Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shoichi Taguchi
PPTX, PDF
3,233 views
Pydata_リクルートにおけるbanditアルゴリズム_実装前までのプロセス
Pydata_Tokyo#14でのスポンサーセッション banditアルゴリズムについて
Data & Analytics
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 22 times
1
/ 45
2
/ 45
3
/ 45
4
/ 45
5
/ 45
6
/ 45
7
/ 45
8
/ 45
9
/ 45
10
/ 45
11
/ 45
12
/ 45
13
/ 45
14
/ 45
15
/ 45
16
/ 45
17
/ 45
18
/ 45
19
/ 45
20
/ 45
21
/ 45
22
/ 45
23
/ 45
24
/ 45
25
/ 45
26
/ 45
27
/ 45
28
/ 45
29
/ 45
30
/ 45
31
/ 45
32
/ 45
33
/ 45
34
/ 45
35
/ 45
36
/ 45
37
/ 45
38
/ 45
39
/ 45
40
/ 45
41
/ 45
42
/ 45
43
/ 45
44
/ 45
45
/ 45
More Related Content
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PDF
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PPTX
OSS強化学習フレームワークの比較
by
gree_tech
PDF
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
バンディットアルゴリズム入門と実践
by
智之 村上
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
ゼロから始める転移学習
by
Yahoo!デベロッパーネットワーク
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
OSS強化学習フレームワークの比較
by
gree_tech
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
What's hot
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
「統計的学習理論」第1章
by
Kota Matsui
PDF
ブラックボックス最適化とその応用
by
gree_tech
PDF
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
PDF
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
PDF
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
PDF
4 データ間の距離と類似度
by
Seiichi Uchida
PDF
効果のあるクリエイティブ広告の見つけ方(Contextual Bandit + TS or UCB)
by
Yusuke Kaneko
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PDF
Control as Inference (強化学習とベイズ統計)
by
Shohei Taniguchi
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
時系列分析による異常検知入門
by
Yohei Sato
PDF
BERT+XLNet+RoBERTa
by
禎晃 山崎
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PDF
研究分野をサーベイする
by
Takayuki Itoh
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
「統計的学習理論」第1章
by
Kota Matsui
ブラックボックス最適化とその応用
by
gree_tech
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
4 データ間の距離と類似度
by
Seiichi Uchida
効果のあるクリエイティブ広告の見つけ方(Contextual Bandit + TS or UCB)
by
Yusuke Kaneko
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
強化学習 DQNからPPOまで
by
harmonylab
Control as Inference (強化学習とベイズ統計)
by
Shohei Taniguchi
Active Learning 入門
by
Shuyo Nakatani
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
時系列分析による異常検知入門
by
Yohei Sato
BERT+XLNet+RoBERTa
by
禎晃 山崎
グラフニューラルネットワーク入門
by
ryosuke-kojima
研究分野をサーベイする
by
Takayuki Itoh
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
Similar to Pydata_リクルートにおけるbanditアルゴリズム_実装前までのプロセス
PPTX
Pycon reject banditアルゴリズムを用いた自動abテスト
by
Shoichi Taguchi
PDF
L 05 bandit with causality-公開版
by
Shota Yasui
PDF
強化学習勉強会・論文紹介(第30回)Ensemble Contextual Bandits for Personalized Recommendation
by
Naoki Nishimura
PDF
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
PDF
finite time analysis of the multiarmed bandit problem
by
shima o
PDF
jubabanditの紹介
by
JubatusOfficial
PDF
A gang of bandit
by
Yoshifumi Seki
PDF
アドテクにおけるBandit Algorithmの活用
by
Komei Fujita
PDF
NIPS 2012 読む会
by
正志 坪坂
PPTX
確率的バンディット問題
by
jkomiyama
PPTX
最適腕識別と多重検定
by
Masa Kato
PPTX
バンディット問題について
by
jkomiyama
PDF
強化学習の実適用に向けた課題と工夫
by
Masahiro Yasumoto
PDF
Ml professional bandit_chapter1
by
Takeru Maehara
PDF
Large-Scale Bandit Problems and KWIK Learning
by
Junya Saito
PDF
Reliability and learnability of human bandit feedback for sequence to-seque...
by
ryoma yoshimura
PDF
バンディットアルゴリズム概論
by
Yoshinori Fukushima
PPTX
強化学習 sutton本 2章
by
ssuseraf8536
PPTX
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model (MuZero)
by
harmonylab
PPTX
A Generalist Agent
by
harmonylab
Pycon reject banditアルゴリズムを用いた自動abテスト
by
Shoichi Taguchi
L 05 bandit with causality-公開版
by
Shota Yasui
強化学習勉強会・論文紹介(第30回)Ensemble Contextual Bandits for Personalized Recommendation
by
Naoki Nishimura
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
finite time analysis of the multiarmed bandit problem
by
shima o
jubabanditの紹介
by
JubatusOfficial
A gang of bandit
by
Yoshifumi Seki
アドテクにおけるBandit Algorithmの活用
by
Komei Fujita
NIPS 2012 読む会
by
正志 坪坂
確率的バンディット問題
by
jkomiyama
最適腕識別と多重検定
by
Masa Kato
バンディット問題について
by
jkomiyama
強化学習の実適用に向けた課題と工夫
by
Masahiro Yasumoto
Ml professional bandit_chapter1
by
Takeru Maehara
Large-Scale Bandit Problems and KWIK Learning
by
Junya Saito
Reliability and learnability of human bandit feedback for sequence to-seque...
by
ryoma yoshimura
バンディットアルゴリズム概論
by
Yoshinori Fukushima
強化学習 sutton本 2章
by
ssuseraf8536
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model (MuZero)
by
harmonylab
A Generalist Agent
by
harmonylab
Pydata_リクルートにおけるbanditアルゴリズム_実装前までのプロセス
1.
リクルートにおける banditアルゴリズム 実装前までのプロセス 株式会社リクルートテクノロジーズ ITソリューション統括部 ビッグデータビジネスコンサルティンググループ 田口
正一
2.
2Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 自己紹介
3.
3Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 趣味etc 略歴 所属 氏名 RTC ITソリューション統括部 ビッグデータ部 ビッグデータビジネスコンサルティングG 田口 正一(たぐち しょういち) 前職:シンクタンク系SIer デフォルトリスク計量/ 与信最適化 @地銀(リテールローン) @携帯電話会社(ペイメントサービス) 11月RTC 入社 サッカー・キャンプ・ゲーム 自己紹介
4.
