














![Demo: Zombie Invasion Model
This is a lighthearted example, a system of ODEs(Ordinary differential equations) can be used to model a "zombie
invasion", using the equations specified by Philip Munz.
The system is given as:
dS/dt = P - B*S*Z - d*S
dZ/dt = B*S*Z + G*R - A*S*Z
dR/dt = d*S + A*S*Z - G*R
Where:
S: the number of susceptible victims
Z: the number of zombies
R: the number of people "killed”
P: the population birth rate
d: the chance of a natural death
B: the chance the "zombie disease" is transmitted (an alive person becomes a zombie)
G: the chance a dead person is resurrected into a zombie
A: the chance a zombie is totally destroyed
There are three scenarios given in the program to show how Zombie Apocalypse vary with different initial
conditions.
This involves solving a system of first order ODEs given by: dy/dt = f(y, t) Where y = [S, Z, R].
Slide 19 www.edureka.co/python](https://image.slidesharecdn.com/pythonwebinar1-141113233113-conversion-gate01/85/Webinar-Mastering-Python-An-Excellent-tool-for-Web-Scraping-and-Data-Analysis-19-320.jpg)



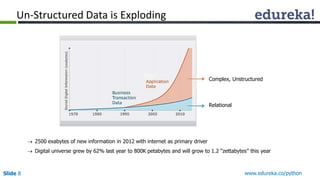
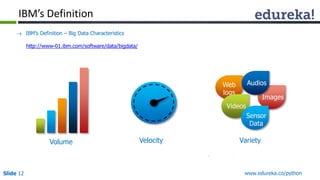
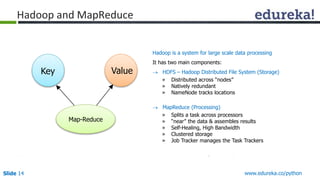
The document outlines a Python course for big data analytics, emphasizing its ease of use for beginners and robust libraries like Pydoop and SciPy. It covers practical applications such as web scraping, data analysis in healthcare, e-commerce, and modeling with Python, as well as the integration of Hadoop for large datasets. Additionally, it highlights Python's role in data science through its diverse libraries suitable for various data-related tasks.














































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)








































