Download to read offline





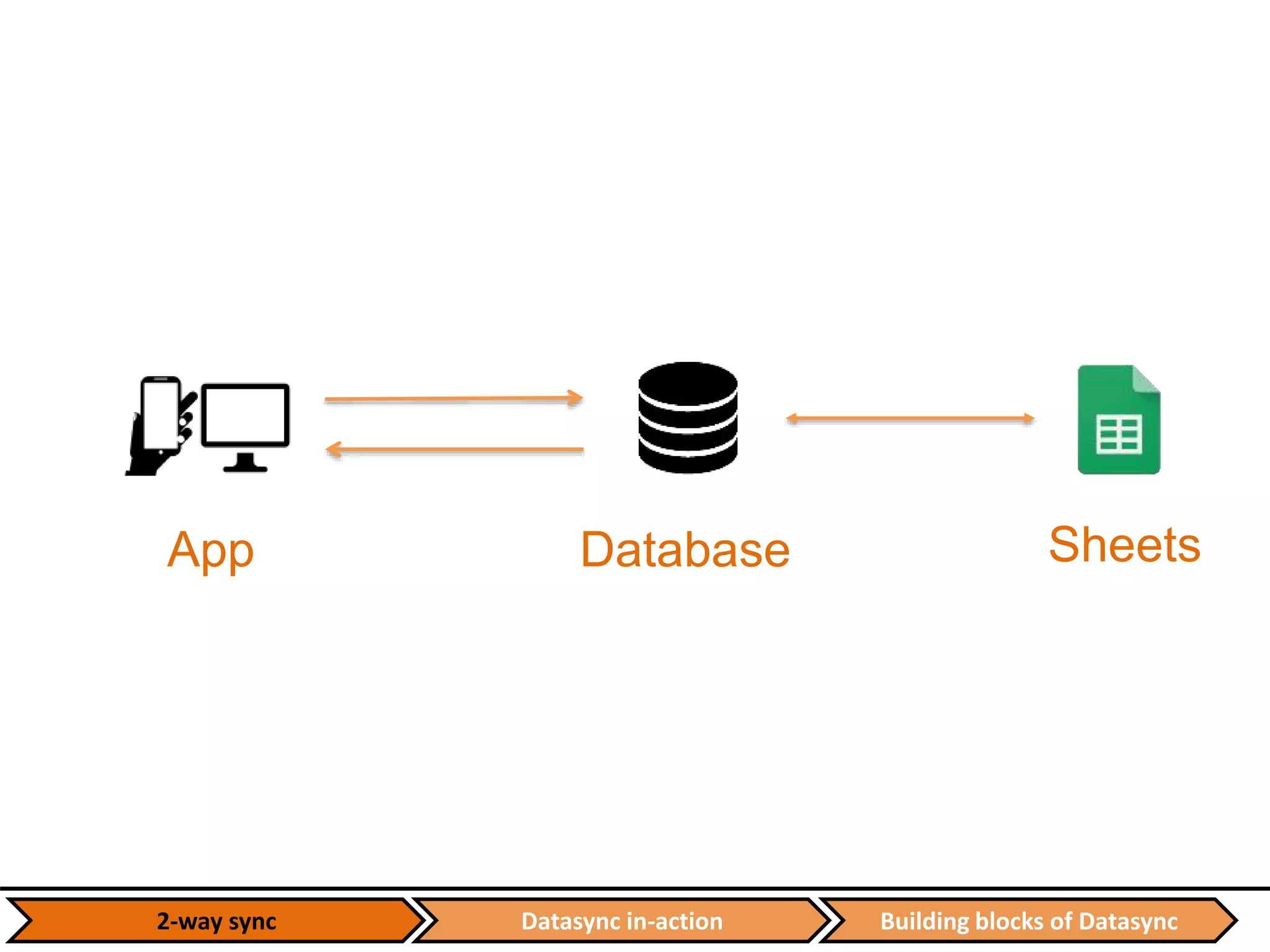
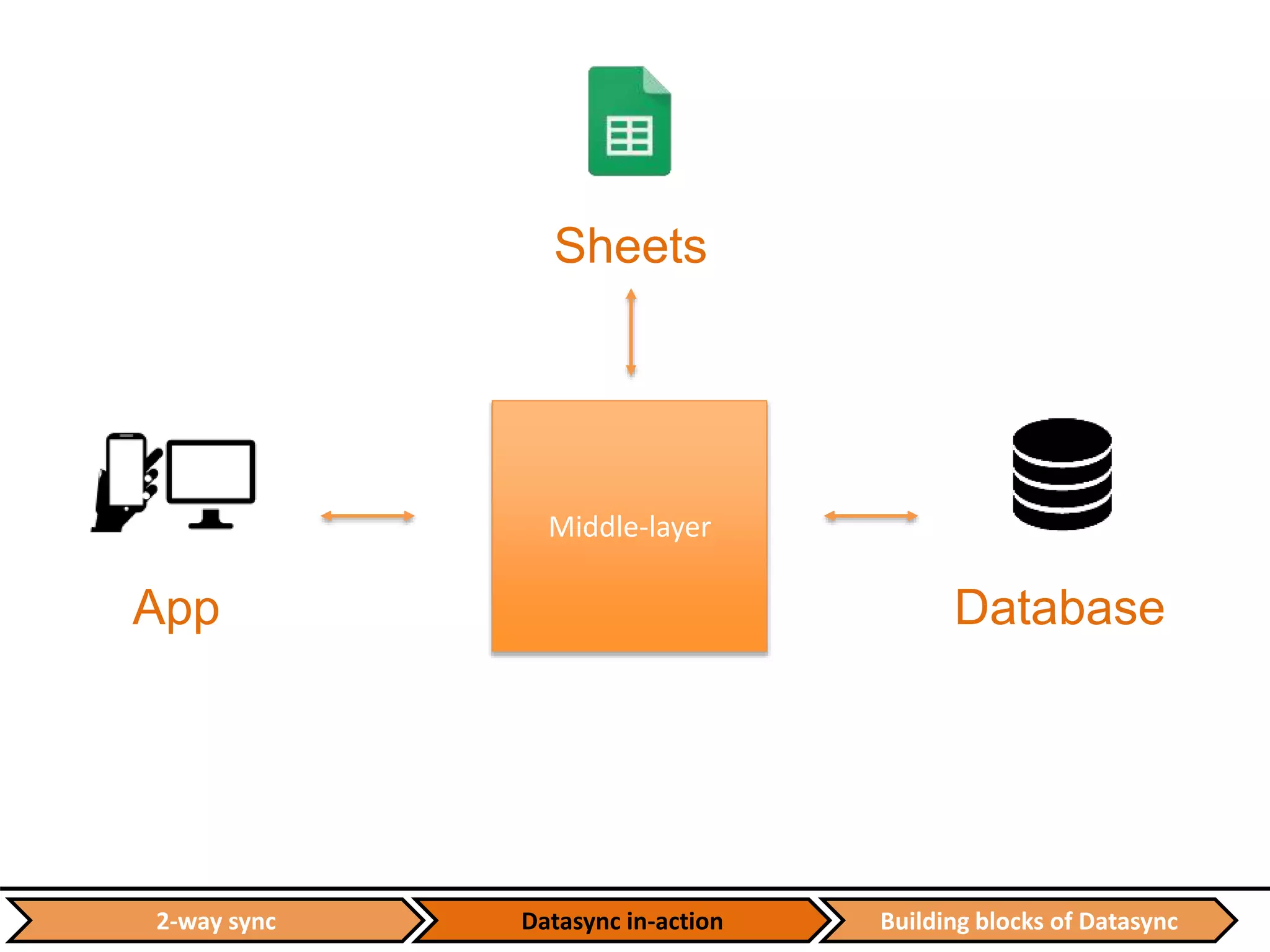

![Datasync in-action Building blocks of Datasync2-way sync
Create a sheet
def create_worksheet(event_id, service):
#get event details, participant group types and event attributes from the database
attributes_group = ["attribute_%s" % x.attribute for x in event_attribute_group]
column_headers = ["ID", "Login Passcode", "Status", "Delete Reason", "Email", "Full Name", "Company”…]
column_headers.extend(attributes_group)
cell_list = [{"userEnteredValue": {"stringValue": header}} for header in column_headers]
grid_data = {"startRow": 0,
"startColumn": 0,
"rowData": [{"values": cell_list}]}
spreadsheet_properties = {"title": event_fullname}
sheet_list = []
for group in event_participant_group:
group_name = group.group_name
sheet_property = {"title": group_name,
"sheetId": group.id_participant_group}
sheet = {"properties": sheet_property,
"data": grid_data}
sheet_list.append(sheet)
spreadsheet = {"properties": spreadsheet_properties,
"sheets": sheet_list}
result = service.spreadsheets().create(body=spreadsheet).execute()
gdocs_key = result['spreadsheetId']
return gdocs_key](https://image.slidesharecdn.com/pycondatasync-160706142703/75/PyCon-SG-x-Jublia-Building-a-simple-to-use-Database-Management-tool-13-2048.jpg)

![Datasync in-action Building blocks of Datasync2-way sync
Wrappers for read/write to sheets
def get_sheets_properties(service, spreadsheet_id):
response = service.spreadsheets().get(
spreadsheetId=spreadsheet_id).execute()
return response
def batch_get_cells(service, spreadsheet_id, cell_ranges, dimension=None):