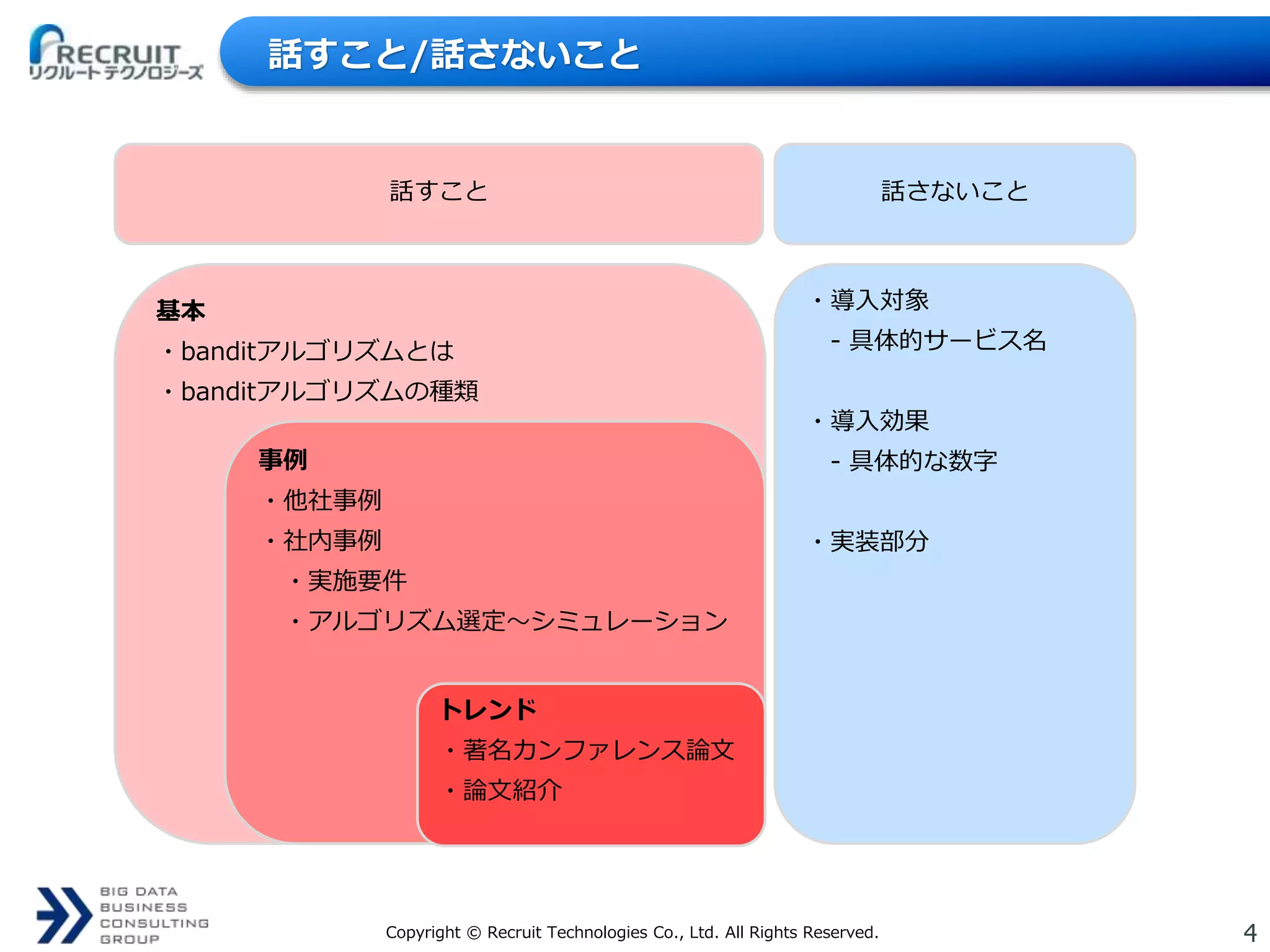
4Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 話すこと/話さないこと 基本 ・banditアルゴリズムとは ・banditアルゴリズムの種類 事例 ・他社事例 ・社内事例 ・実施要件 ・アルゴリズム選定〜シミュレーション トレンド ・著名カンファレンス論文 ・論文紹介 ・導入対象 - 具体的サービス名 ・導入効果 - 具体的な数字 ・実装部分 話すこと 話さないこと
5.
5Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. リクルートについて
6.
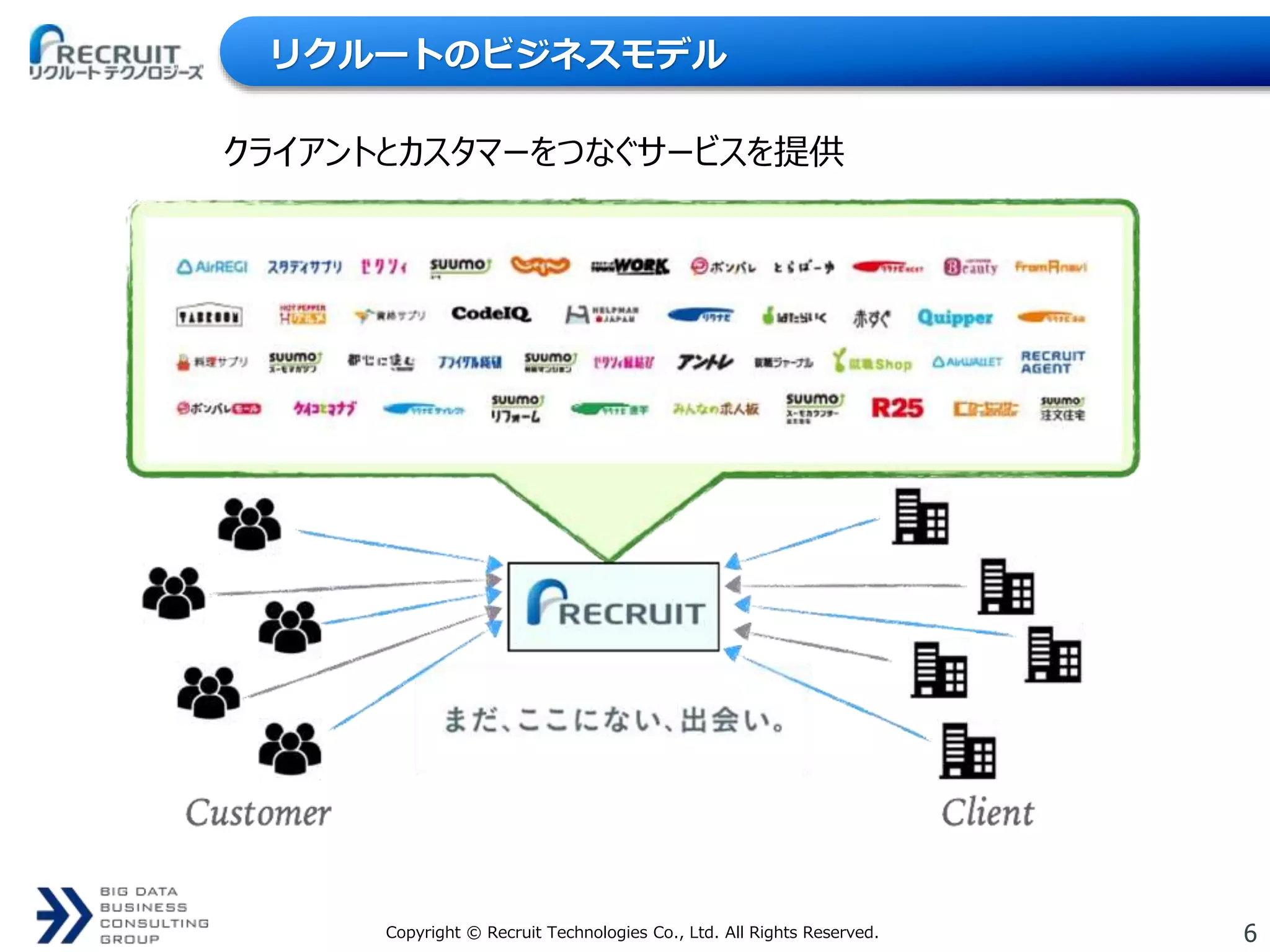
6Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. リクルートのビジネスモデル クライアントとカスタマーをつなぐサービスを提供
7.
