Downloaded 25 times










![14
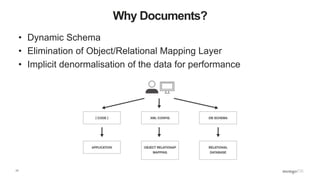
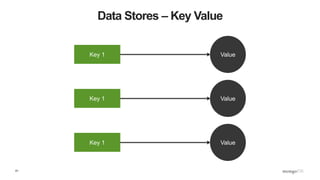
Document Store
• Not PDFs, Microsoft Word or HTML
• Documents are nested structures created using Javascript Object Notation (JSON)
{
name : “Joe Drumgoole”,
title : “Director of Developer Advocacy”,
Address : {
address1 : “Latin Hall”,
address2 : “Golden Lane”,
eircode : “D09 N623”,
}
expertise: [ “MongoDB”, “Python”, “Javascript” ],
employee_number : 320,
location : [ 53.34, -6.26 ]
}](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-14-320.jpg)
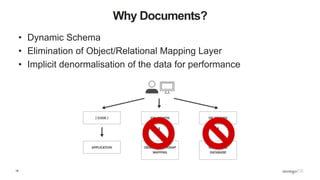
![15
MongoDB Documents are Typed
{
name : “Joe Drumgoole”,
title : “Director of Developer Advocacy”,
Address : {
address1 : “Latin Hall”,
address2 : “Golden Lane”,
eircode : “D09 N623”,
}
expertise: [ “MongoDB”, “Python”, “Javascript” ],
employee_number : 320,
location : [ 53.34, -6.26 ]
}
Strings
Nested Document
Array
Integer
Geo-spatial Coordinates](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-15-320.jpg)

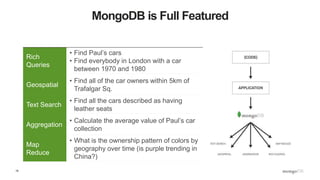

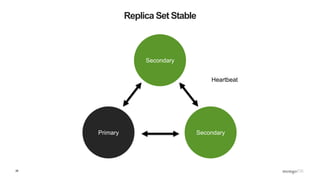

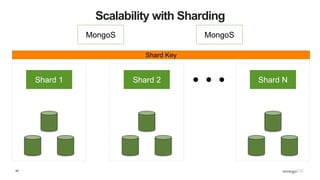


![32
Running Mongod
JD10Gen:mongodb jdrumgoole$ ./bin/mongod --dbpath /data/b2b
2016-05-23T19:21:07.767+0100 I CONTROL [initandlisten] MongoDB starting : pid=49209 port=27017 dbpath=/data/b2b 64-
bit host=JD10Gen.local
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] db version v3.2.6
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] git version: 05552b562c7a0b3143a729aaa0838e558dc49b25
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] allocator: system
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] modules: none
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] build environment:
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] distarch: x86_64
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] target_arch: x86_64
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] options: { storage: { dbPath: "/data/b2b" } }
2016-05-23T19:21:07.769+0100 I - [initandlisten] Detected data files in /data/b2b created by the 'wiredTiger'
storage engine, so setting the active storage engine to 'wiredTiger'.
2016-05-23T19:21:07.769+0100 I STORAGE [initandlisten] wiredtiger_open config:
create,cache_size=4G,session_max=20000,eviction=(threads_max=4),config_base=false,statistics=(fast),log=(enabled=true
,archive=true,path=journal,compressor=snappy),file_manager=(close_idle_time=100000),checkpoint=(wait=60,log_size=2GB)
,statistics_log=(wait=0),
2016-05-23T19:21:08.837+0100 I CONTROL [initandlisten]
2016-05-23T19:21:08.838+0100 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. Number of files is 256,
should be at least 1000
2016-05-23T19:21:08.840+0100 I NETWORK [HostnameCanonicalizationWorker] Starting hostname canonicalization worker
2016-05-23T19:21:08.840+0100 I FTDC [initandlisten] Initializing full-time diagnostic data capture with directory
'/data/b2b/diagnostic.data'
2016-05-23T19:21:08.841+0100 I NETWORK [initandlisten] waiting for connections on port 27017
2016-05-23T19:21:09.148+0100 I NETWORK [initandlisten] connection accepted from 127.0.0.1:59213 #1 (1 connection now
open)](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-32-320.jpg)
![33
Connecting Via The Shell
$ ./bin/mongo
MongoDB shell version: 3.2.6
connecting to: test
Server has startup warnings:
2016-05-17T11:46:03.516+0100 I CONTROL [initandlisten]
2016-05-17T11:46:03.516+0100 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. Number of
files is 256, should be at least 1000
>](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-33-320.jpg)



