Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
健青
Uploaded by
健児 青木
PDF, PPTX
12,307 views
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
第2回『トピックモデルによる統計的潜在意味解析』読書会 http://topicmodel.connpass.com/event/15783/
Data & Analytics
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
7
/ 24
8
/ 24
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PPTX
トピックモデルの基礎と応用
by
Tomonari Masada
ZIP
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PPTX
ブラックボックスからXAI (説明可能なAI) へ - LIME (Local Interpretable Model-agnostic Explanat...
by
西岡 賢一郎
PDF
[DL輪読会]Deep Learning 第2章 線形代数
by
Deep Learning JP
PDF
最適輸送入門
by
joisino
PDF
“機械学習の説明”の信頼性
by
Satoshi Hara
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
トピックモデルの基礎と応用
by
Tomonari Masada
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
ブラックボックスからXAI (説明可能なAI) へ - LIME (Local Interpretable Model-agnostic Explanat...
by
西岡 賢一郎
[DL輪読会]Deep Learning 第2章 線形代数
by
Deep Learning JP
最適輸送入門
by
joisino
“機械学習の説明”の信頼性
by
Satoshi Hara
What's hot
PPTX
【解説】 一般逆行列
by
Kenjiro Sugimoto
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
カステラ本勉強会 第三回
by
ke beck
PPTX
統計的学習の基礎_3章
by
Shoichi Taguchi
PDF
DeepLearning 輪読会 第1章 はじめに
by
Deep Learning JP
PDF
PRML輪読#2
by
matsuolab
PPTX
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
PDF
東京都市大学 データ解析入門 4 スパース性と圧縮センシング1
by
hirokazutanaka
PDF
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
by
Ken'ichi Matsui
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PPTX
15分でわかる(範囲の)ベイズ統計学
by
Ken'ichi Matsui
PDF
Chapter2.3.6
by
Takuya Minagawa
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
Rで階層ベイズモデル
by
Yohei Sato
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PDF
[DL輪読会]Deep Learning 第3章 確率と情報理論
by
Deep Learning JP
PDF
Rパッケージ“KFAS”を使った時系列データの解析方法
by
Hiroki Itô
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions
by
Deep Learning JP
【解説】 一般逆行列
by
Kenjiro Sugimoto
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
カステラ本勉強会 第三回
by
ke beck
統計的学習の基礎_3章
by
Shoichi Taguchi
DeepLearning 輪読会 第1章 はじめに
by
Deep Learning JP
PRML輪読#2
by
matsuolab
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
東京都市大学 データ解析入門 4 スパース性と圧縮センシング1
by
hirokazutanaka
科学と機械学習のあいだ:変量の設計・変換・選択・交互作用・線形性
by
Ichigaku Takigawa
ベイズ統計学の概論的紹介
by
Naoki Hayashi
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
by
Ken'ichi Matsui
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
15分でわかる(範囲の)ベイズ統計学
by
Ken'ichi Matsui
Chapter2.3.6
by
Takuya Minagawa
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
Rで階層ベイズモデル
by
Yohei Sato
研究効率化Tips Ver.2
by
cvpaper. challenge
[DL輪読会]Deep Learning 第3章 確率と情報理論
by
Deep Learning JP
Rパッケージ“KFAS”を使った時系列データの解析方法
by
Hiroki Itô
[DL輪読会]Understanding Black-box Predictions via Influence Functions
by
Deep Learning JP
Viewers also liked
PDF
強化学習勉強会・論文紹介(第50回)Optimal Asset Allocation using Adaptive Dynamic Programming...
by
Naoki Nishimura
PPTX
20150730 トピ本第4回 3.4節
by
MOTOGRILL
PDF
3.1節 統計的学習アルゴリズム
by
Akito Nakano
PDF
トピックモデルによる統計的潜在意味解析 2章後半
by
Shinya Akiba
PDF
3.3節 変分近似法(前半)
by
tn1031
PDF
第3章 変分近似法 LDAにおける変分ベイズ法・周辺化変分ベイズ法
by
ksmzn
PDF
「トピックモデルによる統計的潜在意味解析」読書会「第1章 統計的潜在意味解析とは」
by
ksmzn
PDF
逐次ベイズ学習 - サンプリング近似法の場合 -
by
y-uti
PDF
第二回機械学習アルゴリズム実装会 - LDA
by
Masayuki Isobe
PDF
Prism.Formsについて
by
一希 大田
PDF
AutoEncoderで特徴抽出
by
Kai Sasaki
PDF
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
強化学習勉強会・論文紹介(第50回)Optimal Asset Allocation using Adaptive Dynamic Programming...
