
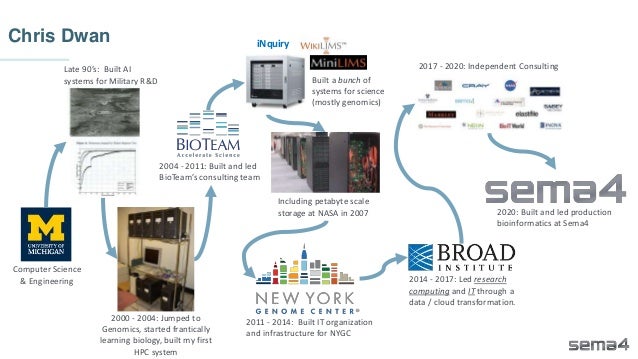


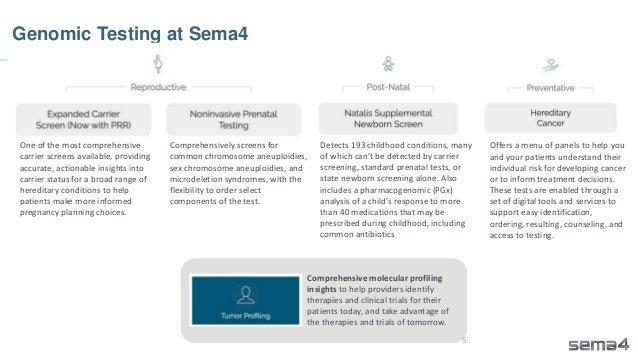

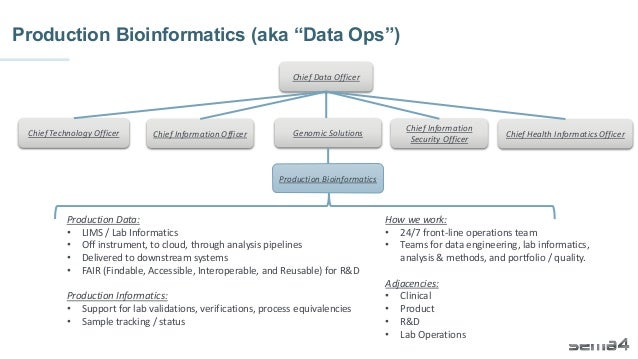
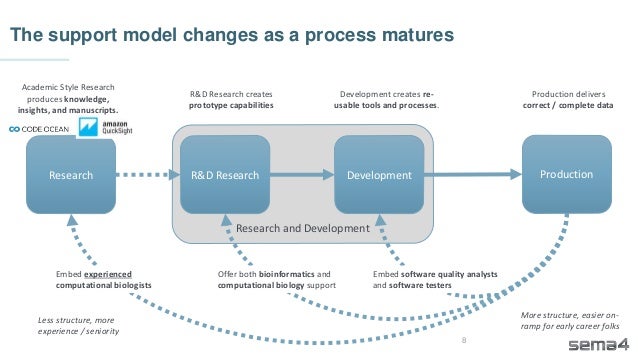