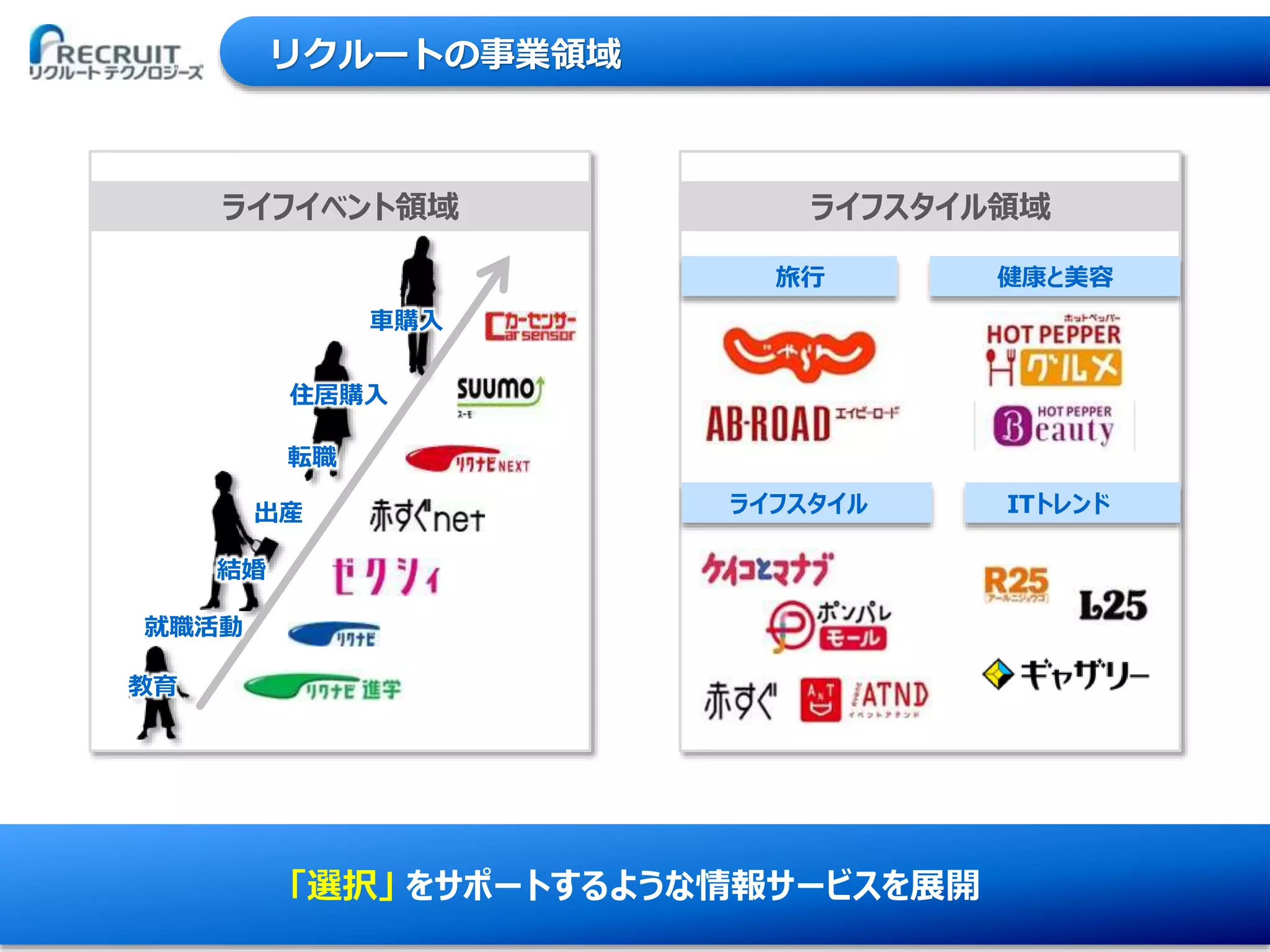
7Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. リクルートの事業領域 「選択」 をサポートするような情報サービスを展開 ライフイベント領域 ライフスタイル領域 旅行 ITトレンドライフスタイル 健康と美容 就職活動 結婚 転職 住居購入 車購入 出産 教育
8.
8Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. リクルートテクノロジーズの立ち位置 リクルートホールディングスは7つの主要事業会社と3つの機能会社から成り立っている。 Infrastructure Large project promotions UI design/SEO Big Data Department Technology R&D IT Promotion Recruit Holdings Recruit Career Recruit Sumai Company Recruit Lifestyle Recruit Jobs Recruit Staffing Recruit Marketing Partners Staff service Holdings Recruit Technologies Recruit Administration Recruit Communications Operation Service
9.
9Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. ビッグデータ解析部門の組織体制 ビジネス コンサルティング グループ 人材領域グループ 販促・バイト領域 グループ ソリューションを 軸とした予測、 BI、競合分析 人材領域を軸とした 各種レコメンドの 開発 販促・バイトを 軸とした各種 レコメンドの開発 ID・ポイント領域 グループ IDポイントを 軸とした各種 レコメンドの開発 プロダクト開発 グループ インフラグループ IDポイント ビッグデータシステムグルー プ ソリューションを 軸とした各種R&D系 プロダクトの開発 ビックデータ基盤の 構築・運用 IDポイントPRJの 基盤の構築・運用 ビックデータ部
10.
10Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. banditアルゴリズムとは
11.
11Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 環境モデル、長期報酬を考慮しない強化学習 強化学習 banditアルゴリズム 価値関数(長期報酬) 報酬関数(短期報酬) 方策 環境モデル ○ × ○ ○ ○ ○ ○ × 構成要素 出典:強化学習
12.
12Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 持ち金を増やしたい スロットマシンを相手にする@ラスベガス
13.
13Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 持ち金を増やしたい 情報がなければ合理的な選択は不可能 期待 報酬 p1 p2 p3 p4 結局どれがいいの さ・・・
14.
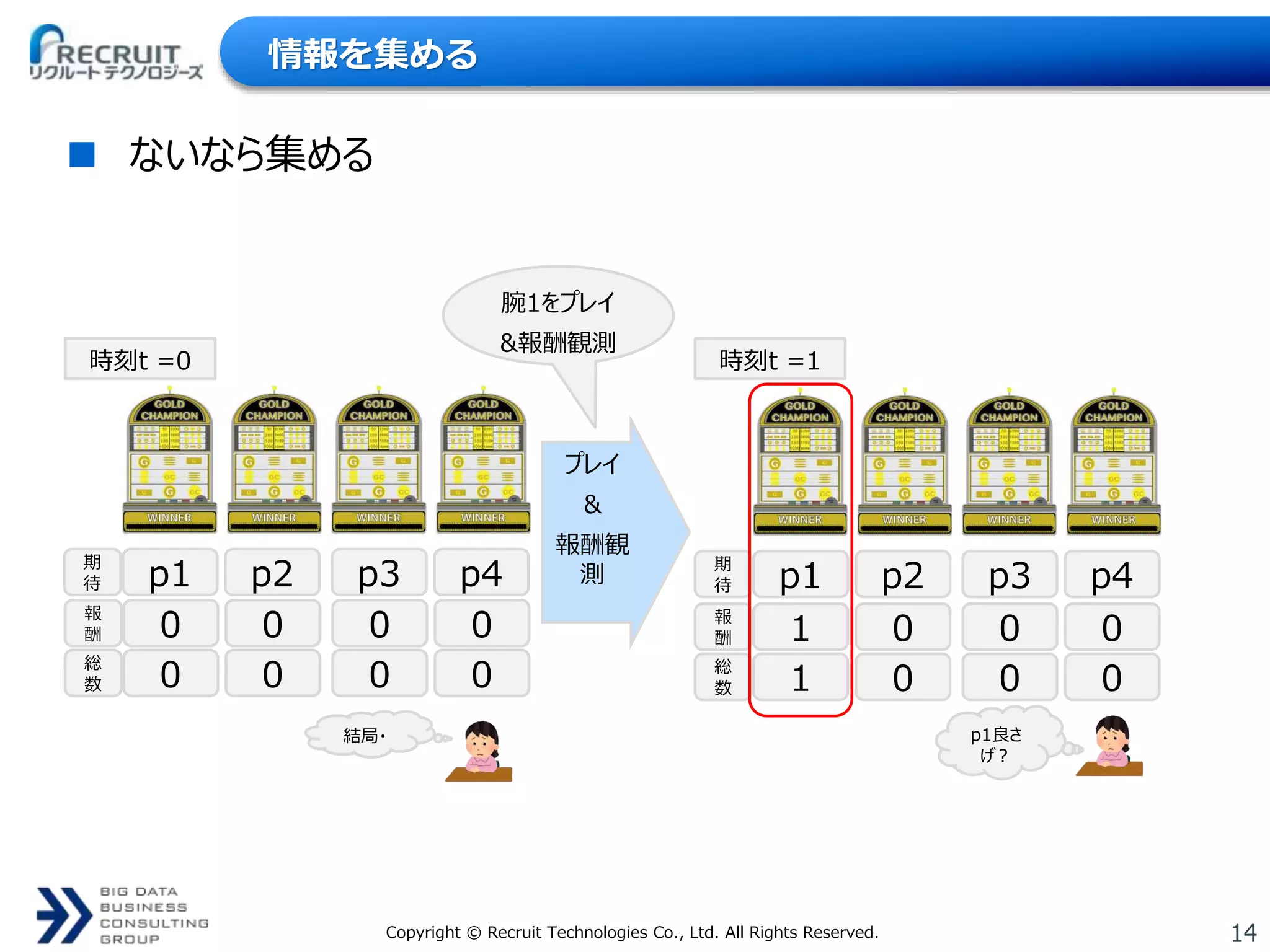
14Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 情報を集める ないなら集める 期 待 p1 p2 p3 p4 結局・ 期 待 p1 p2 p3 p4 p1良さ げ? 時刻t =0 時刻t =1 プレイ & 報酬観 測 腕1をプレイ &報酬観測 報 酬 0 0 0 0 総 数 0 0 0 0 報 酬 1 0 0 0 総 数 1 0 0 0
15.
15Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 情報を集める 期待値に基づいてのプレイが基本方針 期 待 p1 p2 p3 p4 P4最大 期 待 p1 p2 p3 p4 p3最大になった 次はp3か・・・ 時刻t 時刻t +1 プレイ & 報酬観 測 腕4をプレイ &報酬観測 報 酬 r1 r2 r3 r4 総 数 s1 s2 s3 s4 報 酬 r1 r2 r3 r4 総 数 s1 s2 s3 s4+ 1
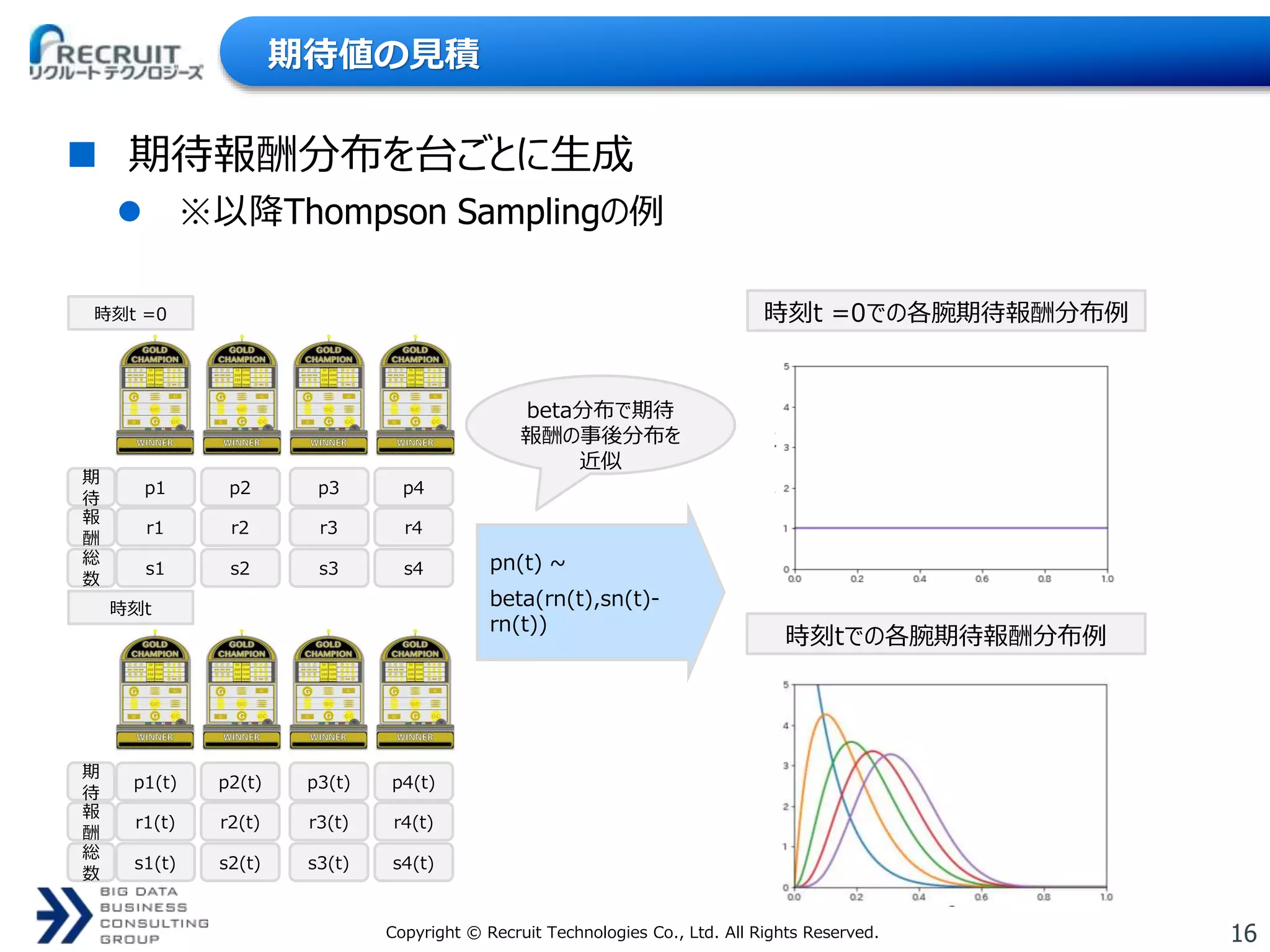
16.
16Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 期待値の見積 期待報酬分布を台ごとに生成 ※以降Thompson Samplingの例 時刻t =0での各腕期待報酬分布例 時刻tでの各腕期待報酬分布例 期 待 p1 p2 p3 p4 時刻t =0 報 酬 r1 r2 r3 r4 総 数 s1 s2 s3 s4 期 待 p1(t) p2(t) p3(t) p4(t) 時刻t 報 酬 r1(t) r2(t) r3(t) r4(t) 総 数 s1(t) s2(t) s3(t) s4(t) beta分布で期待 報酬の事後分布を 近似 pn(t) ~ beta(rn(t),sn(t)- rn(t))
17.