by
Naoki Nishimura
20150730 トピ本第4回 3.4節
by
MOTOGRILL
3.1節 統計的学習アルゴリズム
by
Akito Nakano
トピックモデルによる統計的潜在意味解析 2章後半
by
Shinya Akiba
3.3節 変分近似法(前半)
by
tn1031
第3章 変分近似法 LDAにおける変分ベイズ法・周辺化変分ベイズ法
by
ksmzn
「トピックモデルによる統計的潜在意味解析」読書会「第1章 統計的潜在意味解析とは」
by
ksmzn
逐次ベイズ学習 - サンプリング近似法の場合 -
by
y-uti
第二回機械学習アルゴリズム実装会 - LDA
by
Masayuki Isobe
Prism.Formsについて
by
一希 大田
AutoEncoderで特徴抽出
by
Kai Sasaki
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
Similar to 読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PDF
PRML Chapter 11 (11.0-11.2)
by
Shogo Nakamura
PPTX
トピックモデル3章後半
by
Shuuji Mihara
PDF
KDD2014 勉強会
by
Ichigaku Takigawa
PDF
PRML11章
by
Takashi Tamura
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
PDF
Prml 10 1
by
正志 坪坂
PPTX
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
PPTX
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PDF
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
PDF
Prml11 4
by
正志 坪坂
PDF
PRML復々習レーン#11
by
Takuya Fukagai
PDF
13.2 隠れマルコフモデル
by
show you
PDF
PRML 8.2 条件付き独立性
by
sleepy_yoshi
PDF
トピックモデル3.1節
by
Akito Nakano
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
17th cvsaisentan takmin
by
Takuya Minagawa
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PRML Chapter 11 (11.0-11.2)
by
Shogo Nakamura
トピックモデル3章後半
by
Shuuji Mihara
KDD2014 勉強会
by
Ichigaku Takigawa
PRML11章
by
Takashi Tamura
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
Prml 10 1
by
正志 坪坂
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
ベイズ統計学の概論的紹介-old
by
Naoki Hayashi
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
Prml11 4
by
正志 坪坂
PRML復々習レーン#11
by
Takuya Fukagai
13.2 隠れマルコフモデル
by
show you
PRML 8.2 条件付き独立性
by
sleepy_yoshi
トピックモデル3.1節
by
Akito Nakano
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
17th cvsaisentan takmin
by
Takuya Minagawa
Recently uploaded
PPTX
KNIMEで奈良の気温を調べてみた_2026_0207_KNIMEST.pptx
by
syk zassou
PDF
研究資料ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
by
4fqg857pxh
PDF
EspressReport Enterprise Server ホワイトペーパー
by
株式会社クライム
PPTX
KNIMEは地味だが役に立つ_2026_0207_DojoMeeting_Kansai_#1.pptx
by
syk zassou
PPTX
What's New In Qlik ~ 2025年12月&2026年1月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
PPTX
【Qlik 医療データ活用勉強会】医療の質可視化アプリの公開-その2- 20260128
by
QlikPresalesJapan
KNIMEで奈良の気温を調べてみた_2026_0207_KNIMEST.pptx
by
syk zassou
研究資料ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
by
4fqg857pxh
EspressReport Enterprise Server ホワイトペーパー
by
株式会社クライム
KNIMEは地味だが役に立つ_2026_0207_DojoMeeting_Kansai_#1.pptx
by
syk zassou
What's New In Qlik ~ 2025年12月&2026年1月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
【Qlik 医療データ活用勉強会】医療の質可視化アプリの公開-その2- 20260128
by
QlikPresalesJapan
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
1.
1 読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法 日時:
2015/06/18 19:30~ 場所: 株式会社 ALBERT 発表者: @aoki_kenji
2.