response = service.spreadsheets().values().batchGet(
spreadsheetId=spreadsheet_id, ranges=cell_ranges, majorDimension=dimension).execute()
values = response.get('valueRanges')
return values
def batch_update_cells(service, spreadsheet_id, cell_range, values, dimension=None, option="USER_ENTERED"):
request = {
"valueInputOption": option,
"data" : [{
"range": cell_range,
"majorDimension": dimension,
"values": values,
}]
}
try:
service.spreadsheets().values().batchUpdate(
spreadsheetId=spreadsheet_id, body=request).execute()
except:
print 'ERROR: Failed to update cells!'](https://image.slidesharecdn.com/pycondatasync-160706142703/75/PyCon-SG-x-Jublia-Building-a-simple-to-use-Database-Management-tool-15-2048.jpg)
![Datasync in-action Building blocks of Datasync2-way sync
Sync endpoint and main class
api.add_resource(DataSync, '/sync/<int:event_id>/<int:start_row>/<int:end_row>/<int:id_participant_group>')
class DataSync(restful.Resource):
def get(self, event_id, start_row, end_row, id_participant_group):
nosql_table = Table('process_status', connection=dynamoconn)
while True:
try:
file_statistic = datasync.sync_spreadsheet(event_id, start_row, end_row, id_participant_group)
except (CannotSendRequest, ResponseNotReady) as e:
if not nosql_table.has_item(EVENT_ID=str(event_id)):
start_row = 0
else:
item = nosql_table.get_item(EVENT_ID=str(event_id))
datasync_json = json.loads(item["DATASYNC_JSON"])
print datasync_json
start_row = int(datasync_json["start_row"])
except Exception, e:
report_dictionary = {'status': 'error',
'data': 'data:{"error", "reason": "sync spreadsheet"}nn'}