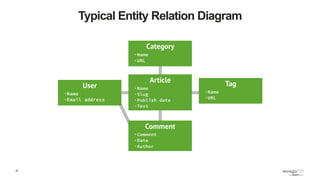

![39
How do we do this in a program?
'''
Created on 17 May 2016
@author: jdrumgoole
'''
import pymongo
#
# client defaults to localhost and port 27017. eg MongoClient('localhost', 27017)
client = pymongo.MongoClient()
blogDatabase = client[ "blog" ]
usersCollection = blogDatabase[ "users" ]
usersCollection.insert_one( { "username" : "jdrumgoole",
"password" : "top secret",
"lang" : "EN" })
user = usersCollection.find_one()
print( user )](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-39-320.jpg)
![40
Next up Articles
…
articlesCollection = blogDatabase[ "articles" ]
author = "jdrumgoole"
article = { "title" : "This is my first post",
"body" : "The is the longer body text for my blog post. We can add lots of text here.",
"author" : author,
"tags" : [ "joe", "general", "Ireland", "admin" ]
}
#
# Lets check if our author exists
#
if usersCollection.find_one( { "username" : author }) :
articlesCollection.insert_one( article )
else:
raise ValueError( "Author %s does not exist" % author )](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-40-320.jpg)
![41
Create a new type of article
#
# Lets add a new type of article with a posting date and a section
#
author = "jdrumgoole"
title = "This is a post on MongoDB"
newPost = { "title" : title,
"body" : "MongoDB is the worlds most popular NoSQL database. It is a document
database",
"author" : author,
"tags" : [ "joe", "mongodb", "Ireland" ],
"section" : "technology",
"postDate" : datetime.datetime.now(),
}
#
# Lets check if our author exists
#
if usersCollection.find_one( { "username" : author }) :
articlesCollection.insert_one( newPost )](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-41-320.jpg)
![42
Make a lot of articles 1
import pymongo
import string
import datetime
import random
def randomString( size, letters = string.letters ):
return "".join( [random.choice( letters ) for _ in xrange( size )] )
client = pymongo.MongoClient()
def makeArticle( count, author, timestamp ):
return { "_id" : count,
"title" : randomString( 20 ),
"body" : randomString( 80 ),
"author" : author,
"postdate" : timestamp }
def makeUser( username ):
return { "username" : username,
"password" : randomString( 10 ) ,
"karma" : random.randint( 0, 500 ),
"lang" : "EN" }](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-42-320.jpg)
![43
Make a lot of articles 2
blogDatabase = client[ "blog" ]
usersCollection = blogDatabase[ "users" ]
articlesCollection = blogDatabase[ "articles" ]
bulkUsers = usersCollection.initialize_ordered_bulk_op()
bulkArticles = articlesCollection.initialize_ordered_bulk_op()
ts = datetime.datetime.now()
for i in range( 1000000 ) :
#username = randomString( 10, string.ascii_uppercase ) + "_" + str( i )
username = "USER_" + str( i )
bulkUsers.insert( makeUser( username ) )
ts = ts + datetime.timedelta( seconds = 1 )
bulkArticles.insert( makeArticle( i, username, ts ))
if ( i % 500 == 0 ) :
bulkUsers.execute()
bulkArticles.execute()
bulkUsers = usersCollection.initialize_ordered_bulk_op()
bulkArticles = articlesCollection.initialize_ordered_bulk_op()
bulkUsers.execute()
bulkArticles.execute()](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-43-320.jpg)