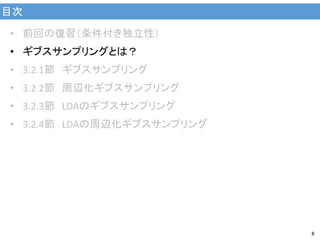
目次 2 • 前回の復習(条件付き独立性) • ギブスサンプリングとは? •
3.2.1節 ギブスサンプリング • 3.2.2節 周辺化ギブスサンプリング • 3.2.3節 LDAのギブスサンプリング • 3.2.4節 LDAの周辺化ギブスサンプリング 今回は時間の都合上省略
3.
目次 3 • 前回の復習(条件付き独立性) • ギブスサンプリングとは? •
3.2.1節 ギブスサンプリング • 3.2.2節 周辺化ギブスサンプリング • 3.2.3節 LDAのギブスサンプリング • 3.2.4節 LDAの周辺化ギブスサンプリング
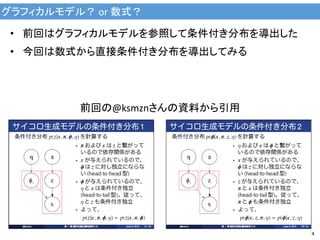
4.
グラフィカルモデル? or 数式? 4 前回の@ksmznさんの資料から引用 •
前回はグラフィカルモデルを参照して条件付き分布を導出した • 今回は数式から直接条件付き分布を導出してみる
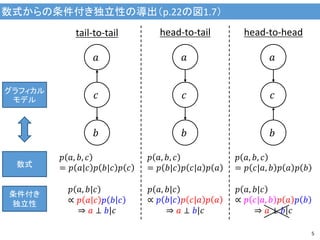
5.
数式からの条件付き独立性の導出(p.22の図1.7) 5 𝑏 𝑎 𝑐 𝑎 𝑏 𝑐 𝑎 𝑏 𝑐 tail-to-tail head-to-tail head-to-head 𝑝
𝑎, 𝑏, 𝑐 = 𝑝 𝑎|𝑐 𝑝 𝑏|𝑐 𝑝 𝑐 𝑝 𝑎, 𝑏|𝑐 ∝ 𝑝 𝑎 𝑐 𝑝 𝑏 𝑐 ⇒ 𝑎 ⊥ 𝑏|𝑐 𝑝 𝑎, 𝑏, 𝑐 = 𝑝 𝑏|𝑐 𝑝 𝑐|𝑎 𝑝 𝑎 𝑝 𝑎, 𝑏|𝑐 ∝ 𝑝 𝑏|𝑐 𝑝 𝑐|𝑎 𝑝 𝑎 ⇒ 𝑎 ⊥ 𝑏|𝑐 𝑝 𝑎, 𝑏, 𝑐 = 𝑝 𝑐|𝑎, 𝑏 𝑝 𝑎 𝑝 𝑏 𝑝 𝑎, 𝑏|𝑐 ∝ 𝑝 𝑐|𝑎, 𝑏 𝑝 𝑎 𝑝 𝑏 ⇒ 𝑎 ⊥ 𝑏|𝑐 グラフィカル モデル 数式 条件付き 独立性
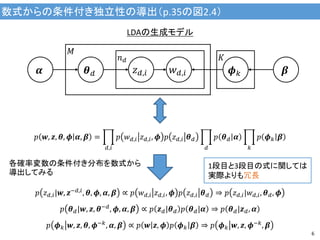
6.
