




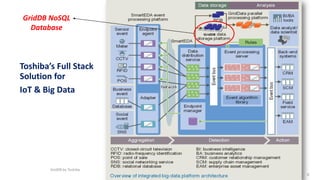

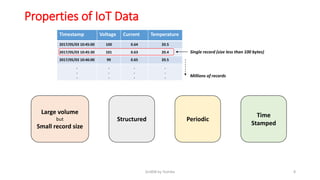
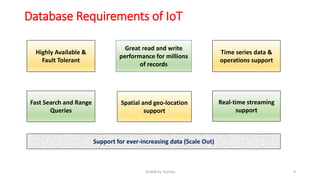
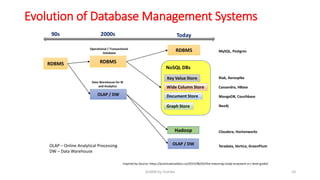

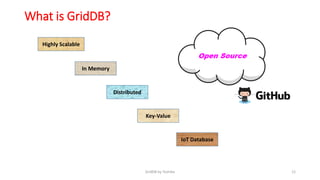
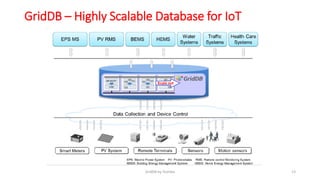
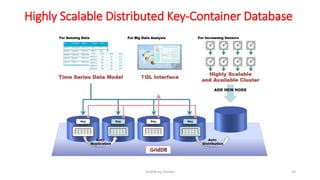
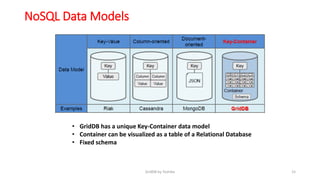
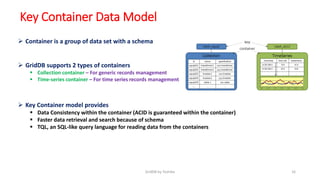
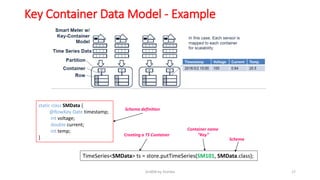
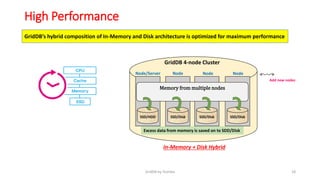
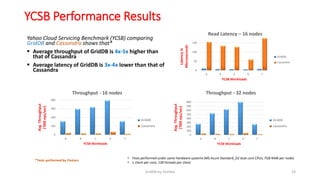
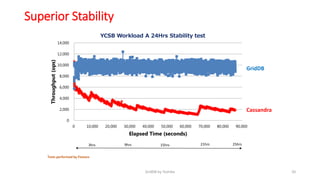
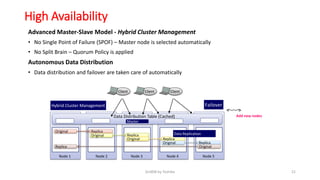




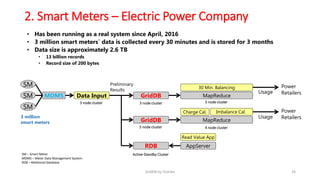



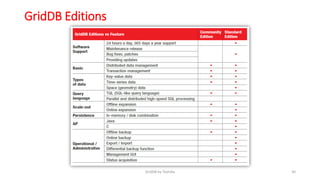









GridDB is a highly scalable in-memory NoSQL database designed for IoT applications. It uses a key-container data model and provides high performance for periodic time-series data through its in-memory and disk storage architecture. GridDB demonstrated superior performance and stability compared to Cassandra in Yahoo Cloud Services Benchmark tests. It supports features important for IoT like time-series data types and operations.













































![Introducing TiDB [Delivered: 09/27/18 at NYC SQL Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/nycmysqlintroducingtidb-180928024621-thumbnail.jpg?width=640&height=640&fit=bounds)








































