Download as PDF, PPTX






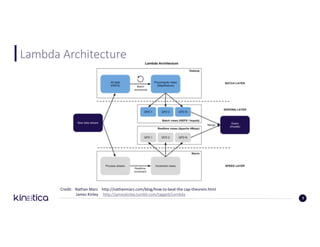
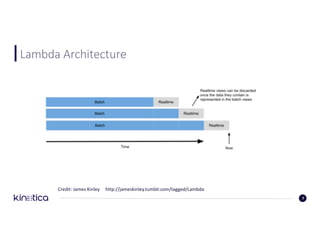
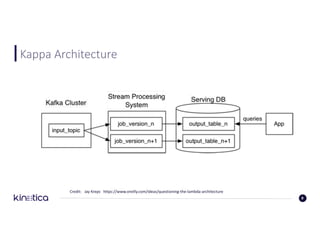




![Full-Text Search
“Rain Tire” ~5Kinetica includes powerful text search functionality,
including :
• Exact Phrases
• Boolean – AND / OR
• Wildcards
• Grouping
• Fuzzy Search (Damerau-Levenshtein optimal string alignment algorithm)
• N-Gram Term Proximity Search
• Term Boosting Relevance Prioritization
"Union Tranquility"~10
[100 TO 200]
22](https://image.slidesharecdn.com/howtoachievereal-timeanalyticsonadatalakeusinggpus-170620170154/85/How-To-Achieve-Real-Time-Analytics-On-A-Data-Lake-Using-GPUs-24-320.jpg)






The document discusses methods for achieving real-time analytics on data lakes using GPUs, addressing challenges such as large data volumes and minimal latency. It presents various architectural approaches, including lambda and kappa architectures, and highlights the advantages of GPU-accelerated databases like Kinetica for processing and analyzing big data efficiently. Additionally, it includes use cases in logistics and financial sectors, showcasing the performance benefits of rapid data ingestion and analytics capabilities.



































