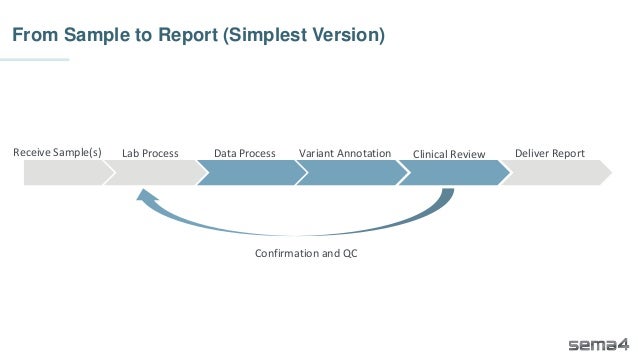
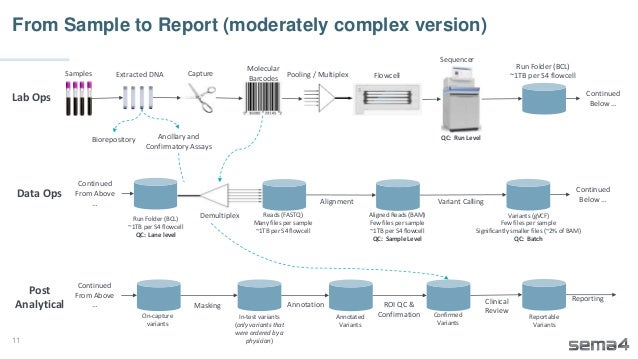
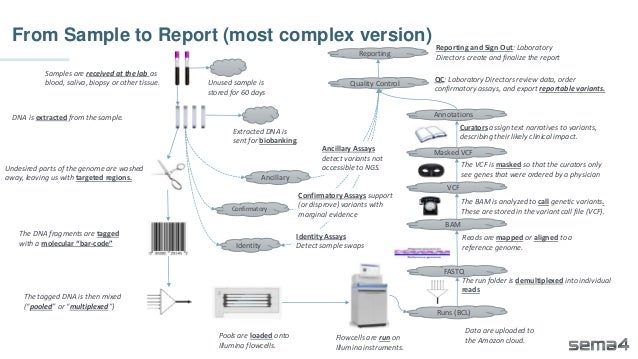
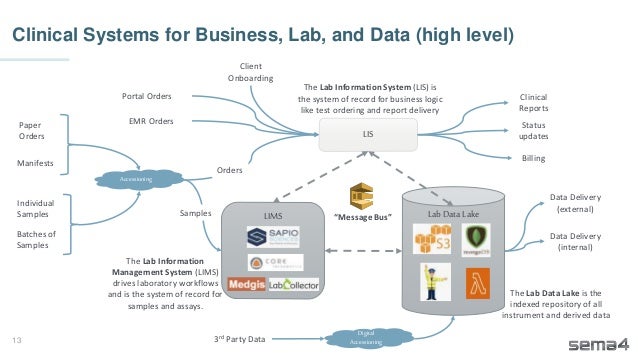
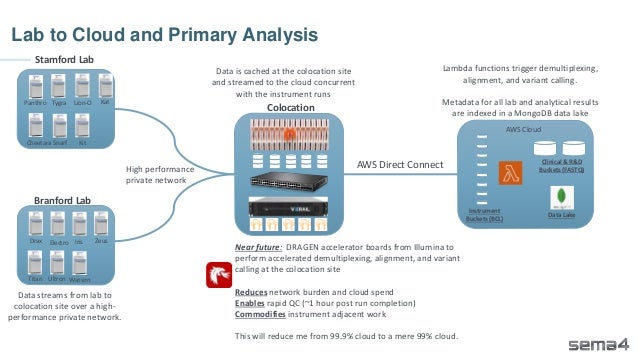
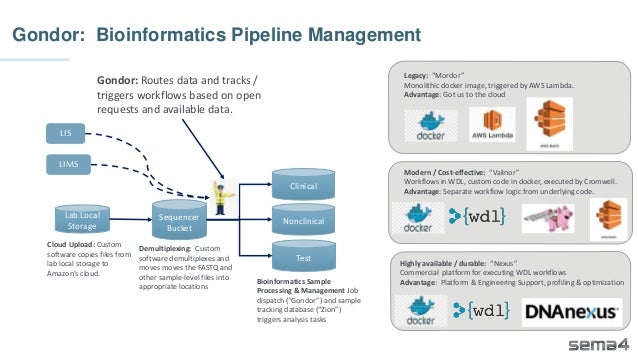
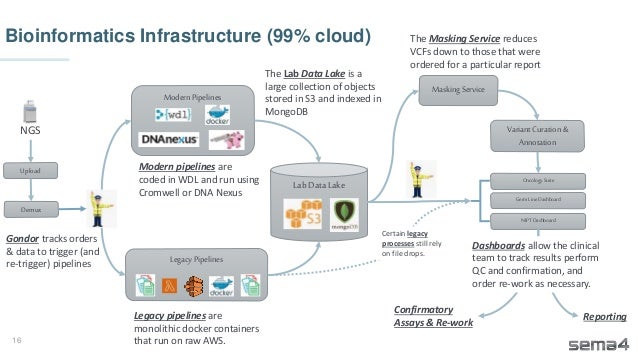


