





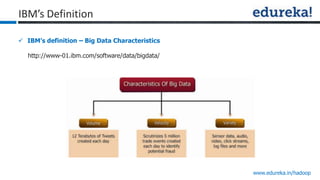

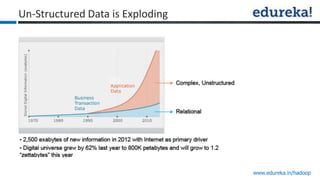
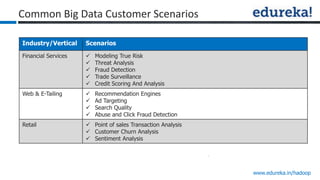
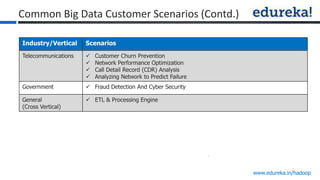


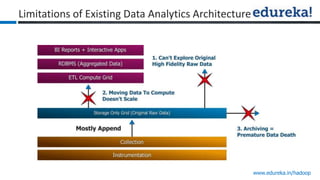
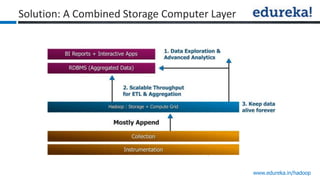


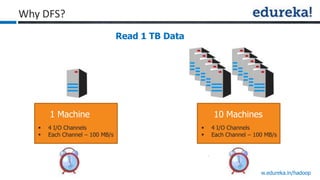
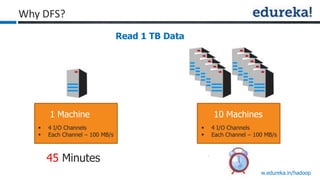
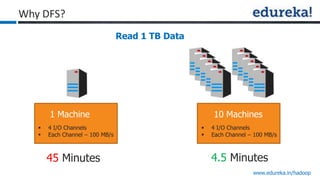

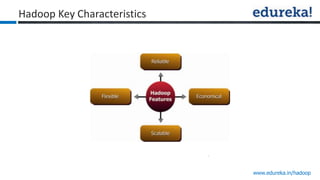
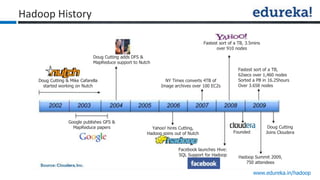
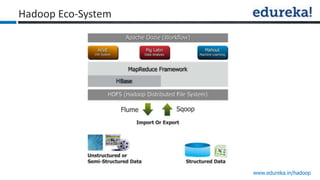

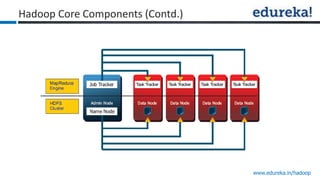
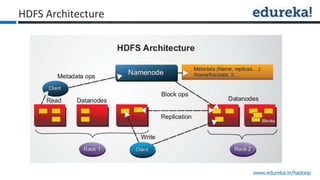

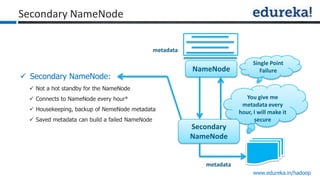

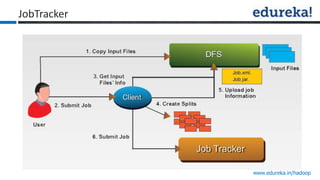
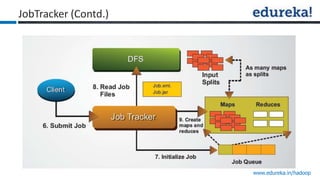
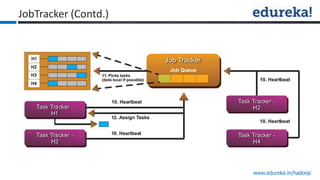
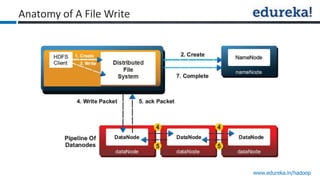
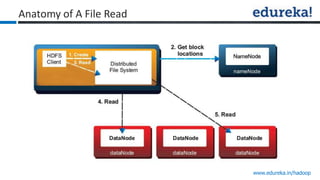
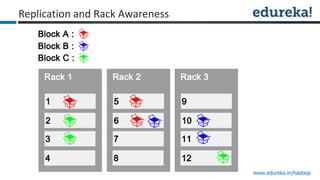
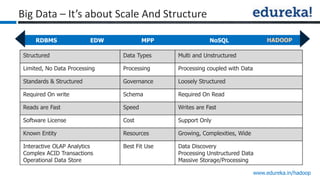



The document provides an overview of Edureka's Hadoop course, detailing weekly topics such as big data, HDFS, and data analytics tools like Pig and Hive, along with practical assignments and project work. It emphasizes the importance of big data across industries, showcasing its implications for competition and operational efficiency. Additionally, it outlines the Hadoop ecosystem, its core components, and its advantages in processing large datasets.





























































































