Downloaded 76 times


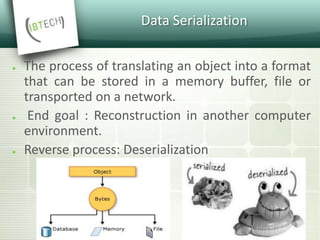










![Message Definition
Messages defined in .proto files
Syntax:
Message [MessageName] { ... }
Can be nested
Will be converted to e.g. a Java class](https://image.slidesharecdn.com/protocolbuffers-161006131143/85/Protocol-Buffers-14-320.jpg)
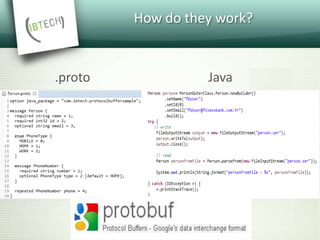
![Message Contents
Each message may have
Messages
Enums:
enum <name> {
valuename = value;
}
Fields
Each field is defined as
<rule> <type> <name> = <id> {[<options>]};
Rules : required, optional, repeated](https://image.slidesharecdn.com/protocolbuffers-161006131143/85/Protocol-Buffers-15-320.jpg)
![Generated Code
MESSAGES
• Immutable (Person.java)
BUILDERS
• (Person.Builder.java)
ENUMS & NESTED CLASSES
• Person.PhoneType.MOBILE
• Person. PhoneNumber
PARSING & SERIALIZATION
• writeTo(final OutputStream output)
• parseFrom(byte[] data), parseFrom(java.io.InputStream input)](https://image.slidesharecdn.com/protocolbuffers-161006131143/85/Protocol-Buffers-16-320.jpg)



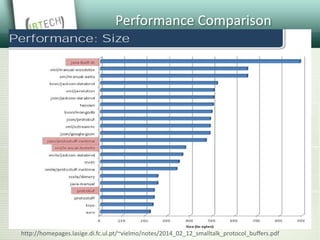
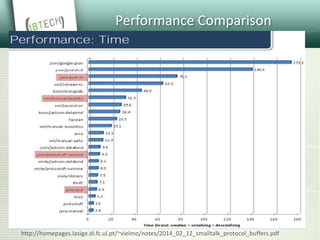



Protocol Buffers are a language-neutral, platform-neutral way of serializing structured data developed by Google to deal with problems of scale. Data formats are defined using .proto files which are then compiled to generate data access classes. This allows structured data to be serialized and transmitted efficiently across various languages and platforms while maintaining backward/forward compatibility. Protocol Buffers offer advantages over other solutions like XML in being more efficient, compact and faster. They have found many use cases at Google and other companies for messaging, data storage and transmission.























































































