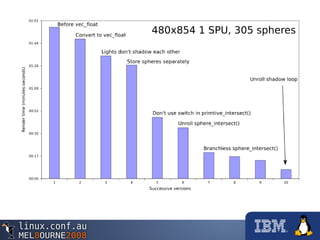
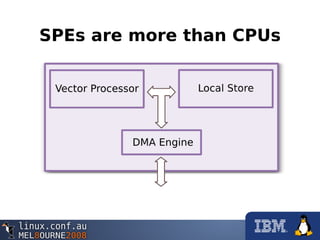
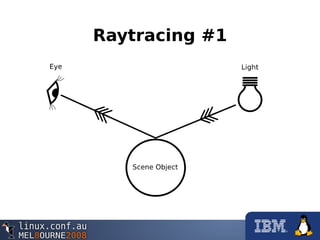
This document provides an overview of programming the Cell processor by describing how to optimize a raytracing algorithm for parallel execution across the Synergistic Processing Elements (SPEs) of the Cell. It discusses strategies like partitioning the image into rows for each SPE to process, using vectors and SIMD instructions to perform the 3D math calculations efficiently, avoiding branches by restructuring code, and leveraging direct memory access (DMA) to transfer data effectively between the SPEs and main processor. The document also notes more advanced techniques like adaptive work partitioning, object caching, and dynamic code loading that could further improve a complex raytracer's performance on the Cell architecture.

























![PPE Structure
load_scene()
for 0 to num_spus:
threads[i] = spawn_spu_thread(i)
for 0 to num_spus:
wait_for(threads[i])
save_image()](https://image.slidesharecdn.com/ellerman-lca-08-171226163156/85/Programming-the-Cell-Processor-A-simple-raytracer-from-pseudo-code-to-spu-code-28-320.jpg)