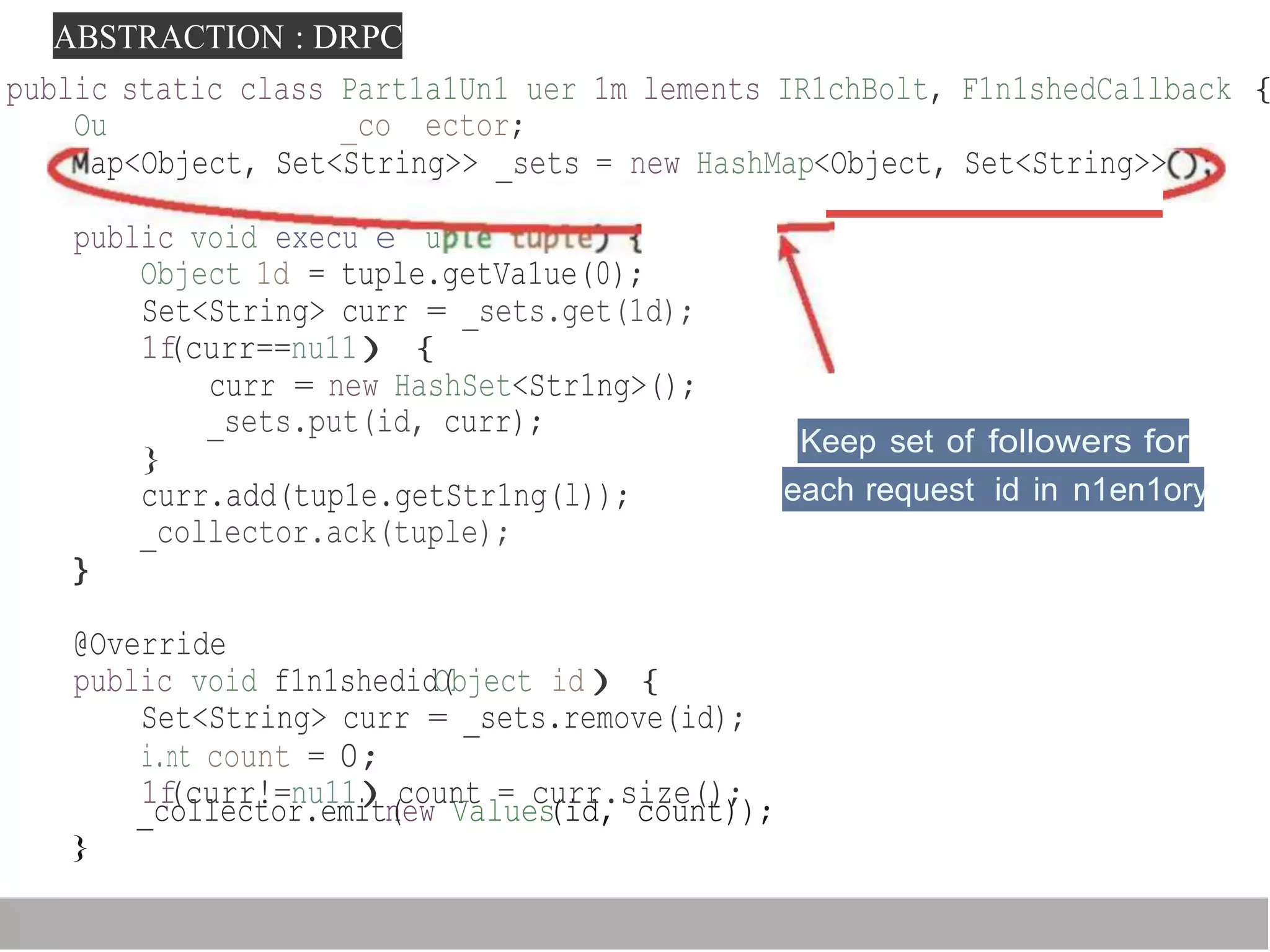
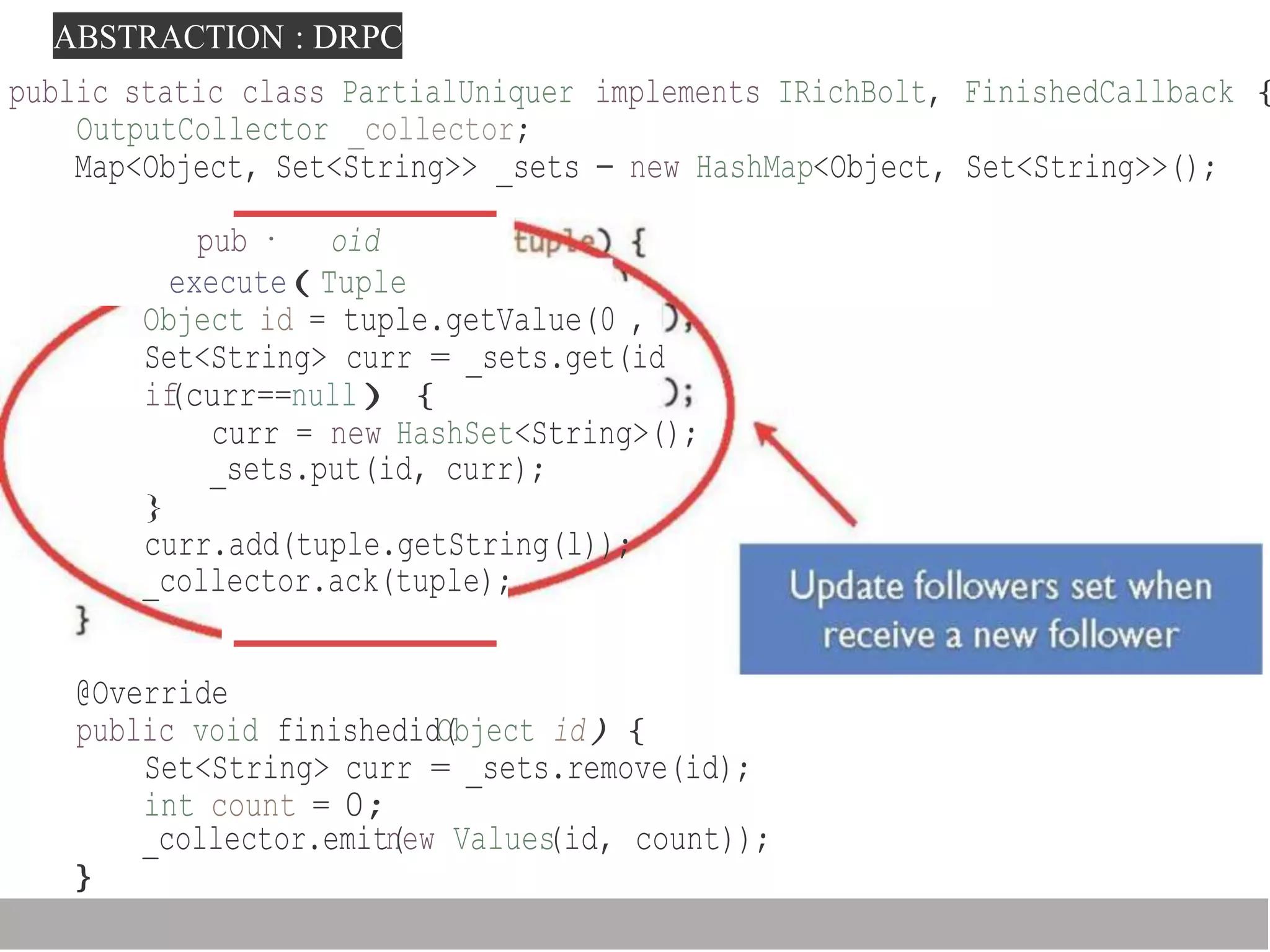

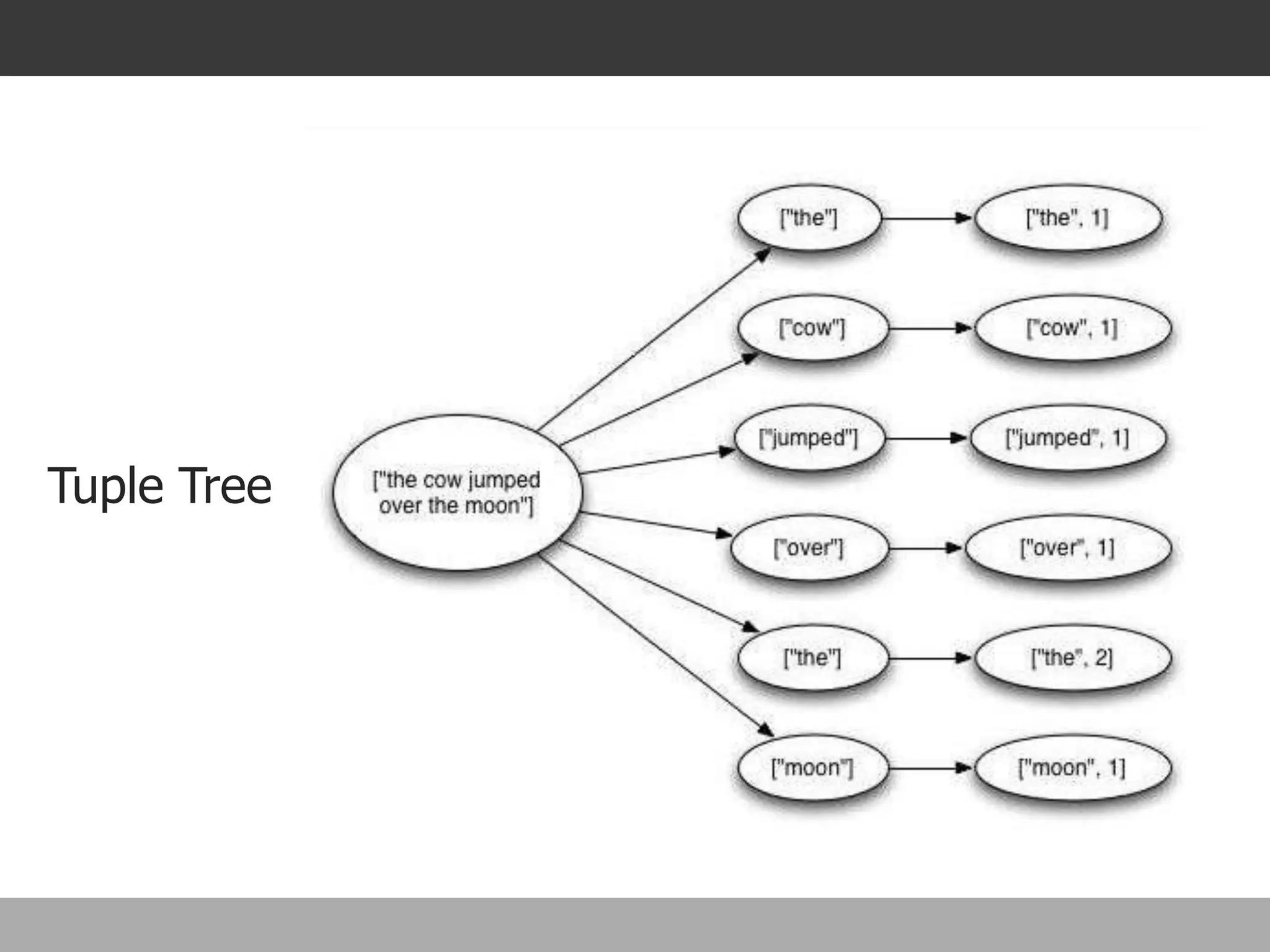






