







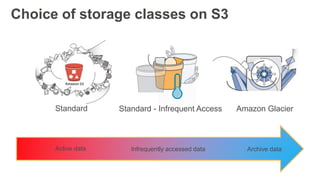


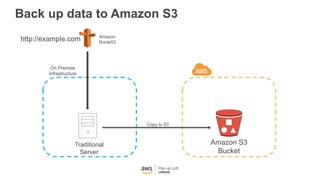
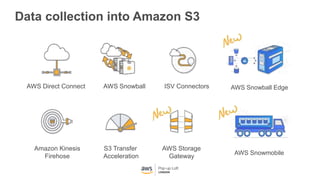



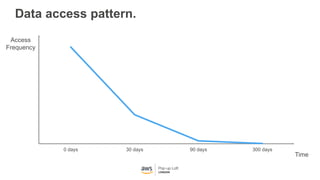
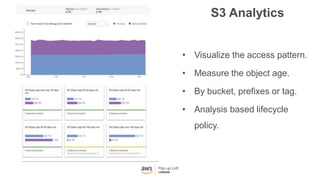


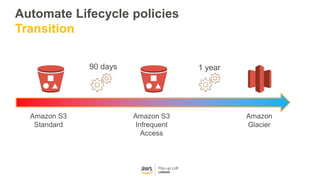
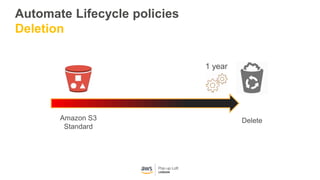
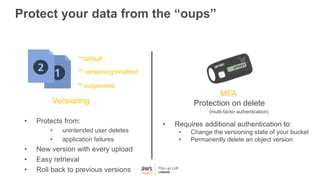

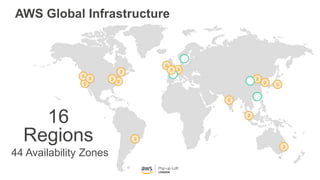
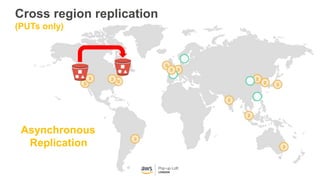
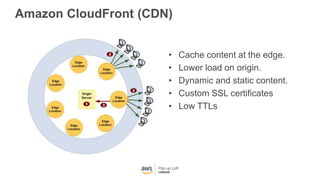
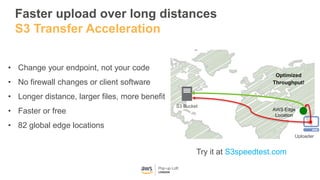
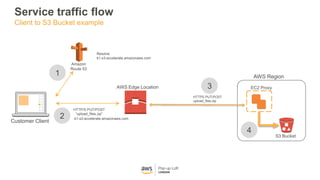

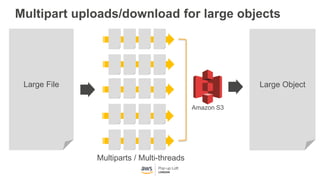




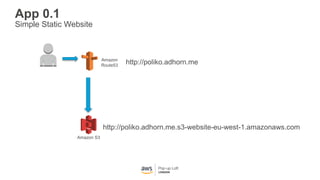
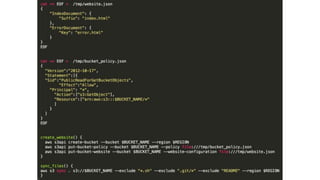
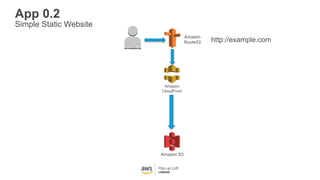


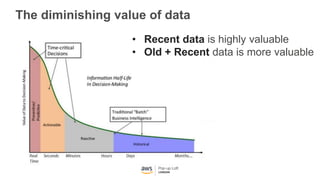
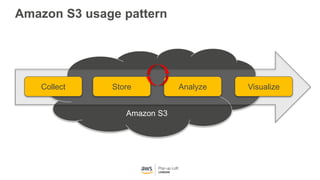

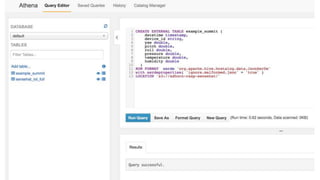
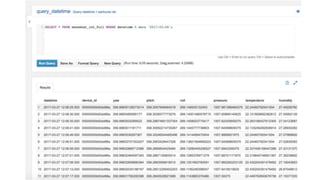
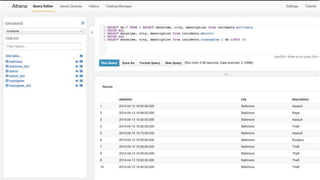


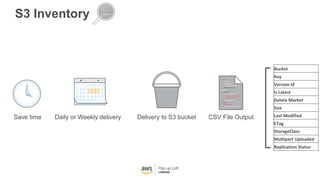
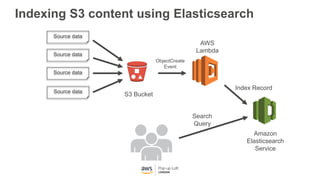

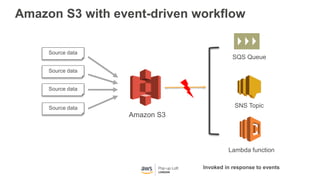
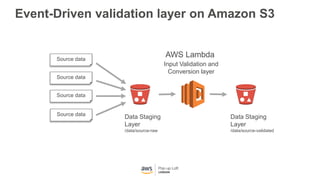
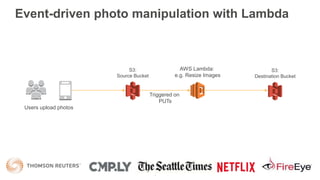
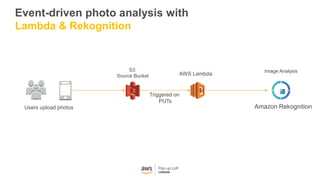

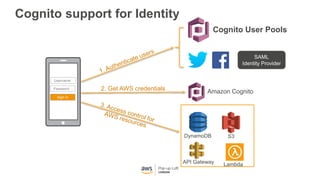
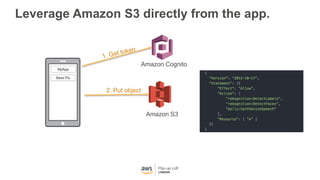
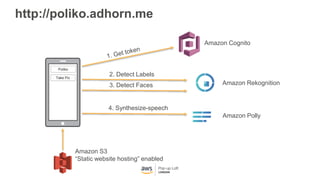


This document provides an overview of Amazon S3 and object storage solutions on AWS. It discusses how S3 is used by companies like Netflix, SoundCloud and Airbnb to store large amounts of data. It also summarizes the different storage classes (Standard, Infrequent Access, Glacier), options for data transfer like Snowball, and use cases like website hosting, backup/disaster recovery, and analytics. Architectural patterns with events and Lambda are presented for building scalable, serverless applications with S3.



































