![47
Update an Article to Add Comments 1
> db.articles.find( { "_id" : 19 } ).pretty()
{
"_id" : 19,
"body" :
"nTzOofOcnHKkJxpjKAyqTTnKZMFzzkWFeXtBRuEKsctuGBgWIrEBrYdvFIVHJWaXLUTVUXblOZZgUq
Wu",
"postdate" : ISODate("2016-05-23T12:02:46.830Z"),
"author" : "ASWTOMMABN_19",
"title" : "CPMaqHtAdRwLXhlUvsej"
}
> db.articles.update( { _id : 18 }, { $set : { comments : [] }} )
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-47-320.jpg)
![48
Update an article to add Comments 2
> db.articles.find( { _id :18 } ).pretty()
{
"_id" : 18,
"body" :
"KmwFSIMQGcIsRNTDBFPuclwcVJkoMcrIPwTiSZDYyatoKzeQiKvJkiVSrndXqrALVIYZxGpaMjucgX
UV",
"postdate" : ISODate("2016-05-23T16:04:39.497Z"),
"author" : "USER_18",
"title" : "wTLreIEyPfovEkBhJZZe",
"comments" : [ ]
}
>](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-48-320.jpg)
![49
Update an Article to Add Comments 3
> db.articles.update( { _id : 18 }, { $push : { comments : { username : "joe",
comment : "hey first post" }}} )
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.articles.find( { _id :18 } ).pretty()
{
"_id" : 18,
"body" :
"KmwFSIMQGcIsRNTDBFPuclwcVJkoMcrIPwTiSZDYyatoKzeQiKvJkiVSrndXqrALVIYZxGpaMjucgXUV"
,
"postdate" : ISODate("2016-05-23T16:04:39.497Z"),
"author" : "USER_18",
"title" : "wTLreIEyPfovEkBhJZZe",
"comments" : [
{
"username" : "joe",
"comment" : "hey first post"
}
]
}
>](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-49-320.jpg)


![52
Find a User
> db.users.find( { "username" : "ABOXHWKBYS_199" } ).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "blog.users",
"indexFilterSet" : false,
"parsedQuery" : {
"username" : {
"$eq" : "ABOXHWKBYS_199"
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"username" : {
"$eq" : "ABOXHWKBYS_199"
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "JD10Gen.local",
"port" : 27017,
"version" : "3.2.6",
"gitVersion" : "05552b562c7a0b3143a729aaa0838e558dc49b25"
},
"ok" : 1
}](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-52-320.jpg)





![58
Execution Stage
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"docsExamined" : 1,,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"keyPattern" : {
"username" : 1
},
"indexName" : "username_1",
"isMultiKey" : false,
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 1,
"direction" : "forward",
"indexBounds" : {
"username" : [
"["USER_999999", "USER_999999"]"
]
},
"keysExamined" : 1,
"seenInvalidated" : 0
}
}
}](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-58-320.jpg)

![60
Example Document
{
first_name: ‘Paul’,
surname: ‘Miller’,
cell: 447557505611,
city: ‘London’,
location: [45.123,47.232],
Profession: [‘banking’, ‘finance’, ‘trader’],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
]
}
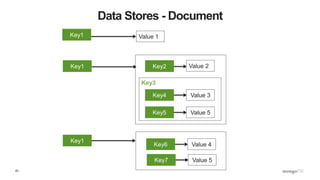
Fields can contain an array
of sub-documents
Fields
Typed field values
Fields can
contain arrays](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-60-320.jpg)




![68
One to Many
{
“Title” : “This is a blog post”,
“Body” : “This is the body text”,
“Comments” : [ { “name” : “Joe Drumgoole”,
“email” : “Joe.Drumgoole@mongodb.com”,
“comment” : “I love your writing style” },
{ “name” : “John Smith”,
“email” : “John.Smith@example.com”,
“comment” : “I hate your writing style” }]
}
Where we expect a small number of comments we can embed them
in the main document](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-68-320.jpg)

