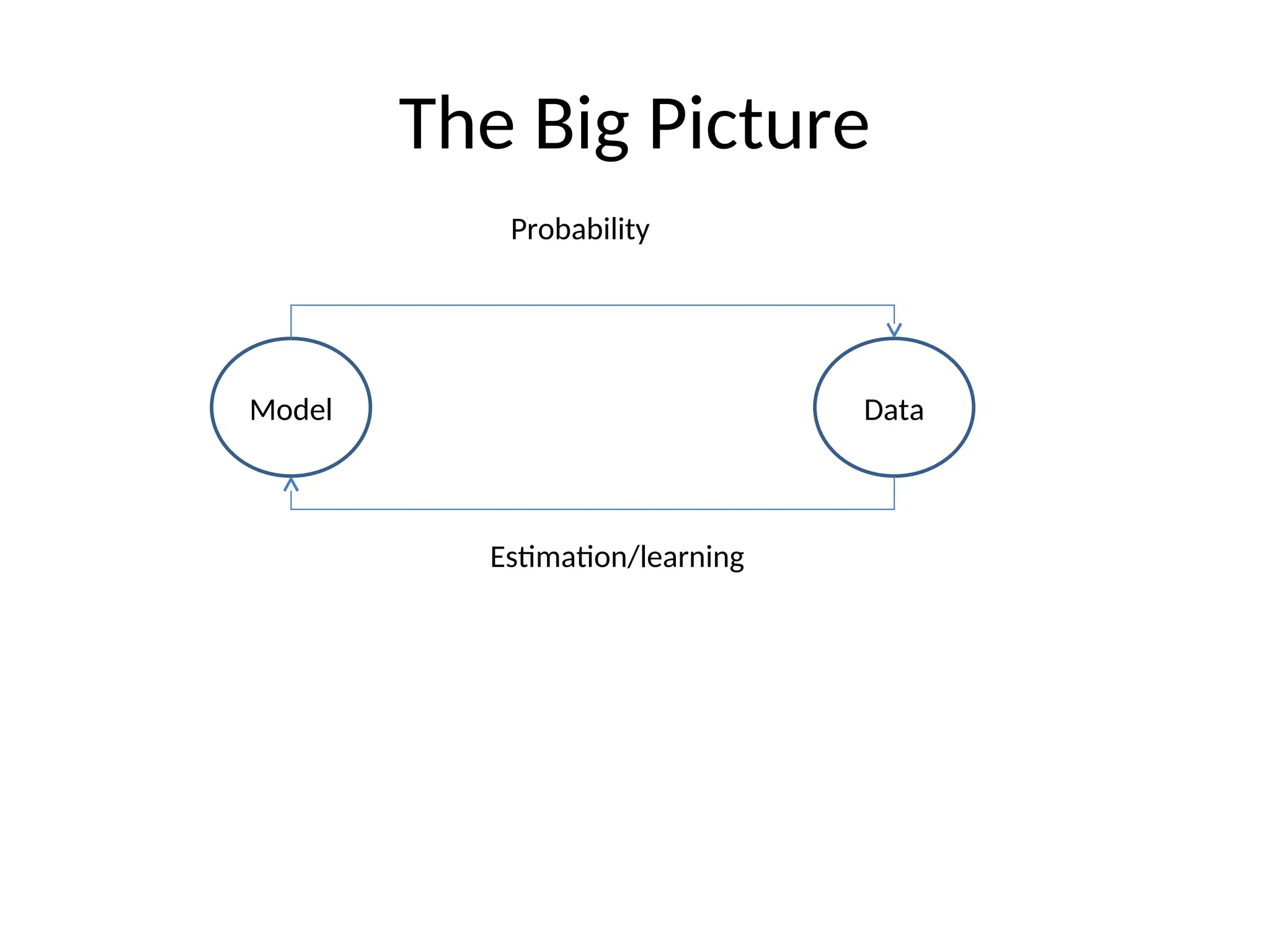
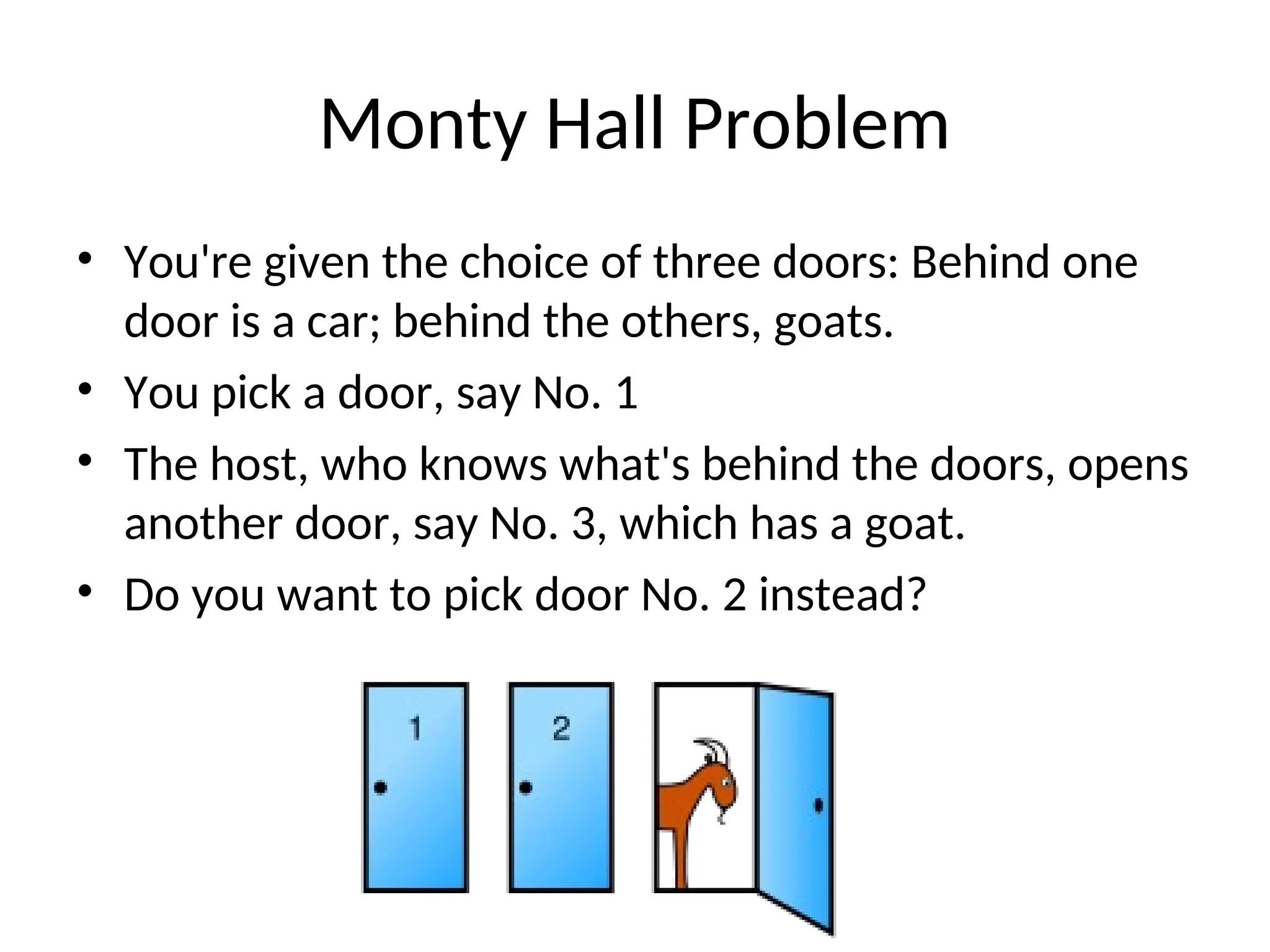
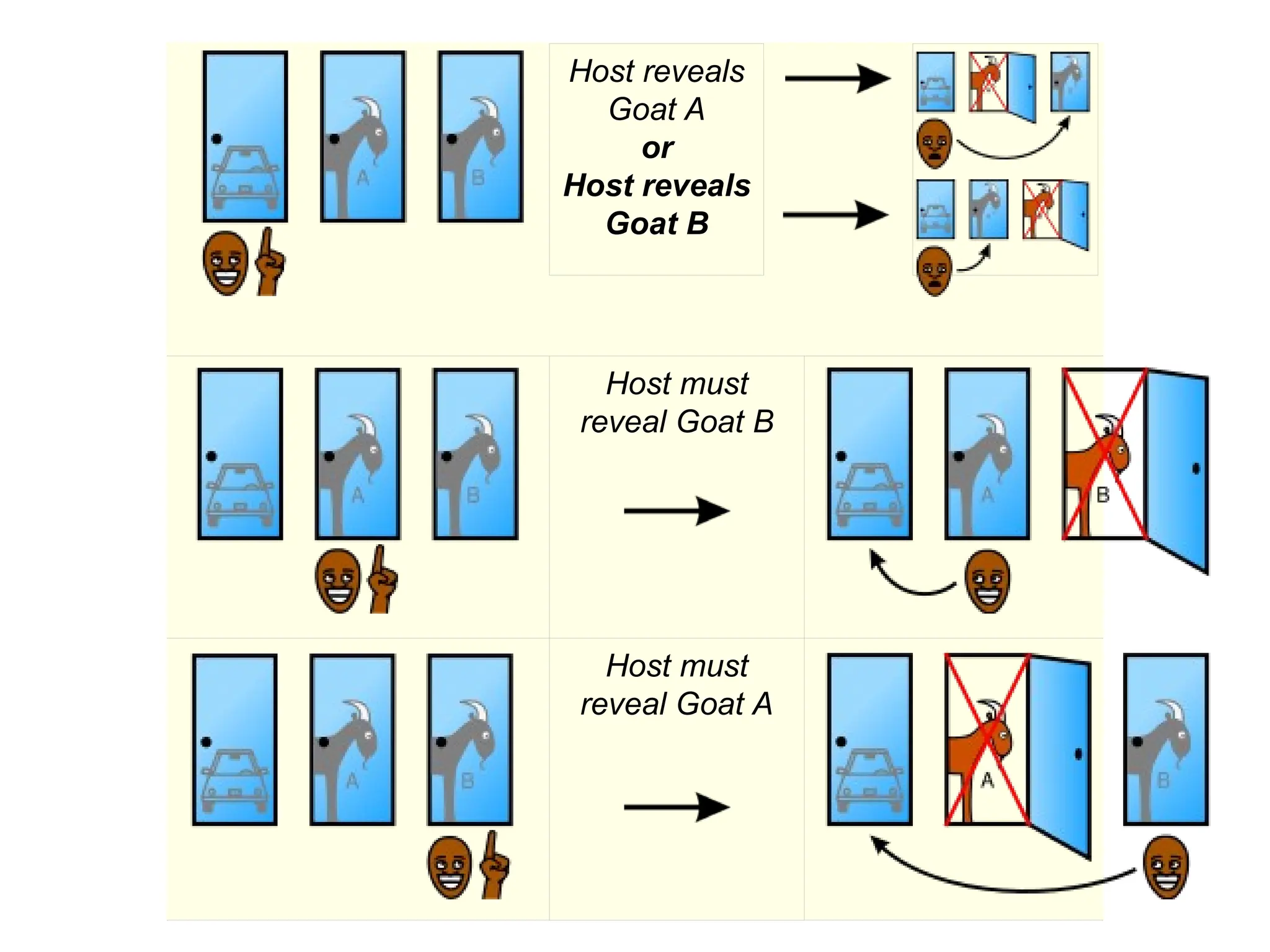
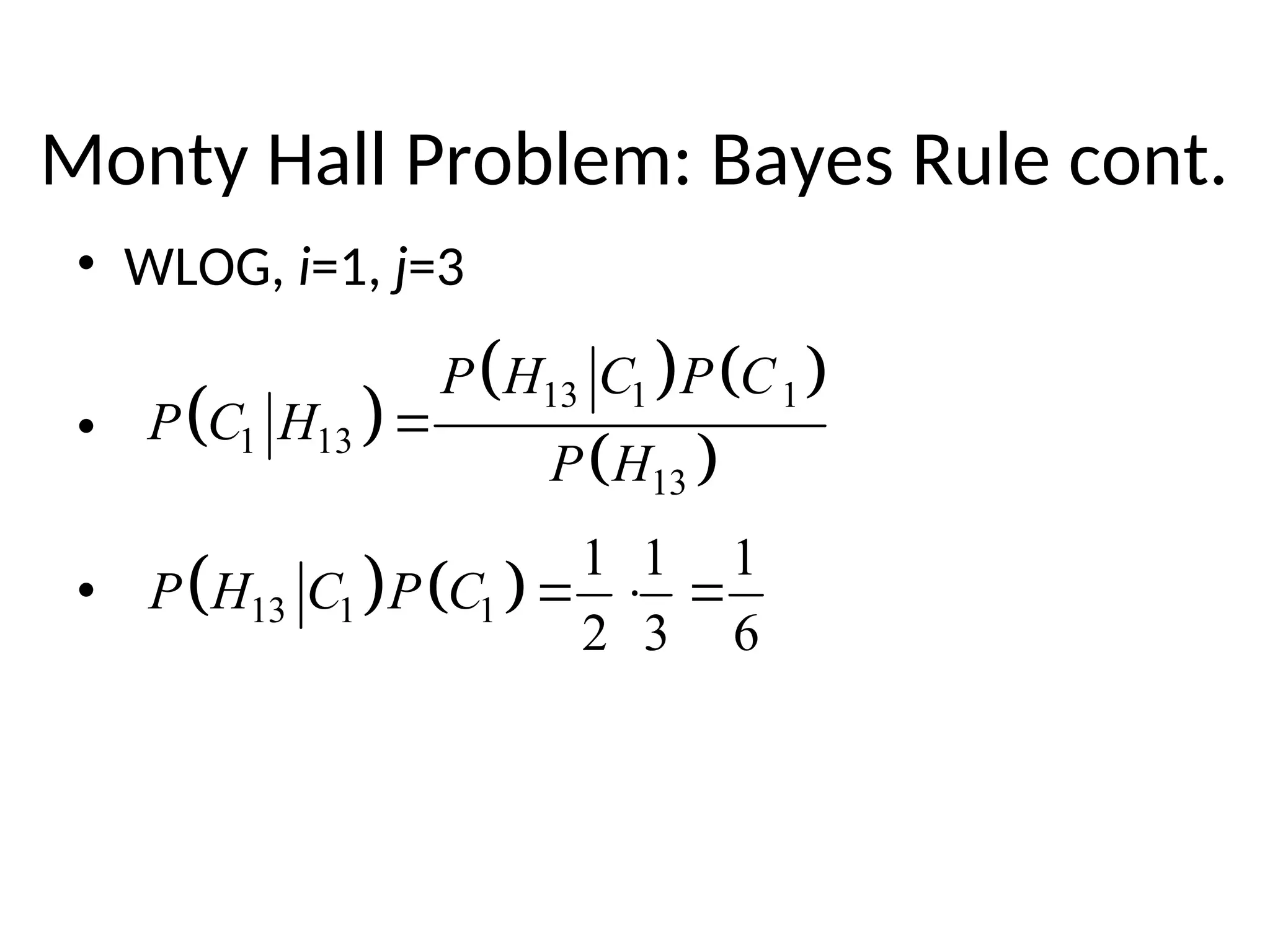The document reviews essential concepts in probability including events, random variables, joint distributions, independence, conditional probability, and their applications such as Bayes' rule and the Monty Hall problem. It covers both discrete and continuous random variables, their probability functions, and includes discussions on mean, variance, and covariance. The review emphasizes the importance of these concepts in statistical inference and modeling data.








![Common Distributions
• Uniform X U[1, …, N]
X takes values 1, 2, … N
P(X = i) = 1/N
E.g. picking balls of different colors from a box
• Binomial X Bin(n, p)
X takes values 0, 1, …, n
E.g. coin flips
p(X i)
n
i
pi
(1 p)n i](https://image.slidesharecdn.com/probabilityreview-250131014415-8cf9e31c/75/Introduction-Lesson-in-Probability-and-Review-12-2048.jpg)