数式からの条件付き独立性の導出(p.35の図2.4) 6 𝜷𝜶 LDAの生成モデル 𝑝 𝑧 𝑑,𝑖|𝒘,
𝒛−𝑑,𝑖, 𝜽, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖, 𝝓 𝑝 𝑧 𝑑,𝑖 𝜽 𝑑 ⇒ 𝑝 𝑧 𝑑,𝑖|𝑤 𝑑,𝑖, 𝜽 𝑑, 𝝓 𝑝 𝜽 𝑑|𝒘, 𝒛, 𝜽−𝑑 , 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝒛 𝑑|𝜽 𝑑 𝑝 𝜽 𝑑|𝜶 ⇒ 𝑝 𝜽 𝑑|𝒛 𝑑, 𝜶 𝑝 𝝓 𝑘 𝒘, 𝒛, 𝜽, 𝝓−𝑘, 𝜶, 𝜷 ∝ 𝑝 𝒘 𝒛, 𝝓 𝑝 𝝓 𝑘 𝜷 ⇒ 𝑝 𝝓 𝑘 𝒘, 𝒛, 𝝓−𝑘, 𝜷 𝝓 𝑘𝜽 𝑑 𝑧 𝑑,𝑖 𝑤 𝑑,𝑖 𝐾𝑛 𝑑 𝑀 𝑝 𝒘, 𝒛, 𝜽, 𝝓 𝜶, 𝜷 = 𝑝 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖, 𝝓 𝑝 𝑧 𝑑,𝑖 𝜽 𝑑 𝑑,𝑖 𝑝 𝜽 𝑑 𝜶 𝑑 𝑝 𝝓 𝑘 𝜷 𝑘 各確率変数の条件付き分布を数式から 導出してみる 1段目と3段目の式に関しては 実際よりも冗長
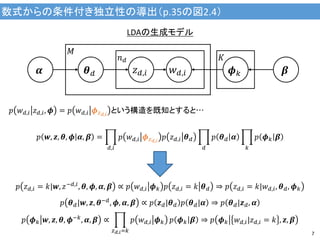
7.
数式からの条件付き独立性の導出(p.35の図2.4) 7 𝜷𝜶 LDAの生成モデル 𝑝 𝑧 𝑑,𝑖
= 𝑘|𝒘, 𝑧−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝑤 𝑑,𝑖 𝝓 𝑘 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝜽 𝑑 ⇒ 𝑝 𝑧 𝑑,𝑖 = 𝑘|𝑤 𝑑,𝑖, 𝜽 𝑑, 𝝓 𝑘 𝑝 𝜽 𝑑|𝒘, 𝒛, 𝜽−𝑑, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝒛 𝑑|𝜽 𝑑 𝑝 𝜽 𝑑|𝜶 ⇒ 𝑝 𝜽 𝑑|𝒛 𝑑, 𝜶 𝑝 𝝓 𝑘 𝒘, 𝒛, 𝜽, 𝝓−𝑘 , 𝜶, 𝜷 ∝ 𝑝 𝑤 𝑑,𝑖 𝝓 𝑘 𝑧 𝑑,𝑖=𝑘 𝑝 𝝓 𝑘 𝜷 ⇒ 𝑝 𝝓 𝑘 𝑤 𝑑,𝑖|𝑧 𝑑,𝑖 = 𝑘 , 𝒛, 𝜷 𝝓 𝑘𝜽 𝑑 𝑧 𝑑,𝑖 𝑤 𝑑,𝑖 𝐾𝑛 𝑑 𝑀 𝑝 𝒘, 𝒛, 𝜽, 𝝓 𝜶, 𝜷 = 𝑝 𝑤 𝑑,𝑖 𝝓 𝑧 𝑑,𝑖 𝑝 𝑧 𝑑,𝑖 𝜽 𝑑 𝑑,𝑖 𝑝 𝜽 𝑑 𝜶 𝑑 𝑝 𝝓 𝑘 𝜷 𝑘 𝑝 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖, 𝝓 = 𝑝 𝑤 𝑑,𝑖 𝝓 𝑧 𝑑,𝑖 という構造を既知とすると…
8.
目次 8 • 前回の復習(条件付き独立性) • ギブスサンプリングとは? •
3.2.1節 ギブスサンプリング • 3.2.2節 周辺化ギブスサンプリング • 3.2.3節 LDAのギブスサンプリング • 3.2.4節 LDAの周辺化ギブスサンプリング
9.
