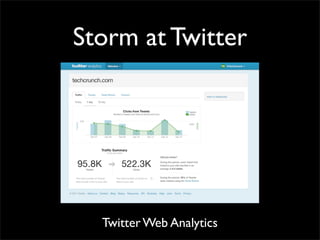
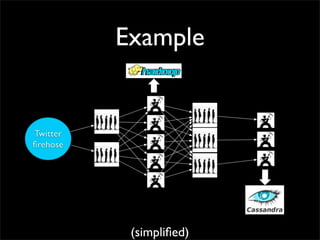
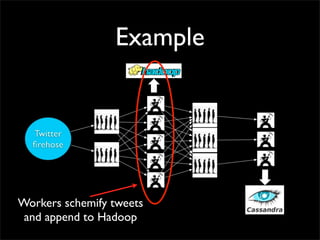
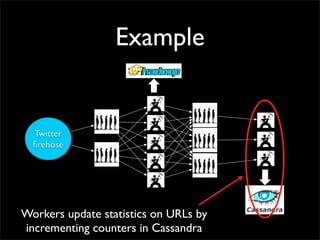
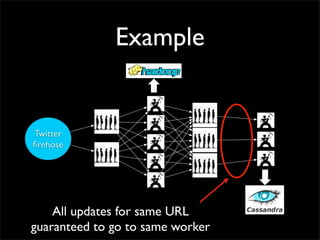
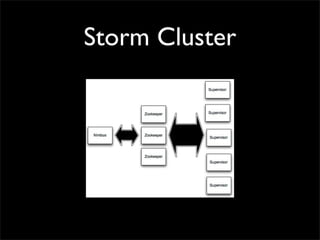
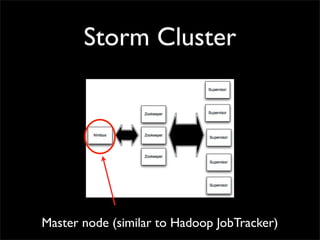
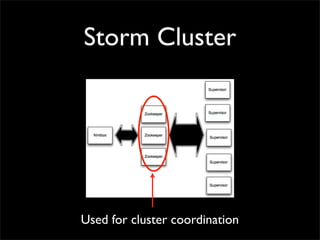
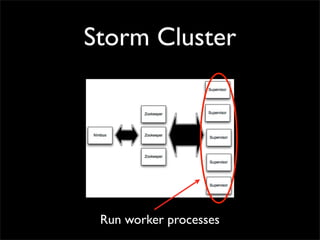
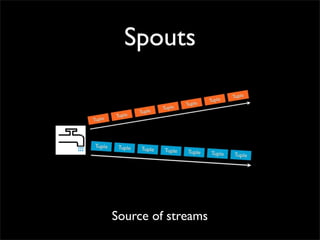
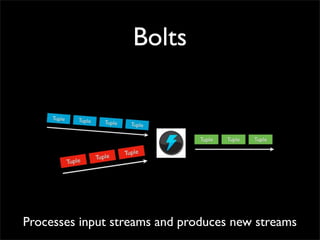
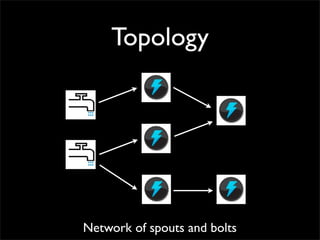
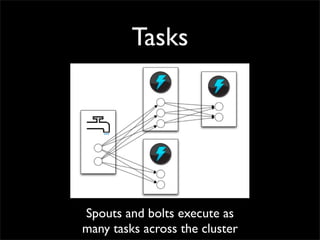
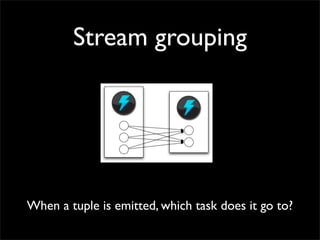
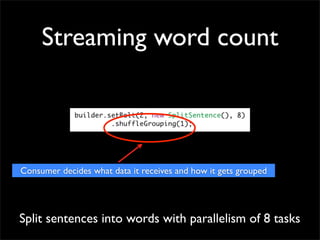
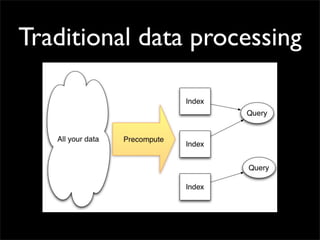
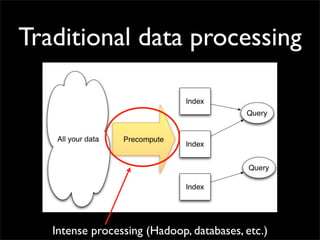
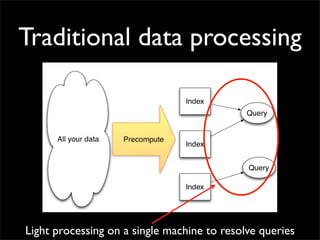
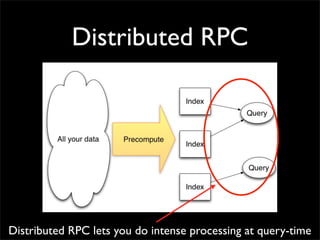
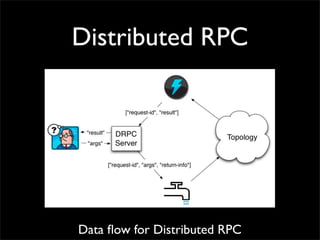
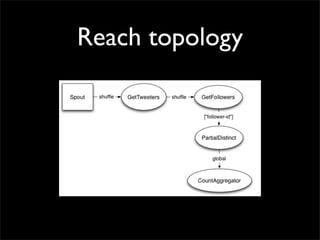
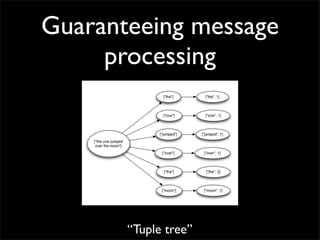
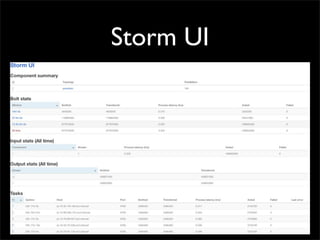
Storm is a distributed real-time computation system that provides guaranteed message processing, horizontal scalability, and fault tolerance. It allows users to define data processing topologies and submit them to a Storm cluster for distributed execution. Spouts emit streams of tuples that are processed by bolts. Storm tracks processing to ensure reliability and replays failed tasks. It provides tools for deployment, monitoring, and optimization of real-time data processing.