create_or_update_ds(event_id, nosql_table, report_dictionary)
return
else:
break](https://image.slidesharecdn.com/pycondatasync-160706142703/75/PyCon-SG-x-Jublia-Building-a-simple-to-use-Database-Management-tool-16-2048.jpg)
![Datasync in-action Building blocks of Datasync2-way sync
Sync main function
def sync_speednetworking(event_id, percentage, start_row, end_row, participant_group_id):
extra_attribute = db.session.query(Attribute_Group).filter(Attribute_Group.id_event == event_id).all()
extra_headers = ["attribute_%s" % (x.attribute) for x in extra_attribute if x.attribute != "Position"]
header = ["ID", "Login Passcode", "Status", "Delete Reason", "Email", "Full Name", "Company", "Position",
"Company URL", "Company Description", "Sponsor (1 or 0)", "Contact No", "Intend to Meet", "Meeting
Location"]
header.extend(extra_headers)
# Initiate service for Google Sheets API v4
service = init_service()
# Retrieve relevant sheet properties – spreadsheet_id, sheet_properties, sheet_title, row_count…
# check whether user input params are correct…
block_size = 10
last_chunk_size = (max_row) % block_size
last_chunk_count = int(ceil(max_row / float(block_size)))
start_range = start_row
if (end_row - start_row) > (block_size - 1):
end_range = start_row + (block_size - 1)
else:
end_range = end_row](https://image.slidesharecdn.com/pycondatasync-160706142703/75/PyCon-SG-x-Jublia-Building-a-simple-to-use-Database-Management-tool-17-2048.jpg)
![Datasync in-action Building blocks of Datasync2-way sync
Sync main function - 2
for loop_count in xrange(1, last_chunk_count+1):
end_col = build_a1_end_range(header_len, end_range)