ギブスサンプリングのアルゴリズム概要 9 例えば 𝑝 𝑎, 𝑏,
𝑐|𝜃 から直接乱数を生成できないようなときでも、以下の手順(ギブスサンプリング)に よって上記分布からの乱数を生成することができる Step1: 𝑏, 𝑐の初期値𝑏 0 , 𝑐 0 と正数𝑆を与える Step2: 𝑠 = 1, ⋯ , 𝑆に対して以下を繰り返す 𝑝 𝑎 𝑠 |𝑏 𝑠−1 , 𝑐 𝑠−1 , 𝜃 から𝑎 𝑠 をサンプリング 𝑝 𝑏 𝑠 |𝑎 𝑠 , 𝑐 𝑠−1 , 𝜃 から𝑏 𝑠 をサンプリング 𝑝 𝑐 𝑠 |𝑎 𝑠 , 𝑏 𝑠 , 𝜃 から𝑐 𝑠 をサンプリング 上記の手順によって生成された乱数が𝑝 𝑎, 𝑏, 𝑐|𝜃 に従う理論的説明は、例えば • 伊庭他(2005)、『計算統計Ⅱマルコフ連鎖モンテカルロ法とその周辺 (統計科学のフロンティア12)』、岩波書店 を参照
10.
ギブスサンプリングのアルゴリズム概要 10 • もちろん上記の手順を実行するためには各確率変数の条件付き分布からの サンプリングが可能でなければならない (LDAの場合は条件付き分布が解析的に導出可能である) • 𝑎,
𝑏, 𝑐はそれぞれベクトル(多次元)であっても構わない(その場合はブロック 化ギブスサンプリングと呼ばれる) • 𝑎 𝑠 , 𝑏 𝑠 , 𝑐 𝑠 s=1 S を利用して、例えば𝑝 𝑎, 𝑏, 𝑐|𝜃 に関する任意の関数 𝑓 𝑎, 𝑏, 𝑐 の期待値を近似することができる 𝑝 𝑎, 𝑏, 𝑐|𝜃 𝑓 𝑎, 𝑏, 𝑐 𝑑𝑎𝑑𝑏𝑑𝑐 ≈ 1 𝑆 𝑓 𝑎 𝑠 , 𝑏 𝑠 , 𝑐 𝑠 𝑆 𝑠=1 • 実際は、上記のように𝑠 = 1から𝑆までの全てのサンプルを使わずに、初期値 に依存した最初の方のサンプルを捨てることがある このサンプルを捨てる期間を破棄する期間(burn-in period)と呼ぶ
11.
目次 11 • 前回の復習(条件付き独立性) • ギブスサンプリングとは? •
3.2.1節 ギブスサンプリング • 3.2.2節 周辺化ギブスサンプリング • 3.2.3節 LDAのギブスサンプリング • 3.2.4節 LDAの周辺化ギブスサンプリング
12.
ギブスサンプリングの動機 12 • LDAのベイズ推定では予測分布以前に事後分布のサンプル生成すら難しい ◎予測分布(積分計算が難しい) 𝑝 𝑤
𝑑 ∗ 𝒘, 𝜶, 𝜷 = 𝑝 𝑤 𝑑 ∗ , 𝑧 𝑑 ∗ , 𝒛, 𝜽, 𝝓 𝒘, 𝜶, 𝜷 𝒛𝑧 𝑑 ∗ 𝑑𝜽𝑑𝝓 = 𝑝 𝑤 𝑑 ∗ 𝝓 𝑧 𝑑 ∗ 𝑝 𝑧 𝑑 ∗ 𝜽 𝑑 𝑝 𝒛, 𝜽, 𝝓 𝒘, 𝜶, 𝜷 𝒛𝑧 𝑑 ∗ 𝑑𝜽𝑑𝝓 ◎事後分布からのサンプリングによる近似 (事後分布の導出が困難&サンプル生成が難しい) 𝑝 𝑤 𝑑 ∗ 𝒘, 𝜶, 𝜷 ≈ 1 𝑆 𝑝 𝑤 𝑑 ∗ 𝝓 𝑧 𝑑 ∗ 𝑠 𝑝 𝑧 𝑑 ∗ 𝜽 𝑑 𝑠 𝑧 𝑑 ∗ 𝑆 𝑠=1 • LDAの場合、 𝒛 𝑠 , 𝜽 𝑠 , 𝝓 𝑠 を一度にサンプリングするのは難しいが、 𝒛 𝑠 , 𝜽 𝑠 , 𝝓 𝑠 をそれぞれ個別にサンプリングすることは容易である(条件付き 分布が解析的に導出可能である) ギブスサンプリングによる近似が可能
13.