![70
Approach 2 – Separate Collection
• Keep all comments in a separate comments collection
• Add references to comments as an array of comment IDs
• Requires two queries to display blog post and associated comments
• Requires two writes to create a comments
{
_id : ObjectID( “AAAA” ),
name : “Joe Drumgoole”,
email : “Joe.Drumgoole@mongodb.com”,
comment :“I love your writing style”,
}
{
_id : ObjectID( “AAAB” ),
name : “John Smith”,
email : “Joe.Drumgoole@mongodb.com”,
comment :“I hate your writing style”,
}
{
“_id” : ObjectID( “ZZZZ” ),
“Title” : “A Blog Title”,
“Body” : “A blog post”,
“comments” : [ ObjectID( “AAAA” ),
ObjectID( “AAAB” )]
}
{
“_id” : ObjectID( “AZZZ” ),
“Title” : “A Blog Title”,
“Body” : “A blog post”,
“comments” : []
}](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-70-320.jpg)
![71
Approach 3 – A Hybrid Approach
{
“_id” : ObjectID( “ZZZZ” ),
“Title” : “A Blog Title”,
“Body” : “A blog post”,
“comments” : [{
“_id” : ObjectID( “AAAA” )
“name” : “Joe Drumgoole”,
“email” : “Joe.D@mongodb.com”,
comment :“I love your writing style”,
}
{
_id : ObjectID( “AAAB” ),
name : “John Smith”,
email : “Joe.Drumgoole@mongodb.com”,
comment :“I hate your writing style”,
}]
}
{
“_post_id” : ObjectID( “ZZZZ” ),
“comments” : [{
“_id” : ObjectID( “AAAA” )
“name” : “Joe Drumgoole”,
“email” : “Joe.D@mongodb.com”,
“comment” :“I love your writing
style”,
}
{...},{...},{...},{...},{...},{...}
,{..},{...},{...},{...} ]](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-71-320.jpg)
![72
What About One to A Million
• What is we were tracking mouse position for heat tracking?
– Each user will generate hundreds of data points per visit
– Thousands of data points per post
– Millions of data points per blog site
• Reverse the model
– Store a blog ID per event
{
“post_id” : ObjectID(“ZZZZ”),
“timestamp” : ISODate("2005-01-02T00:00:00Z”),
“location” : [24, 34]
“click” : False,
}](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-72-320.jpg)






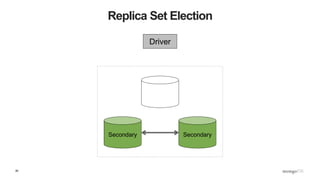
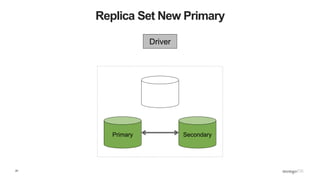

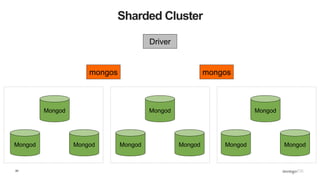
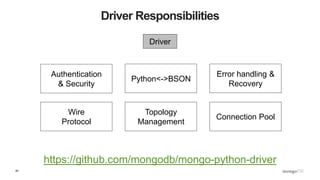
![86
Example API Calls
import pymongo
client = pymongo.MongoClient( host=“localhost”, port=27017)
database = client[ ‘test_database’ ]
collection = database[ ‘test_collection’ ]
collection.insert_one({ "hello" : "world" ,
"goodbye" : "world" } )
collection.find_one( { "hello" : "world" } )
collection.update({ "hello" : "world" },
{ "$set" : { "buenos dias" : "world" }} )
collection.delete_one({ "hello" : "world" } )](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-86-320.jpg)