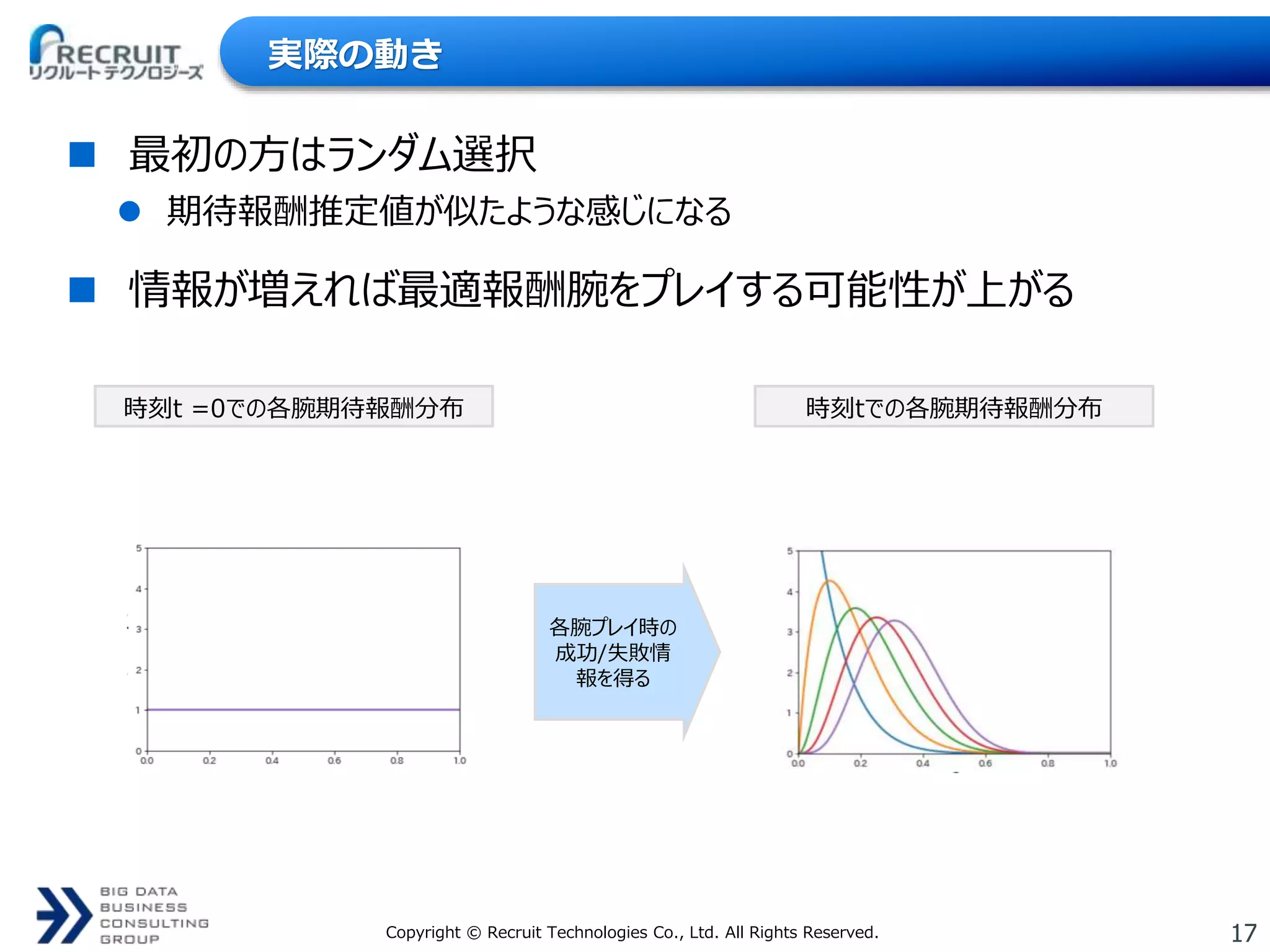
17Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 実際の動き 最初の方はランダム選択 期待報酬推定値が似たような感じになる 情報が増えれば最適報酬腕をプレイする可能性が上がる 時刻t =0での各腕期待報酬分布 時刻tでの各腕期待報酬分布 各腕プレイ時の 成功/失敗情 報を得る
18.
18Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 評価指標 Regret = Σ(最適腕の報酬 – 実プレイした腕の報酬) Regretの最小化を目指す グラフ出典:DataOrigami https://dataorigami.net/blogs/napkin-folding/79031811-multi-armed-bandits 最初は探索的に色々な腕をプ レイするので、Regretが急上 昇 ある程度時間が経つと最適選 択をする可能性が高まり、 Regretの成長は鈍化 ランダム探索よりはるかにマシ
19.
19Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. banditアルゴリズムの種類 banditアルゴリズムは様々存在する
20.
20Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 事例紹介
21.
21Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 他社事例 楽天 Cookpad yahoo MSN, LinkedIn
22.
22Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 他社事例 楽天 スーパーセール 成約率5%向上 出典: http://business.nikkeibp.co.jp/atclbdt/15/258673/070400266/?n_cid=
23.
23Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 他社事例 Cookpad contextual banditらしい 対探索時でCTR160% 出典: http://techlife.cookpad.com/entry/2014/10/29/
24.
24Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 他社事例 yahoo STORY部分にF1~F4のどれを出す? LinUCB(disjoint,hybrid)を用いた ε-greedyと比較してCTRが2倍以上 • hybridは早く学べる • disjointは伸びしろあり
25.
25Copyright © Recruit
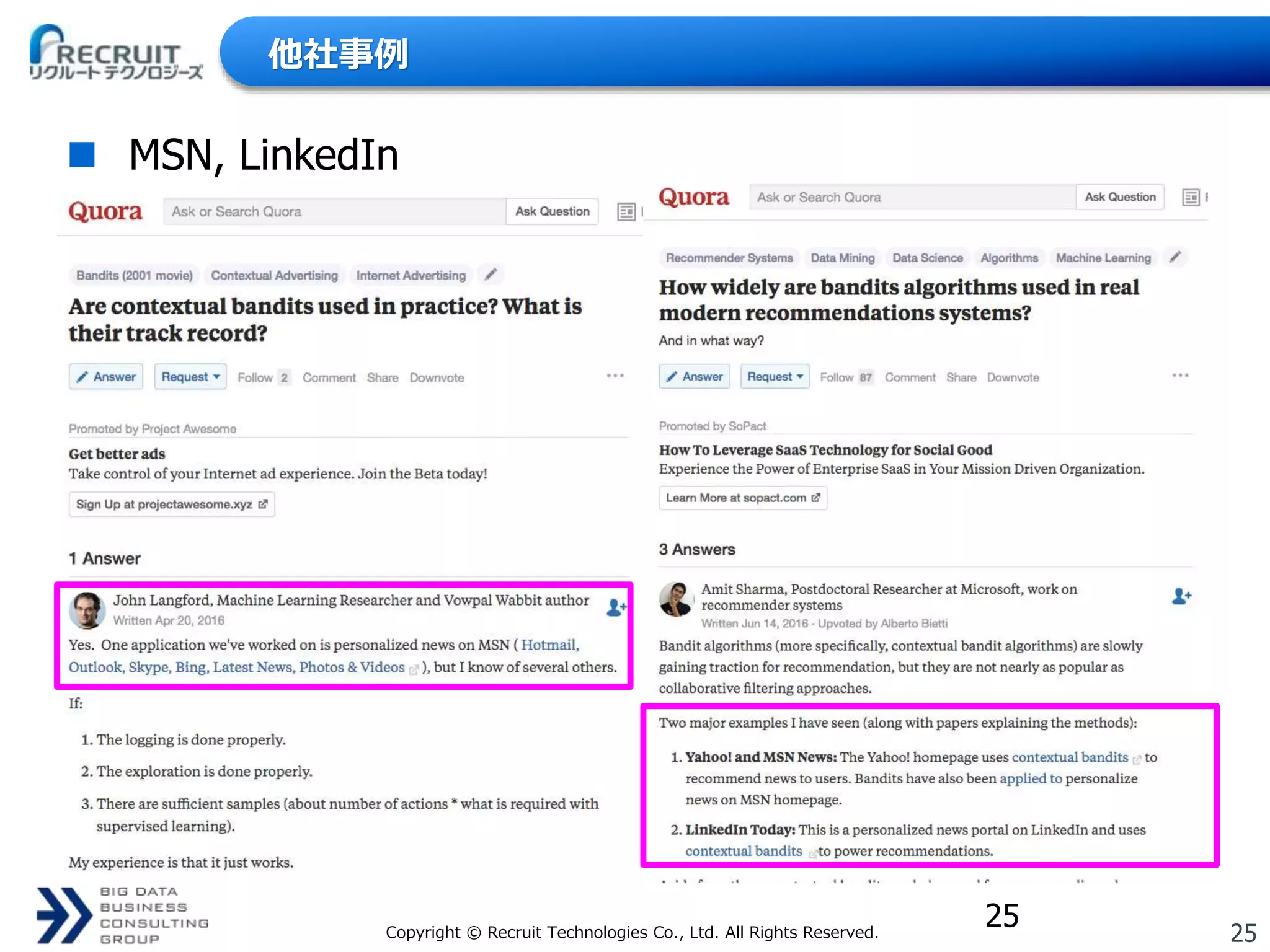
Technologies Co., Ltd. All Rights Reserved. 他社事例 MSN, LinkedIn 25
26.
26Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 自社事例 目的/実施内容 目的 CVR上げたい (副次的に)工数を削減したい 実施内容 クリエイティブ出しわけ 過去2パターンABテストを手動で実施した結果、数%CVR向上した → banditでパターン数を増やし、より良い結果を目指す 内部的に割り振っているクラスタ情報が存在するので、クラスタ単位での出し わけ
27.
27Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. アルゴリズム選択 要件 要件的にニュース等と違い、リアルタイム更新の必要性は薄い 論文等で主張されている評価基準(Regret)だけで選べない • 実際に自環境で達成できるかは全く別(特に難しいロジックは) • 事前にある程度の性能予測をしたい 事前の性能予測がいい感じでも、本番でうまく動くかは不明 • ミニマムで作って本番へ • うまくいったらスケール/ロジックエンハンス • リアルタイム更新でないケースでうまくはまる、実装や本番との連携が簡単な仕組み を作る →Thompson Samplingを採用
28.
28Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. Thompson Sampling pseudo code
29.
29Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 他に考慮すべき点 やる事が決まった上でどうロジックを組み込むか ファイル連携?api? 簡単に実現したい 有事の際すぐにリカバリーできるようにしたい →ユーザ側(フロント)での調整にも対応出来るよう、ファイル連携を選択 案 動き メリット デメリット api 叩かれた時に計算、 プレイ腕を返す フロント実装が楽 フロント側から見て ブラックボックス 叩かれた時にapi側 で持つ確率ファイルか ら抽出、プレイ腕を 返す フロント実装が楽/ API計算はバッチで済む フロント側での調整 /緊急対応しづらい ファイル連携 webサーバ側で持つ 確率ファイルからプレ イ腕を決定 API計算はバッチで済む/ ユーザ側で明日の出し分け 確率がわかる フロント実装が面倒
30.
30Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. チューニング ファイル連携なら多少計算時間がかかっても許される +本来のThompson Samplingの動きと違うので、確率ファイルの生成をする 必要がある 収束保証のない(※)中で、多少時間がかかってもいい動きをするようにしたい ※強化学習系の手法一般に言える(はず)
31.
31Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. シミュレーション banditアルゴリズムのバックテストは一般的に難しい そもそも都合のいいデータがないと不可能 都合のいいデータがある際のテスト方法: https://arxiv.org/pdf/1405.3536.pdf https://arxiv.org/pdf/1003.5956.pdf シミュレーションでいいものを選ぶ 試したパラメータ • beta分布のパラメータキャップ – 過程で分布が過度に尖ってしまい、プレイする腕の期待報酬分布が尖り過ぎるのを防ぐ。 beta(a,b)のときa+b<=nの範囲で按分する – {100, 200, 300, 500, 700, 1000, なし} • Thompson Sampling実施回数 – プレイする腕を選択する際、TSを何回実施した結果を用いるか – {1, 5, 10, 15, 20, 30, 50, 75, 100}
32.
32Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. シミュレーション結果 シミュレーション前提: 真の報酬:0.4%を中心に上下4段階ずつ、計9つの腕を用意 1段階変化ごとに±3%(元の値から)報酬を変化させている 1日2000プレイの結果(表出コンテンツ/cv or not)が手に入る テスト期間は60日間 各実験で1000トライアルずつ実施した時の平均報酬の変化をプロット シミュレーション結果 縦軸:期待報酬 横軸:日 この辺が良 さそう
