Download to read offline







![Dispatching events with Quartz
Example 1
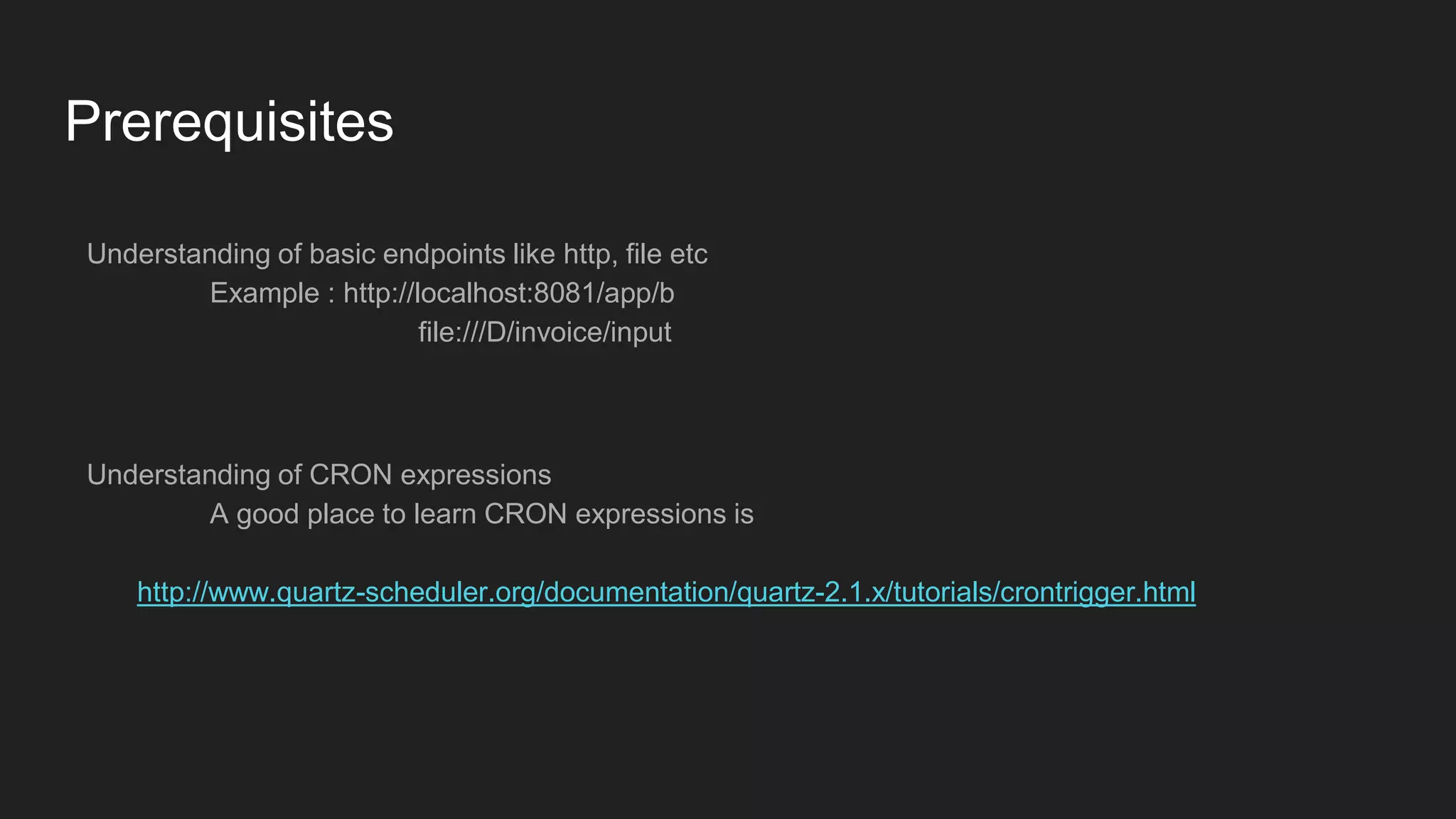
The below Quartz endpoint Invokes the job endpoint which is file i.e creates file several times according to
CRON expression that is starting at 01:43 PM at interval of 10 seconds till 01:43:50 PM
<file:endpoint path="./src/main/resources/output" name="File-Outbound-Endpoint" responseTimeout="10000"
doc:name="File"/> <flow name="quartz-schedule-dispatch-file">
<http:listener config-ref="HTTP_Listener_Configuration" path="/app/c" doc:name="HTTP"/>
<set-payload value="#['Payload for Dispatch !']" doc:name="Set Payload"/>
<quartz:outbound-endpoint jobName="FileDispatchJob" cronExpression="0/10 43 13 * * ?" connector-ref="Quartz"
responseTimeout="10000" doc:name="Quartz">
<quartz:scheduled-dispatch-job>
<quartz:job-endpoint ref="File-Outbound-Endpoint"/>
</quartz:scheduled-dispatch-job>
</quartz:outbound-endpoint>
</flow>](https://image.slidesharecdn.com/quartzconnector-160824212902/75/Quartz-connector-9-2048.jpg)


![We have to pass an instance of the created Quartz job and supply it to the Quartz endpoint as evaluator and the fully qualified name
of the created Quartz Job in the expression field. For this example i have passed evaluator from the Payload.
Example Snippet below:
<dw:transform-message doc:name="Transform Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
{
data: "Hello from Quartz!!"
} as :object {
class : "org.rahul.quartz.job.CustomQuartzJob"
}]]></dw:set-payload>
</dw:transform-message>
<quartz:outbound-endpoint jobName="customJob1" responseTimeout="10000" doc:name="Quartz" cronExpression="0/10 29 12
* * ?">
<quartz:custom-job-from-message evaluator="payload" expression="org.rahul.quartz.job.CustomQuartzJob" />
</quartz:outbound-endpoint>](https://image.slidesharecdn.com/quartzconnector-160824212902/75/Quartz-connector-12-2048.jpg)

The document provides an overview of the Quartz connector for scheduling programmatic events within Mule flows, discussing both inbound and outbound quartz endpoints. It includes examples of using cron expressions for polling files, generating events, and executing HTTP requests at specified intervals. Additionally, it covers creating custom Quartz jobs and provides links to resources for further learning about cron expressions and the Quartz connector.





























































