cell_range = 'A%s:%s' % (start_range, end_col)
cell_range = sheet_title + '!' + cell_range
response = batch_get_cells(service, spreadsheet_id, cell_range)
if 'values' in response[0].keys():
values = response[0]['values']
attendee_row = start_range
data_struct = {}
data_struct['event_id'] = event_id
data_struct['cell_range'] = cell_range
data_struct['spreadsheet_id'] = spreadsheet_id
data_struct['participant_group_id'] = participant_group_id
data_struct['values'] = []
for value in values:
row = []
row.append(attendee_row)
while len(value) != len(header):
value.append("")
row.extend(value)
data_struct['values'].append(row)
attendee_row += 1
data_struct = ujson.dumps(data_struct)
process_data(data_struct, 1, service)](https://image.slidesharecdn.com/pycondatasync-160706142703/75/PyCon-SG-x-Jublia-Building-a-simple-to-use-Database-Management-tool-18-2048.jpg)

![Datasync in-action Building blocks of Datasync2-way sync
Middle layer
def process_data(data_struct, sync_type, service=None):
data_struct = json.loads(data_struct)
# Misc info – get event_id, cell_range, spreadsheet_id, participant_group_id from data_struct…
update_row_list = []
run_batch_update = False # Run batch update only when there is new attendee
if sync_type == 1:
for data_row in data_struct['values']:
if not data_row[1]:
run_batch_update = True
update_row = add_new_attendee(event_id, data_row, participant_group_id)
update_row_list.append(update_row)
elif data_row[3]:
if data_row[3].lower() == 'delete':
attendee_id = data_row[1]
delete_profile_sn(attendee_id)
update_row_list.append(data_row[1:])
else:
