Downloaded 26 times




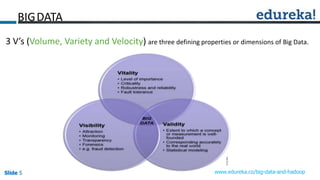

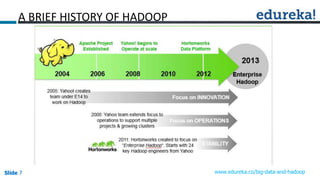








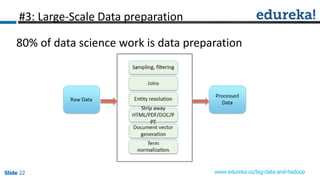

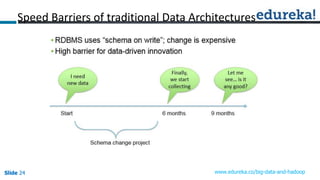
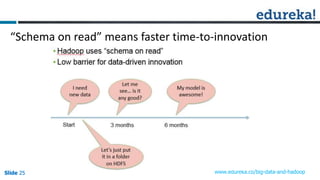





This document discusses big data, Hadoop, data science, and why Hadoop is useful for data science. It begins with defining big data and the 3 V's of big data. It then explains what Hadoop is and how it works using HDFS for storage and MapReduce for processing. The document defines what a data product is and provides examples. It defines data science as extracting meaning from data and building data products. Finally, it argues that Hadoop is useful for data science because it allows exploration of full datasets, mining of larger datasets, large-scale data preparation, and can accelerate data-driven innovation by removing speed barriers of traditional architectures.






























































































