More Related Content

PDF
Ml professional bandit_chapter2 
PDF

PDF
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京 
PDF
DeNAの機械学習・深層学習活用した�体験提供の挑戦 
PDF

PDF

PDF
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京 
PPTX
Similar to Ml professional bandit_chapter1

PPTX

PPTX
MLP輪読会 バンディット問題の理論とアルゴリズム 第3章 
PPTX
![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Dl輪読会]introduction of reinforcement learning 
PDF

PDF
強化学習勉強会・論文紹介(第30回)Ensemble Contextual Bandits for Personalized Recommendation 
PDF
Asymptotically optimal policies in multiarmed bandit problems 
PDF

PDF
Large-Scale Bandit Problems and KWIK Learning 
PDF

PDF
いろんなバンディットアルゴリズムを理解しよう 
PDF

PPTX
Pydata_リクルートにおけるbanditアルゴリズム_実装前までのプロセス 
PDF

PDF

PPTX

PPTX

PDF

PDF

PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料) Ml professional bandit_chapter1
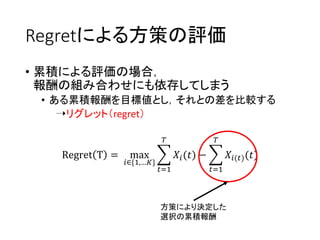
- 1.
- 2.
構成
• 1.1 はじめに
•1.2 バンディット問題の例
• 1.3 確率的バンディットと敵対的バンディット
• 1.4 プレイヤー方策の評価法
• 1.5 バンディット問題の歴史
• 1.6 関連分野
• 1.7 本書の構成
• はなしません
- 3.
構成
• 1.1 はじめに
•1.2 バンディット問題の例
• 1.3 確率的バンディットと敵対的バンディット
• 1.4 プレイヤー方策の評価法
• 1.5 バンディット問題の歴史
• 1.6 関連分野
• 1.7 本書の構成
- 4.
- 5.
- 6.
- 7.
探索と知識利用のトレードオフ
• n を小さくすると・・・
•当たったスロットを多く引けるものの,
真に当たりやすいスロットであるかの見極めが難しい
• nを大きくすると・・・
• 当たりやすいスロットの見極めができるかもしれないが,
当たりやすいスロットを多くは引けない
• 良いアームを探索する必要がある一方で
探索で得たアームを引く知識利用を行う必要もある
• 探索と知識利用はトレードオフとなる
- 8.
- 9.
構成
• 1.1 はじめに
•1.2 バンディット問題の例
• 1.3 確率的バンディットと敵対的バンディット
• 1.4 プレイヤー方策の評価法
• 1.5 バンディット問題の歴史
• 1.6 関連分野
• 1.7 本書の構成
- 10.
- 11.
構成
• 1.1 はじめに
•1.2 バンディット問題の例
• 1.3 確率的バンディットと敵対的バンディット
• 1.4 プレイヤー方策の評価法
• 1.5 バンディット問題の歴史
• 1.6 関連分野
• 1.7 本書の構成
- 12.
- 13.
構成
• 1.1 はじめに
•1.2 バンディット問題の例
• 1.3 確率的バンディットと敵対的バンディット
• 1.4 プレイヤー方策の評価法
• 1.5 バンディット問題の歴史
• 1.6 関連分野
• 1.7 本書の構成
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
構成
• 1.1 はじめに
•1.2 バンディット問題の例
• 1.3 確率的バンディットと敵対的バンディット
• 1.4 プレイヤー方策の評価法
• 1.5 バンディット問題の歴史
• 1.6 関連分野
• 1.7 本書の構成
• はなしません
- 25.
- 26.
- 27.
バンディット問題の歴史
- UCB方策 -
•ライらは期待報酬の信頼上限(upper confidence bound)を
アーム選択指標とする方策を提案(1985年)
• 指標が複雑で計算が困難
• ブルネタスらが計算が容易であるような指標に
改良した方策を提案(1996年)
➝やはり指標は複雑
- 28.
バンディット問題の歴史
- UCB方策 -
•ライらは期待報酬の信頼上限(upper confidence bound)を
アーム選択指標とする方策を提案(1985年)
• 指標が複雑で計算が困難
• ブルネタスらが計算が容易であるような指標に
改良した方策を提案(1996年)
➝やはり指標は複雑
アウアーらがUCB方策(3章)を提案
➝ 漸近的な性能は劣るものの,指標が直感的
様々な分野に応用され機械学習分野においても盛んに
- 29.
バンディット問題の歴史
- 様々な応用 -
•コックシスらはUCTアルゴリズム(Upper Confidence
bound applied to Tree algorithm)(第10章)の提案
• モンテカルロ木探索にUCB方策を導入
• 葉節点の選択にUCB方策を利用する
• Lin UCB方策(LinUCB policy)(第7章)の提案
• UCB方策を線形モデル上のバンディット問題に拡張
• 推薦システムへの応用
• コールドスタート問題を解消する手法として有効
- 30.
バンディット問題の歴史
- 敵対的バンディット -
•1995年にアウアーらがExp3方策(Exponential-weight policy
for Exploration and Exploitation policy)(第5章)を提案
• Hedgeアルゴリズム(第5章)をバンディット問題に適応
• 過去の損失に応じて選択確率を決定する
• 性能改善の余地があった
• 2009年にオーディベールらによりINF方策(Implicitly
Normalized Forcaster policy)(第5章)の提案
• Exp3方策で改善の余地があった部分を解消