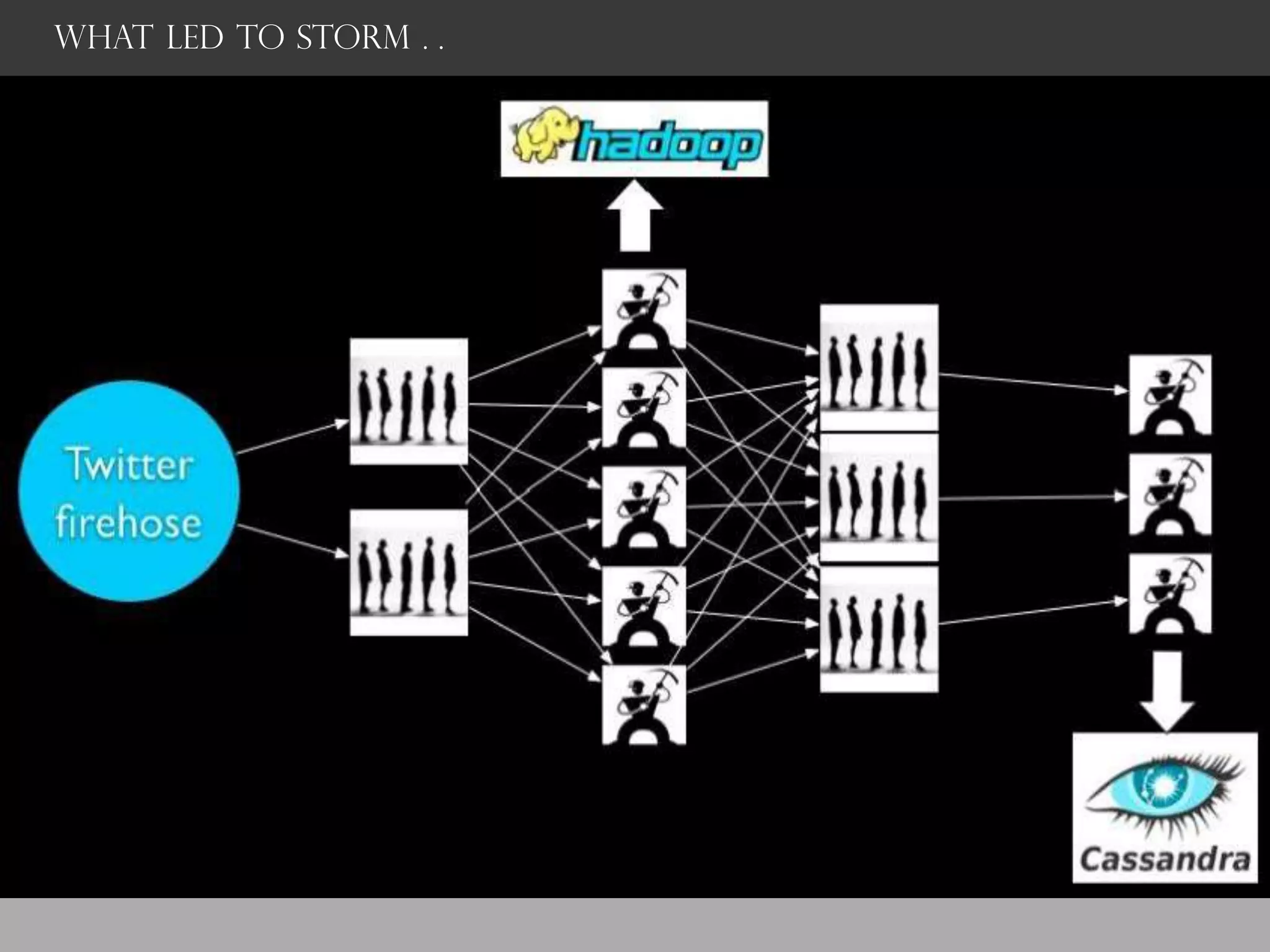
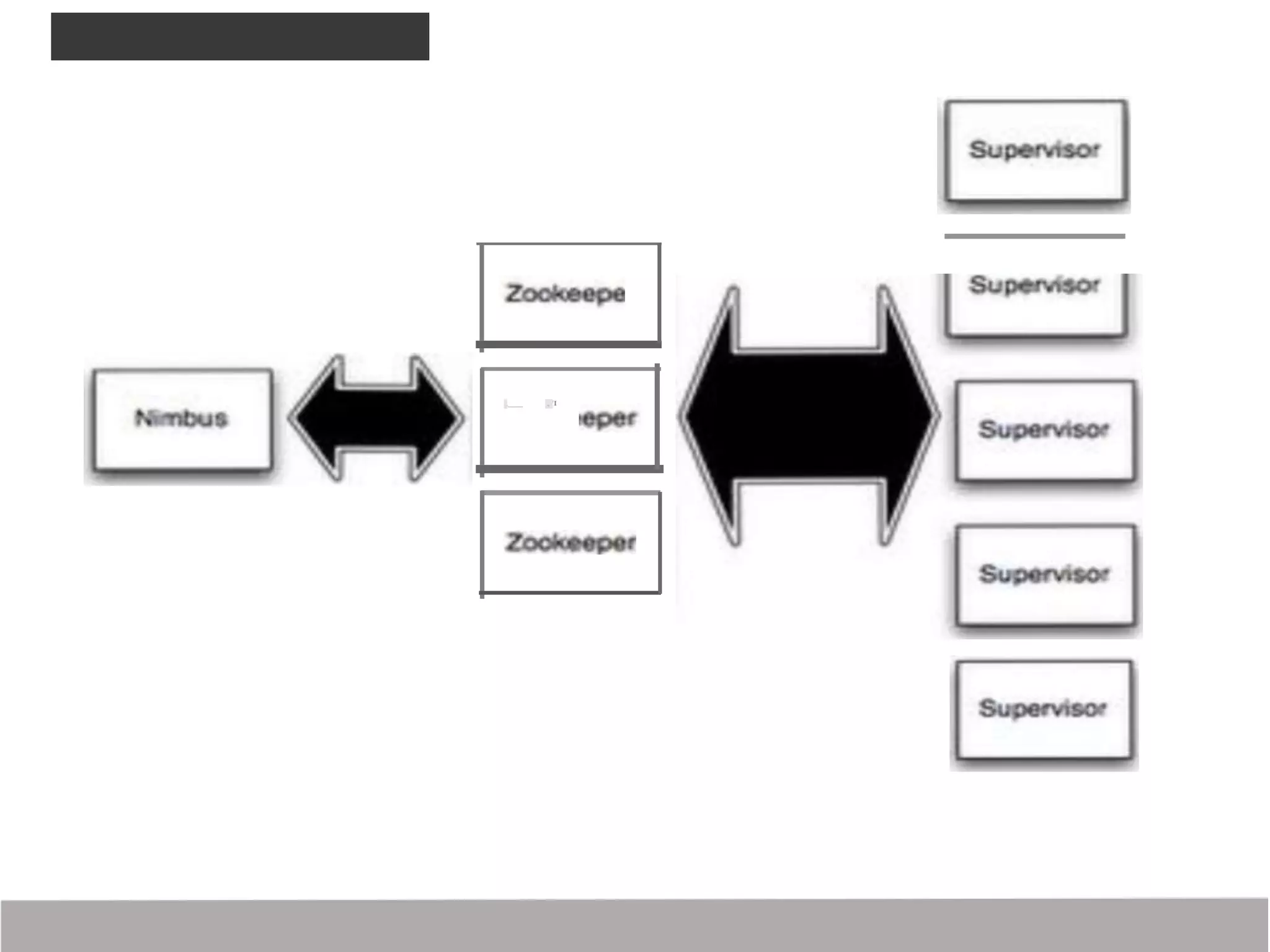
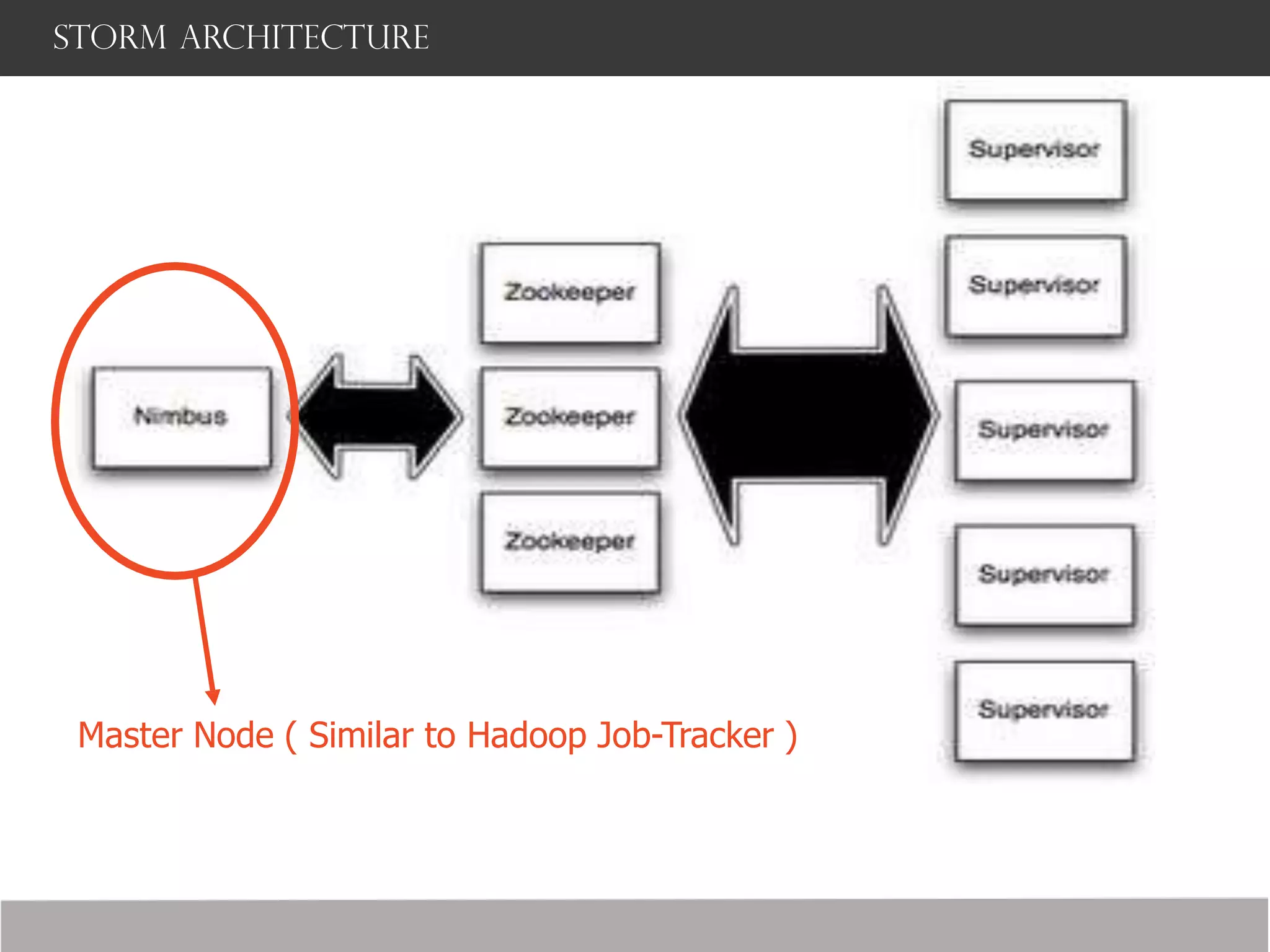
