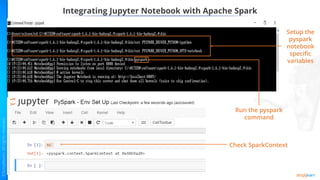
The document provides an overview of data science with Python and integrating Python with Hadoop and Apache Spark frameworks. It discusses:
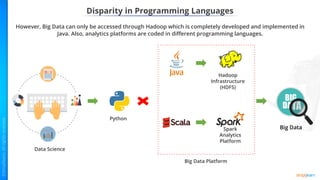
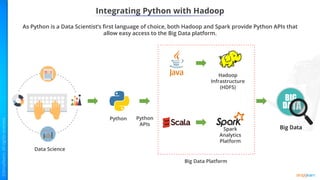
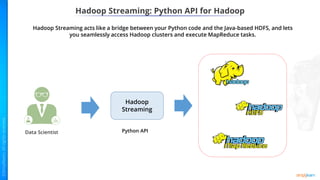
- Why Python should be integrated with Hadoop and the ecosystem including HDFS, MapReduce, and Spark.
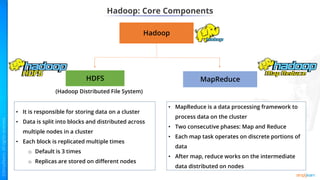
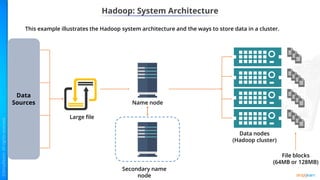
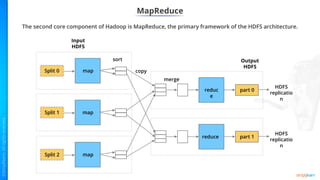
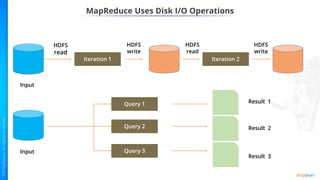
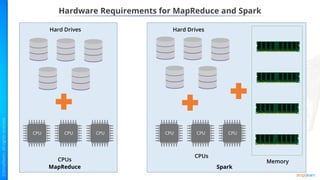
- Key concepts of Hadoop including HDFS for storage, MapReduce for processing, and how Python can be integrated via APIs.
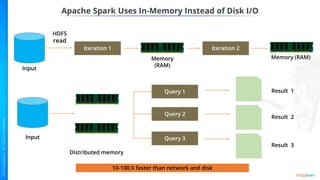
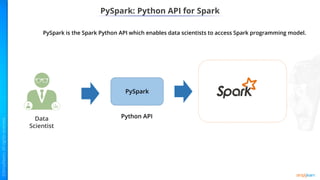
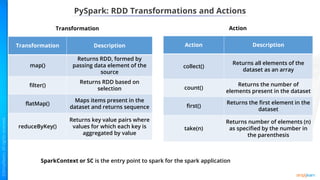
- Benefits of Apache Spark like speed, simplicity, and efficiency through its RDD abstraction and how PySpark enables Python access.
- Examples of using Hadoop Streaming and PySpark to analyze data and determine word counts from documents.








![Mapper in Python
Python supports map and reduce operations:
Suppose you have list of numbers you want
to square = [1, 2, 3, 4, 5, 6 ]
Square function is written as follows:
def square(num):
return num * num
You can square this list using the following code:
squared_nums = map(square, numbers)
Output would be:
[1, 4, 9, 16, 25, 36]](https://image.slidesharecdn.com/datasciencewithpythonlesson12pythonintegrationwithhadoop-231009133742-5a8ba5b4/85/Data-Science-16-320.jpg)
![Reducer in Python
Suppose you want to sum the squared numbers:
[1, 4, 9, 16, 25, 36]
Use the sum function to add two numbers
def sum(a, b ):
return a + b
You can now sum the numbers using the reduce function
Import functools as f
sum_squared = f. reduce(sum, a)
Output would be:
[91]](https://image.slidesharecdn.com/datasciencewithpythonlesson12pythonintegrationwithhadoop-231009133742-5a8ba5b4/85/Data-Science-17-320.jpg)

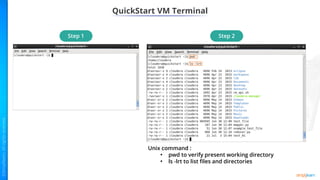




![Setting Up Environmental Variable of Apache Spark
[installed directory]spark-1.6.1-bin-
hadoop2.4spark-1.6.1-bin-hadoop2.4
[installed directory] spark-1.6.1-bin-
hadoop2.4spark-1.6.1-bin-
hadoop2.4bin](https://image.slidesharecdn.com/datasciencewithpythonlesson12pythonintegrationwithhadoop-231009133742-5a8ba5b4/85/Data-Science-33-320.jpg)