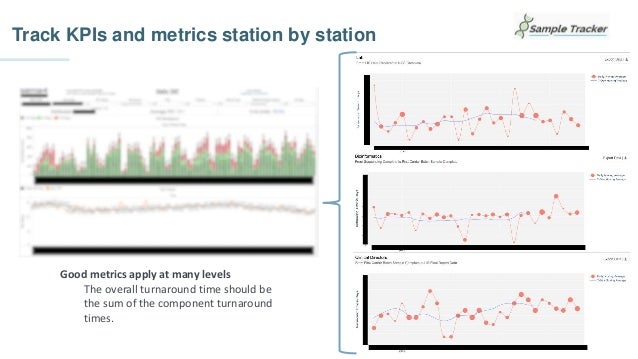
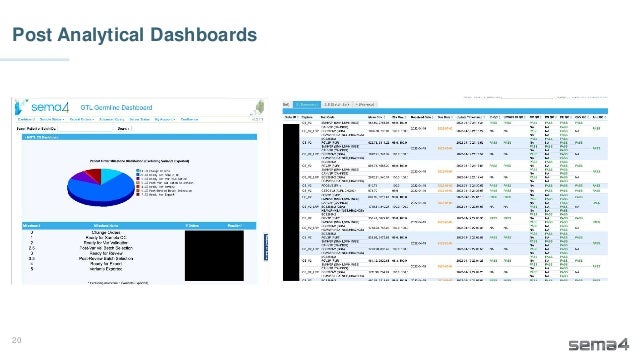
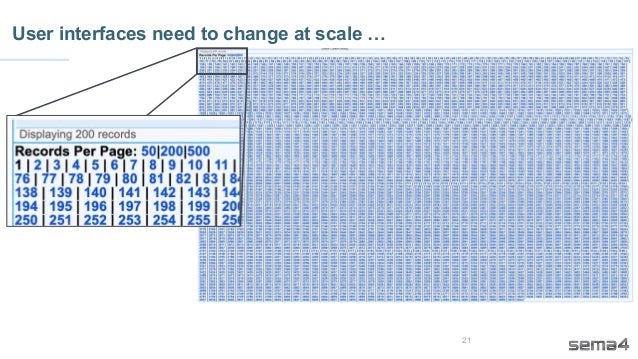


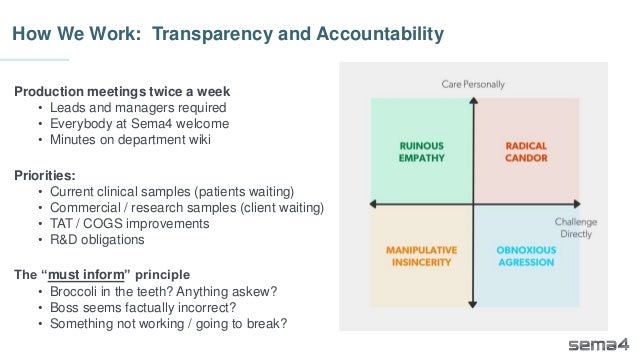




Chris Dwan emphasizes the importance of production bioinformatics and the integration of data-driven insights in healthcare at Sema4. Sema4 leverages AI and machine learning to transform clinical and genomic data into personalized health trajectories, offering various genomic tests and data platforms. The document details operational methodologies, data management techniques, and a focus on maintaining high quality and accountability in bioinformatics workflows.
















































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)


![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)