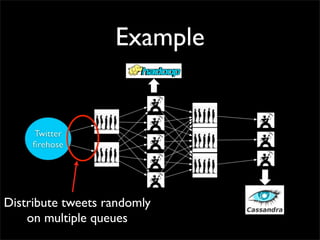
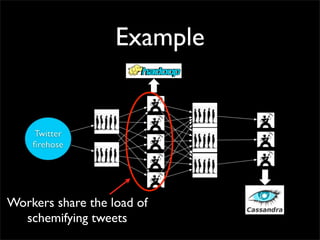
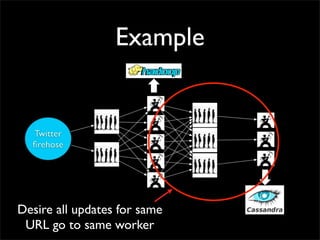


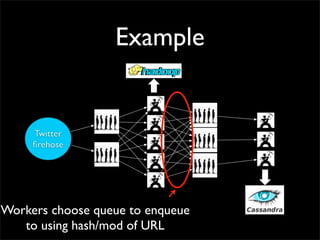











![Topology
shuffle [“id1”, “id2”]
shuffle
[“url”]
shuffle
all](https://image.slidesharecdn.com/storm-strange-loop-110920101342-phpapp01/85/Storm-distributed-and-fault-tolerant-realtime-computation-36-320.jpg)





























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









