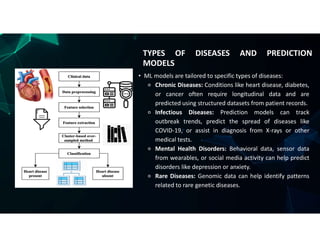
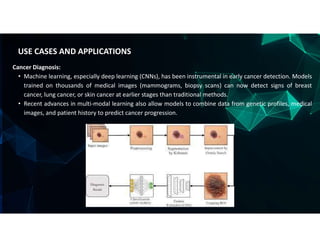
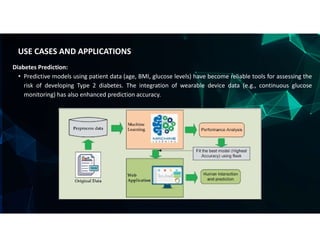
The document discusses the use of machine learning (ML) for disease prediction in healthcare, outlining how various ML models analyze historical data to identify patterns and forecast health outcomes. It covers types of diseases (chronic, infectious, mental health, and rare diseases), different algorithms like logistic regression, random forests, and convolutional neural networks (CNNs), and challenges in prediction such as data quality and interpretability. Additionally, it highlights applications for predicting diseases like heart disease, cancer, diabetes, and COVID-19, emphasizing the importance of data privacy and model evaluation metrics.



















































![PPT-HEART-DISEASE[1].pptx presentationss](https://cdn.slidesharecdn.com/ss_thumbnails/ppt-heart-disease1-250901140846-bb7a7155-thumbnail.jpg?width=640&height=640&fit=bounds)























![Hypothalamus short ppt by Dr. Neha [PT].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hypothalamusbydr-260124145759-b9f94a93-thumbnail.jpg?width=640&height=640&fit=bounds)