33.
33Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. banditアルゴリズム:研究トピックのトレンド 制約付き バジェット付き 時間経過で腕/ 報酬が変化(変化/ 消滅/ 誕生) ランクのみ学習 無限腕bandit グラフとの組み合わせ 適用領域のエンハンス ページ全体のUI改善 インタラクティブレコメ オフラインテスト手法 抜粋: KDD, AAAI, NIPS, ICMLの最新accepted papers ※NIPS以外は2017, NIPSは2016,WSDM発見できず
34.
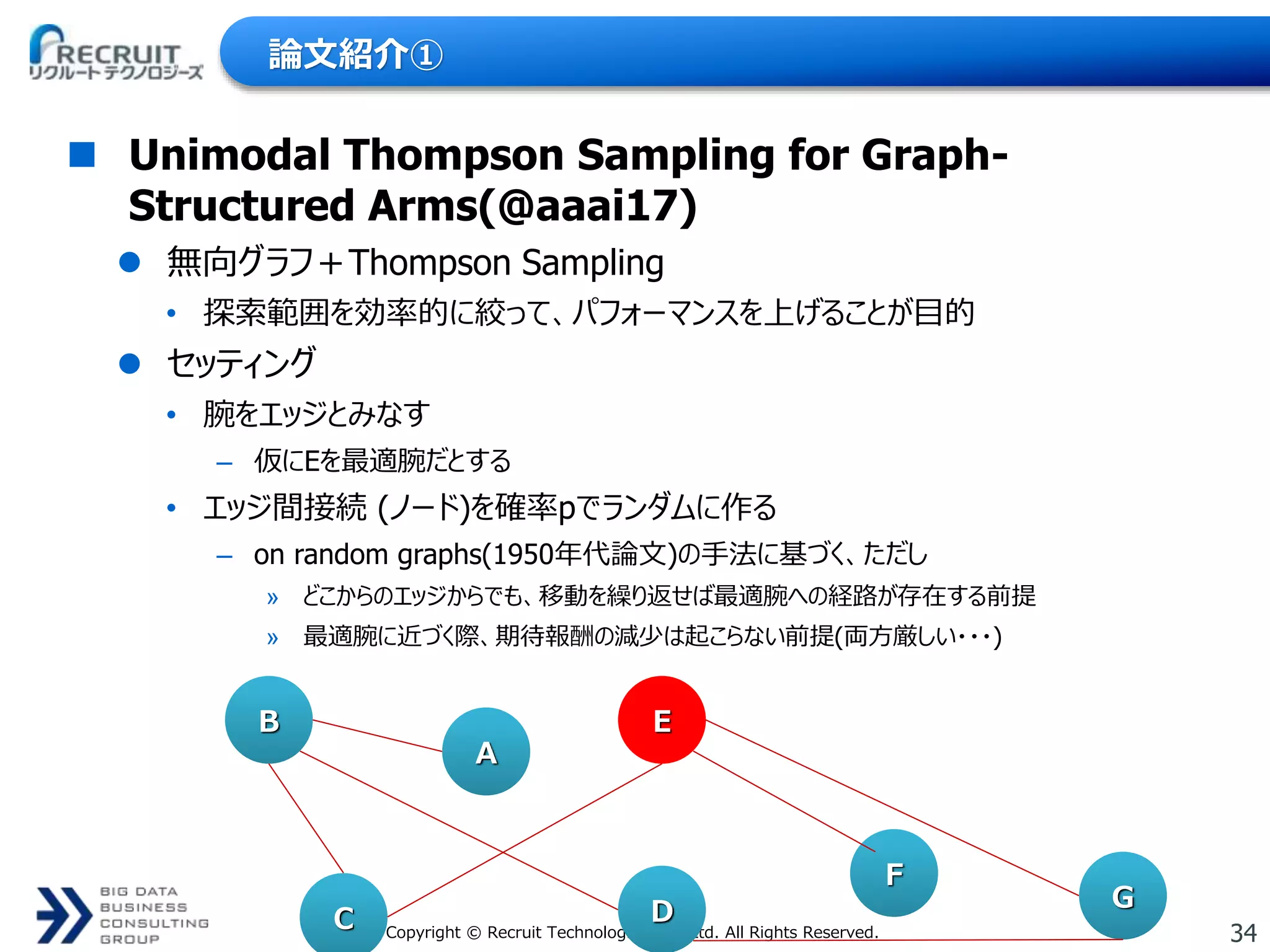
34Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介① Unimodal Thompson Sampling for Graph- Structured Arms(@aaai17) 無向グラフ+Thompson Sampling • 探索範囲を効率的に絞って、パフォーマンスを上げることが目的 セッティング • 腕をエッジとみなす – 仮にEを最適腕だとする • エッジ間接続 (ノード)を確率pでランダムに作る – on random graphs(1950年代論文)の手法に基づく、ただし » どこからのエッジからでも、移動を繰り返せば最適腕への経路が存在する前提 » 最適腕に近づく際、期待報酬の減少は起こらない前提(両方厳しい・・・) B A E G F DC
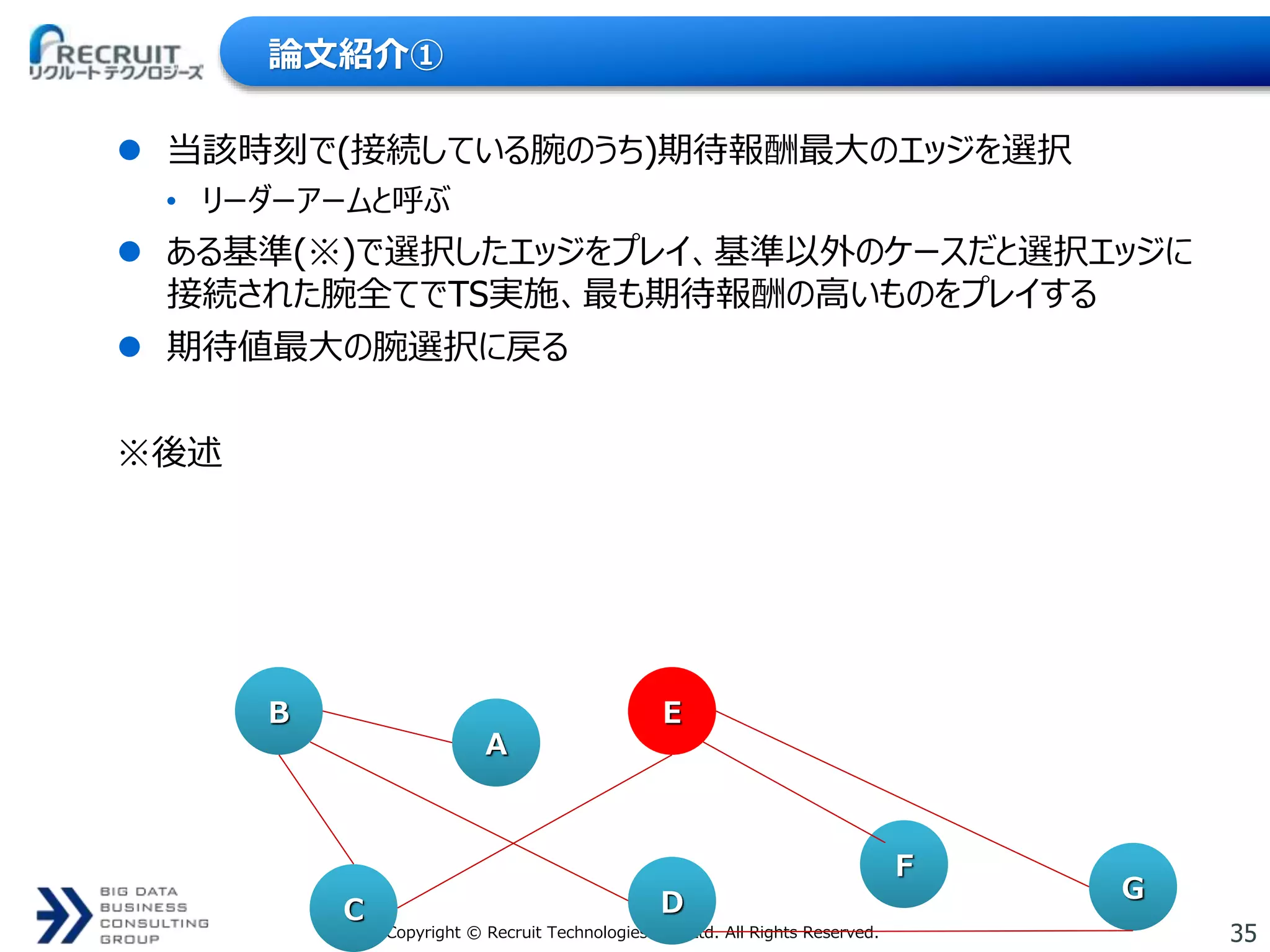
35.
35Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介① 当該時刻で(接続している腕のうち)期待報酬最大のエッジを選択 • リーダーアームと呼ぶ ある基準(※)で選択したエッジをプレイ、基準以外のケースだと選択エッジに 接続された腕全てでTS実施、最も期待報酬の高いものをプレイする 期待値最大の腕選択に戻る ※後述 B A E G F DC
36.
36Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介① B A E G F DC 最適腕へ収束していくプロセス Eをリーダーとして選択→最適腕を選択できている、正解 Cをリーダーとして選択→B,C,EでTS、Eの期待値の方がCより高いので、いず れEがリーダーとして選択される Bをリーダーとして選択→A,B,C,DでTS、いずれCがリーダーとして選択される。 理由は同上 →Optimal Armに向かっての滝登り
37.
37Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. G(グラフ),T(制限時間), π(事前分布)を入れる 全腕で時刻Tまでの期待報酬を計算 通算報酬最大の腕(最適腕)を特定 最適腕としての被選択回数 /( 接続ノード数+1) 最適腕をプレイ 最適腕+隣接腕でθだけサンプリング 報酬が最大になる腕をプレイ 論文紹介① ※5行目はRegret計算を簡単にするために、先行論文での提案手法でも導入されているとのこと(本人談) 先行論文での手法:GLSE(Jia and Mannor, 2011), OSUB(Combes and Proutiere, 2014)
38.
38Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介② Efficient Ordered Combinatorial Semi-Bandits for Whole-page Recommendation(@aaai17) 表出するコンテンツ/場所の最適化を同時に目指す 内容的には2016WSDMでのBestPaper, ”Beyond Ranking: Optimizing Whole-Page Presentation”(リンク↓)と似てる https://pt.slideshare.net/techblogyahoo/wsdm2016beyond- rankingoptimizing-wholepage-presentationyjwsdm BestPaper Efficient~検索結果 全体最適 コンテンツ/ポ ジション最適
39.
39Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介② Best Paperとの比較 どちらもyahooデータセットを使っている論文 どちらも著者にyahoo関係者が入っている Best Paper 紹介 最適化範囲 検索結果全体 コンテンツ表出箇所 アルゴリズム GBDT Thompson Sampling 前提 ランダム出し分け結果が手元にある (論文だと800万PV分) 特になし 特徴量 コンテンツの特徴 ポジション 情報種類(文字、画像、動画等) 情報特徴(サイズ、フォント等) コンテンツの特徴 ポジション
40.
40Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介② やってること contentsの数:n 候補ポジションの数:k 前提 • 同じコンテンツでも、出すポジションによって報酬が変わる • 1つのポジションには1つのコンテンツしか出せない 場所、コンテンツの配置を下記のように表現する m1 m2 ・・ mk c1 1 c2 1 : 1 cn 1 m1という場所にc1コンテンツ が置かれている & mkという場所にc2コンテンツ が置かれている : : コンテンツ ポジション
41.
41Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介② 整数問題→線形計画 上記パターンで実現出来る報酬を最大化するには整数問題を解く 整数問題はコストが高い {0,1}から[0,1]への変換をしても、得られる結果は同じ 整数問題→線形計画への変換 m1 m2 ・・ mk c1 1 c2 1 : 1 cn 1 m1という場所にc1コンテンツ が置かれている & mkという場所にc2コンテンツ が置かれている : : コンテンツ ポジション
42.
42Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. 論文紹介② 最適配置を実現し、CVR最大を目指す Thompson Samplingでの実現 報酬 r = f(contents, position) ~ 何かしらの期待報酬分布 各選択の期待報酬は下記のように表現できる f(cn,mk)で表現される分布からサンプリングを実施、実現値を抽出する あとは線形計画を解いて解を得る m1 m2 ・・ mk c1 f(c1,m1) f(c1,m2) ・・ f(c1,mk) c2 f(c2,m1) f(c2m2) ・・ f(c2,mk) : : : ・・ : cn f(cn,m1) f(cn,m2) ・・ f(cn,mk)
43.
43Copyright © Recruit
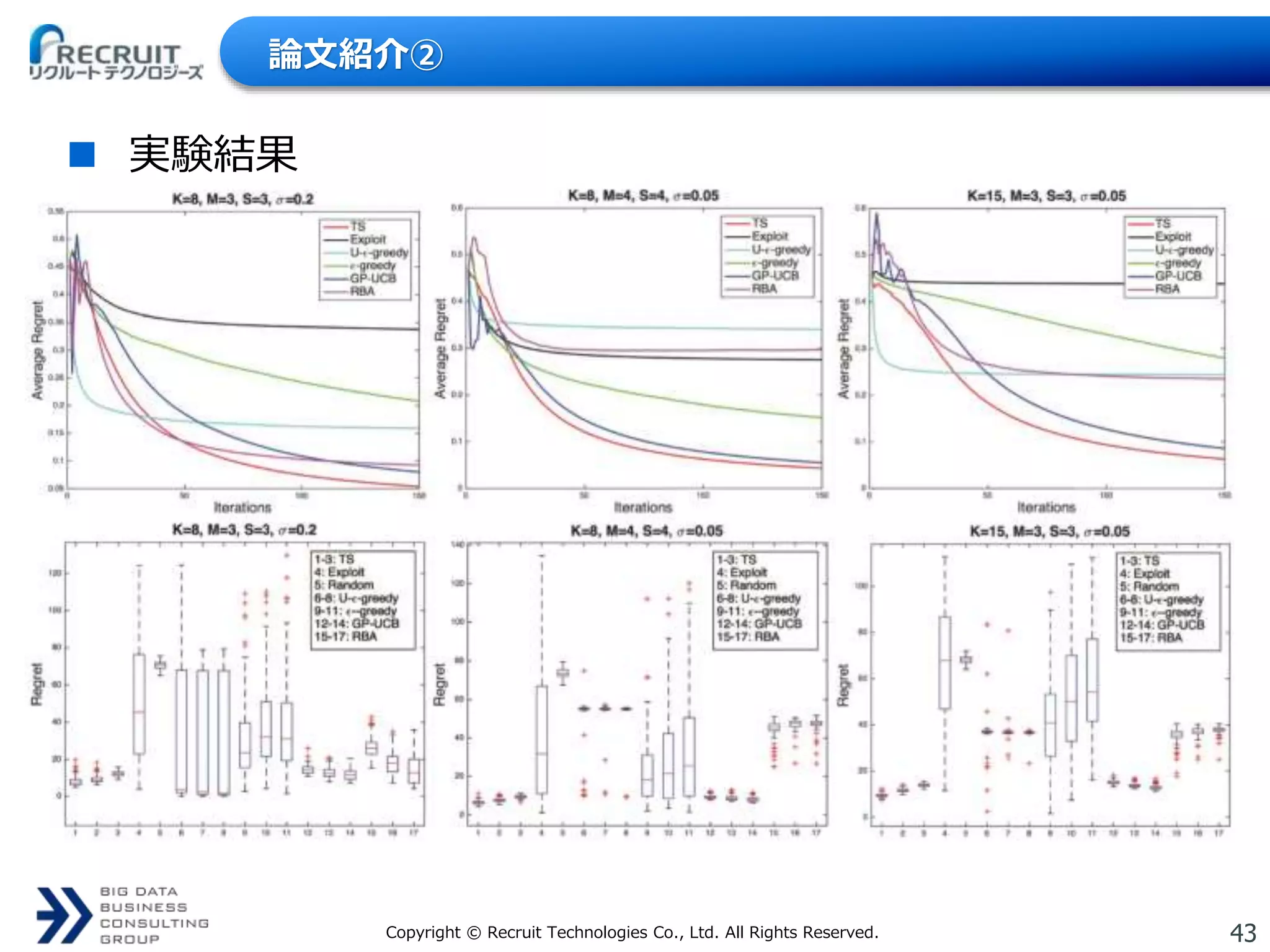
Technologies Co., Ltd. All Rights Reserved. 論文紹介② 実験結果
44.
44Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. まとめ banditアルゴリズムを用いることで、データが存在しない/集めづらい 領域の最適化ができるようになる ケースに応じて最適パラメータが変わってくるので、シミュレーションで 最適パラメータを求めた アルゴリズム自体に収束保証がない/手動で出し分けを実現したい ケースが想定されるので、緊急停止ボタン(ファイル書き換えで可 能)を仕込んだ
45.
45Copyright © Recruit
Technologies Co., Ltd. All Rights Reserved. ポジションあります 機械学習を利用して自由にビジネスを作っていきたい人 是非、一緒に働きましょう リクルートテクノロジーズ 田口 正一(たぐち しょういち) shoichi_tagu@r.recruit.co.jp 連絡先
Download






























![41Copyright © Recruit Technologies Co., Ltd. All Rights Reserved.
論文紹介②
整数問題→線形計画
上記パターンで実現出来る報酬を最大化するには整数問題を解く
整数問題はコストが高い
{0,1}から[0,1]への変換をしても、得られる結果は同じ
整数問題→線形計画への変換
m1 m2 ・・ mk
c1 1
c2 1
: 1
cn 1
m1という場所にc1コンテンツ
が置かれている
&
mkという場所にc2コンテンツ
が置かれている
:
:
コンテンツ
ポジション](https://image.slidesharecdn.com/pydatabandit-170727020549/75/Pydata_-bandit-_-41-2048.jpg)