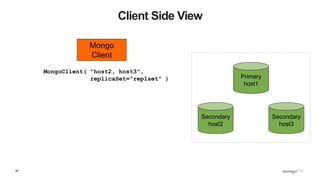
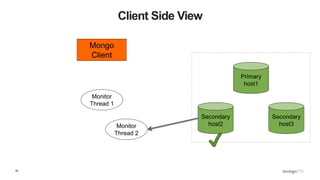
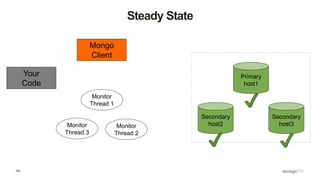
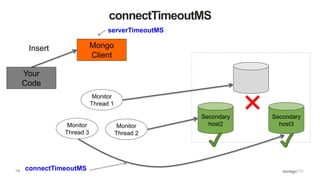
![89
Client Side View
Secondary
host2
Secondary
host3
Primary
host1
Mongo
Client
Monitor
Thread 1
Monitor
Thread 2
{ ismaster : False,
secondary: True,
hosts : [ host1, host2, host3 ] }](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-89-320.jpg)
![90
What Does ismaster show?
>>> pprint.pprint( db.command( "ismaster" ))
{u'hosts': [u'JD10Gen-old.local:27017',
u'JD10Gen-old.local:27018',
u'JD10Gen-old.local:27019'],
u'ismaster' : False,
u'secondary': True,
u'setName' : u'replset',
…}
>>>](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-90-320.jpg)
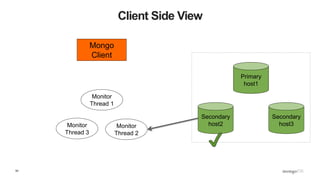
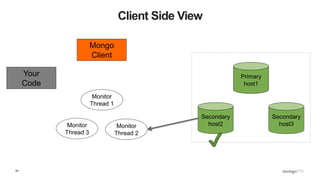

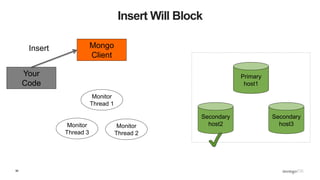
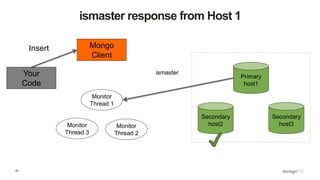
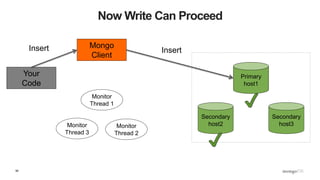
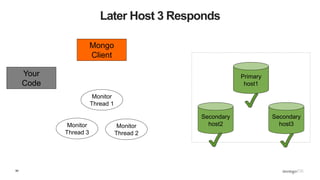
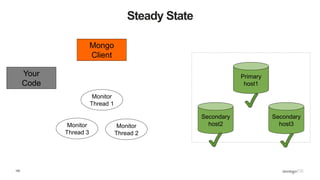
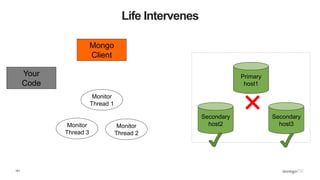
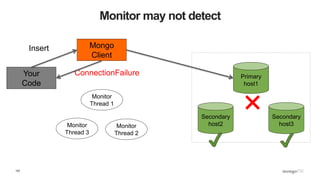
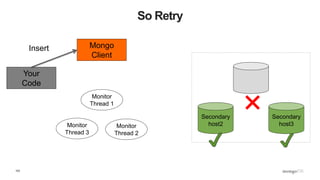
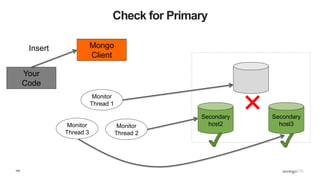
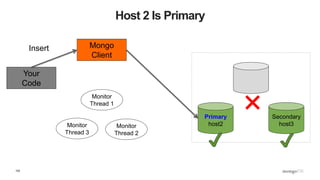


![109
What Does This Mean? - Inserts
def insert_with_recovery( collection, doc ) :
doc[ "_id" ] = ObjectId()
try:
collection.insert_one( doc )
except pymongo.errors.ConnectionFailure, e:
logging.info( "Connection error: %s" % e )
collection.insert_one( doc )
except DuplicateKeyError:
pass](https://image.slidesharecdn.com/python-ireland-2016-workshop-161106170635/85/Python-Ireland-Conference-2016-Python-and-MongoDB-Workshop-109-320.jpg)









This document provides an agenda and overview for a MongoDB and Python workshop. It begins with an introduction to NoSQL databases and MongoDB. It then covers how to install and run MongoDB, create a simple blog application to demonstrate working with MongoDB documents, and how to efficiently create large amounts of sample data. The document is intended to guide attendees through hands-on examples for getting started with MongoDB and developing applications using Python.


































































