update_attendee(data_row, participant_group_id)
update_row_list.append(data_row[1:])
else:
update_attendee(data_row, participant_group_id)
update_row_list.append(data_row[1:])
if run_batch_update:
batch_update_cells(service, spreadsheet_id, cell_range, update_row_list)
return 1](https://image.slidesharecdn.com/pycondatasync-160706142703/75/PyCon-SG-x-Jublia-Building-a-simple-to-use-Database-Management-tool-20-2048.jpg)
![Datasync in-action Building blocks of Datasync2-way sync
SSE with DynamoDB
def create_or_update_ds(event_id, table, report_dictionary):
event_id = str(event_id)
dumped_json = ujson.dumps(report_dictionary)
if table.has_item(EVENT_ID=event_id):
item = table.get_item(EVENT_ID=event_id)
item["DATASYNC_JSON"] = dumped_json
item.save(overwrite=True)
else:
table.put_item({"EVENT_ID":str(event_id), "DATASYNC_JSON": dumped_json,
"EMAILSENDER_JSON":"", "CRM_JSON":""})
Dynamo
DATASYNC
BACKEND
SENSE](https://image.slidesharecdn.com/pycondatasync-160706142703/75/PyCon-SG-x-Jublia-Building-a-simple-to-use-Database-Management-tool-21-2048.jpg)




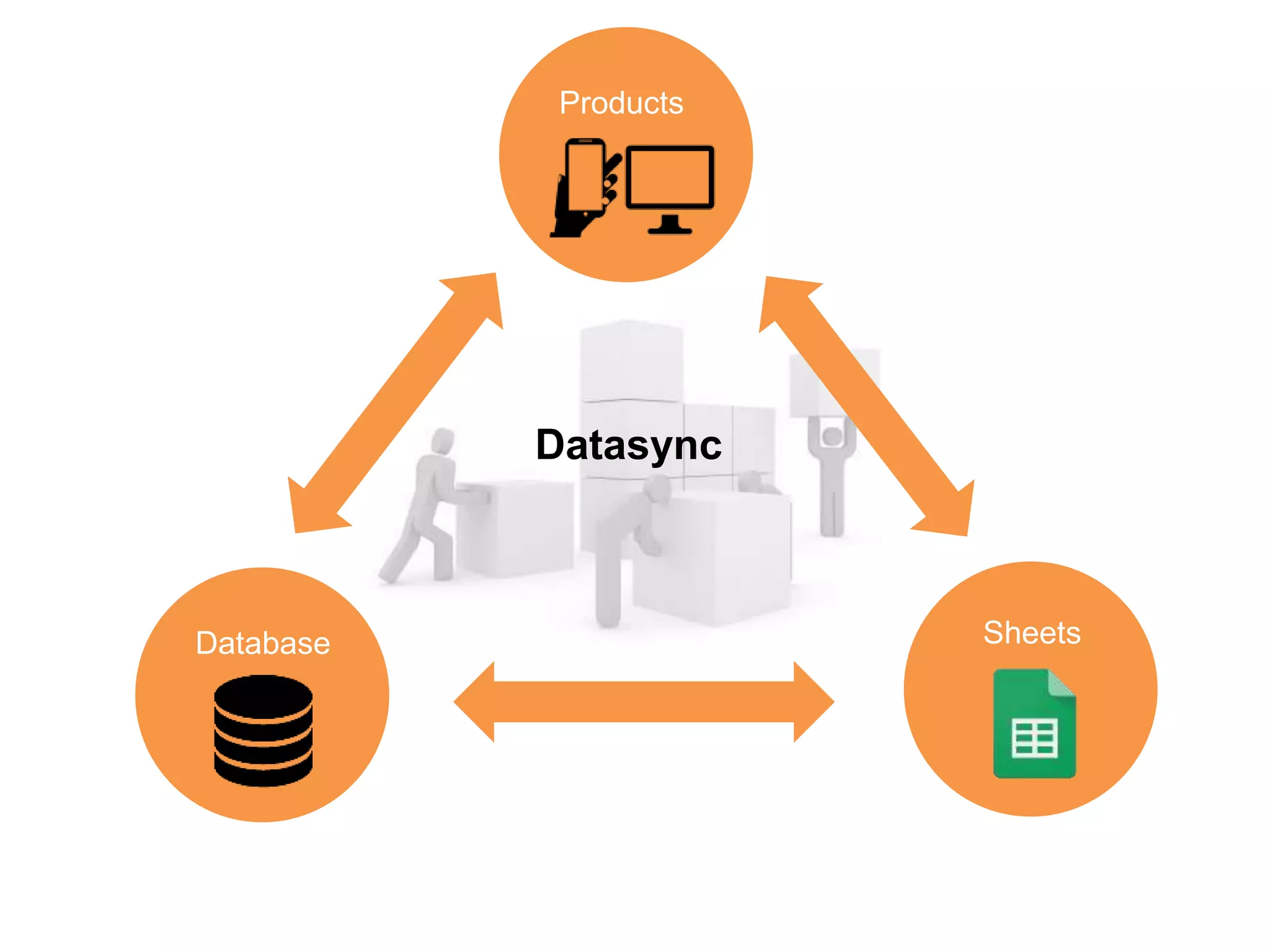
The document discusses the implementation of a data synchronization process using Google Sheets API and DynamoDB for managing event data. It includes code snippets for creating sheets, sharing permissions, and syncing participant data, emphasizing efficient data collection and management practices in enterprises. The conclusion highlights the common pitfalls in data management, advocating for better structure and foresight in data collection strategies.


































