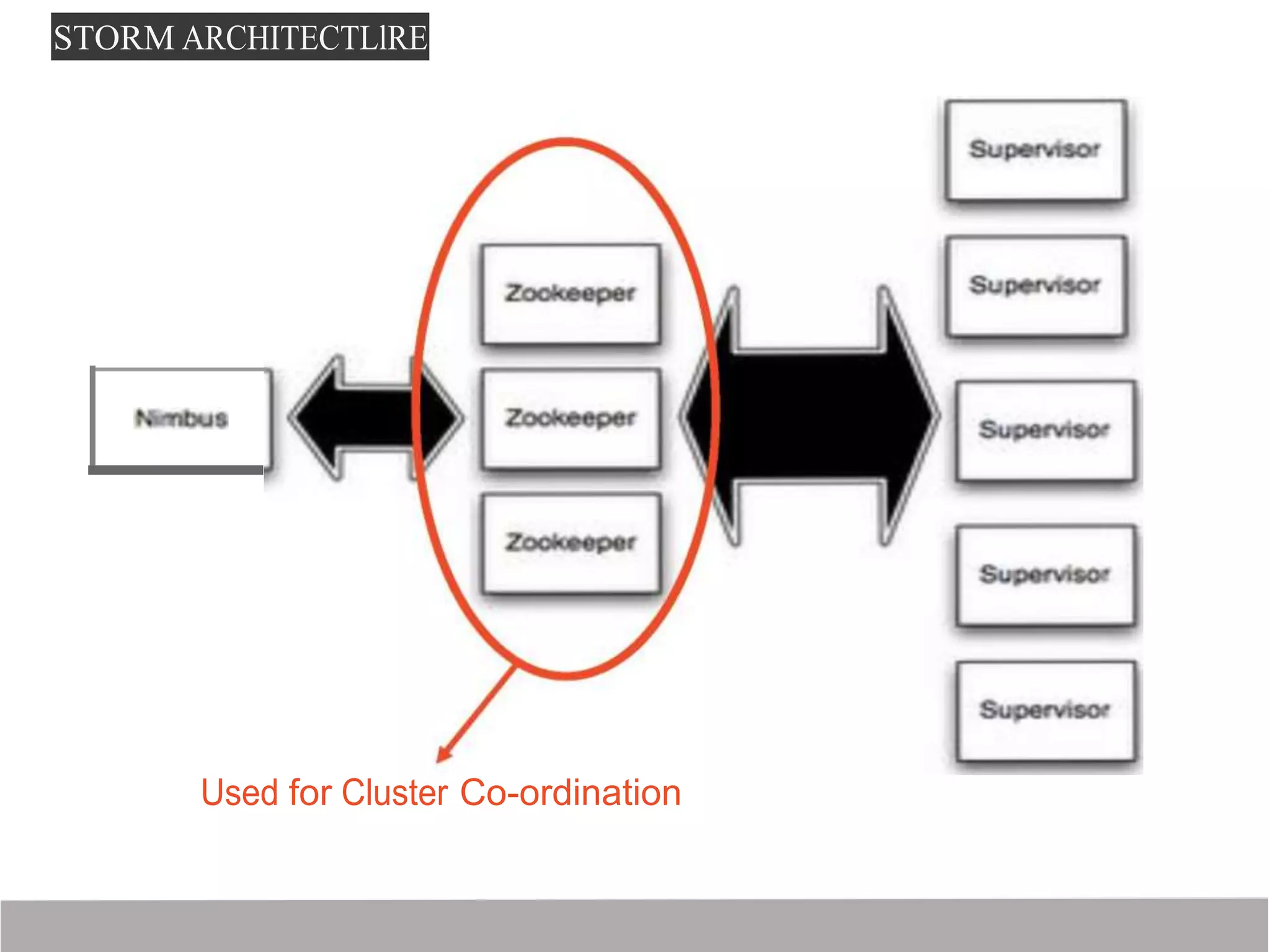
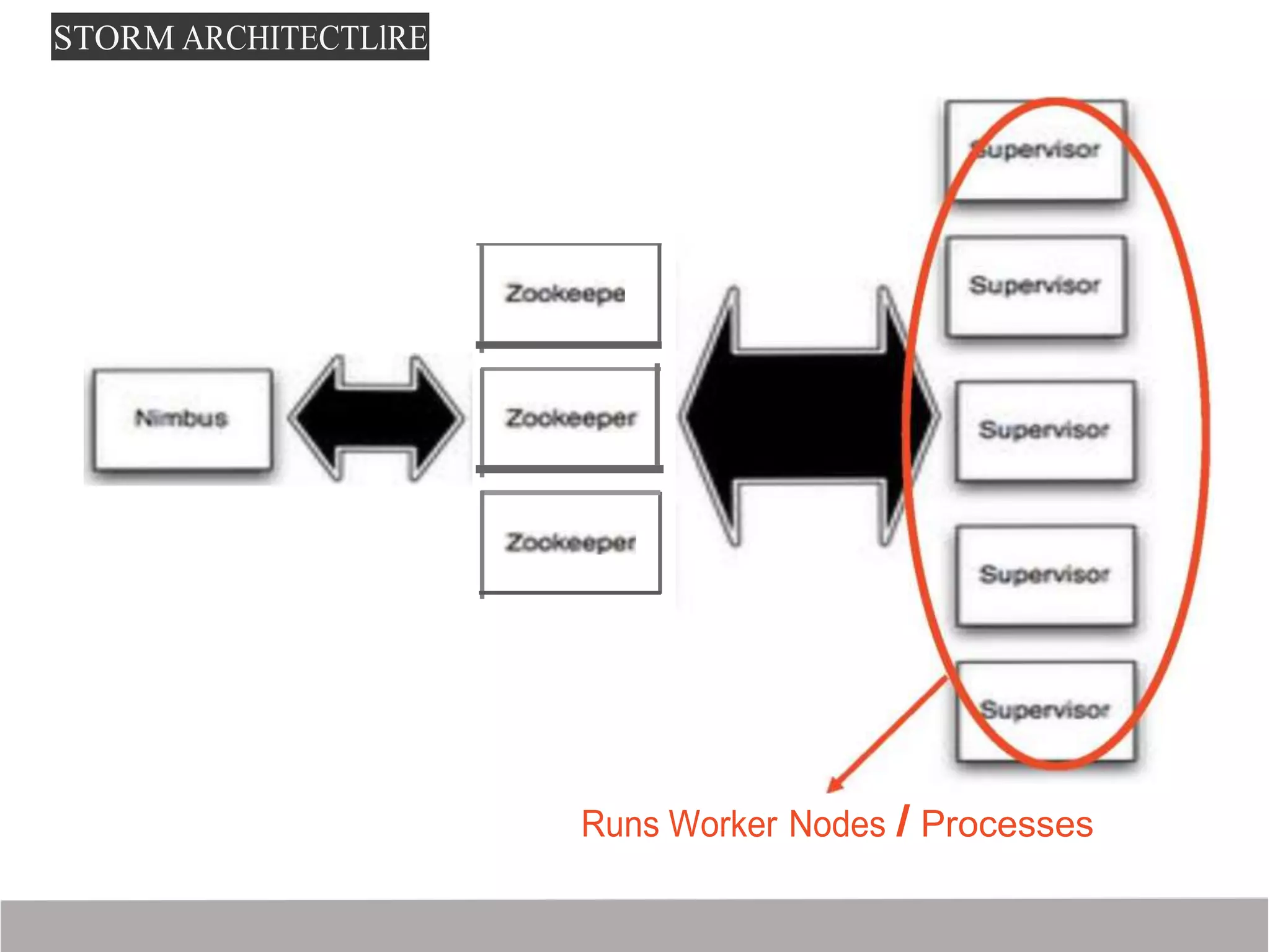
Storm is a distributed real-time computation framework created by Nathan Marz at BackType/Twitter to analyze tweets, links, and users on Twitter in real-time. It provides scalability, fault tolerance, and guarantees of data processing. Storm addresses problems with Hadoop like lack of real-time processing, long latency, and tedious coding through its stream processing capabilities and by being stateless. It has features like scalability, fault tolerance through Zookeeper, and guarantees of at least once processing.













































