条件付き分布の導出その1 13 ◎𝑧 𝑑,𝑖について(𝑤 𝑑,𝑖
= 𝑣とする) 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝑤 𝑑,𝑖 = 𝑣, 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜽, 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝑤 𝑑,𝑖 = 𝑣 𝝓 𝑘 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝜽 𝑑 = 𝜙 𝑘,𝑣 𝜃 𝑑,𝑘 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝑤 𝑑,𝑖 = 𝑣, 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 = 1𝐾 𝑘=1 となるように正規化すると 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝑤 𝑑,𝑖 = 𝑣, 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜽, 𝝓, 𝜶, 𝜷 = 𝜙 𝑘,𝑣 𝜃 𝑑,𝑘 𝜙 𝑘′,𝑣 𝜃 𝑑,𝑘′ 𝐾 𝑘′=1
14.
条件付き分布の導出その2 14 ◎𝜽 𝑑について 𝑝 𝜽
𝑑 𝒘, 𝒛, 𝜽−𝑑 , 𝝓, 𝜶, 𝜷 ∝ 𝑝 𝒛 𝑑 𝜽 𝑑 𝑝 𝜽 𝑑 𝜶 ∝ 𝜃 𝑘 𝛼 𝑘+𝑛 𝑑,𝑘−1 𝐾 𝑘=1 ここで𝑛 𝑑,𝑘は文書𝑑の中でトピック𝑘に属する単語の数とする すなわち𝑛 𝑑,𝑘 = 𝛿 𝑧 𝑑,𝑖 = 𝑘 𝑛 𝑑 𝑖=1 上の式から𝑝 𝜽 𝑑 𝒘, 𝒛, 𝜽−𝑑 , 𝝓, 𝜶, 𝜷 はディリクレ分布の形をしているので 𝑝 𝜽 𝑑 𝒘, 𝒛, 𝜽−𝑑, 𝝓, 𝜶, 𝜷 = 𝐷𝑖𝑟 𝜽 𝑑|𝜶 + 𝒏 𝑑 , 𝒏 𝑑 = 𝑛 𝑑,1, ⋯ , 𝑛 𝑑,𝐾
15.
条件付き分布の導出その3 15 ◎𝝓 𝑘について 𝑝 𝝓
𝑘 𝒘, 𝒛, 𝜽, 𝝓−𝑘, 𝜶, 𝜷 ∝ 𝑝 𝑤 𝑑,𝑖 = 𝑣 𝝓 𝑘 𝑧 𝑑,𝑖=𝑘 𝑝 𝝓 𝑘 𝜷 ∝ 𝜙 𝑣 𝛽 𝑣+𝑛 𝑘,𝑣−1 𝑉 𝑣=1 ここで𝑛 𝑘,𝑣は全文書の中でトピック𝑘に属する単語𝑣の数とする すなわち𝑛 𝑘,𝑣 = 𝛿 𝑧 𝑑,𝑖 = 𝑘, 𝑤 𝑑,𝑖 = 𝑣 𝑛 𝑑 𝑖=1 𝑀 𝑑=1 上の式から𝑝 𝝓 𝑘 𝒘, 𝒛, 𝜽, 𝝓−𝑘 , 𝜶, 𝜷 はディリクレ分布の形をしているので 𝑝 𝝓 𝑘 𝒘, 𝒛, 𝜽, 𝝓−𝑘, 𝜶, 𝜷 = 𝐷𝑖𝑟 𝝓 𝑘|𝜷 + 𝒏 𝑘 , 𝒏 𝑘 = 𝑛 𝑘,1, ⋯ , 𝑛 𝑘,𝑉
16.
条件付き分布の導出まとめ 16 • どの確率変数𝑧 𝑑,𝑖,
𝜽 𝑑, 𝝓 𝑘に関しても 事後分布 ↓ 結合分布(生成モデル) ↓ 定数項を除外 のステップを踏むことにより条件付き事後分布を導出することができた
17.
LDAのギブスサンプリングの擬似コード 17 • 以下に、LDAのギブスサンプリングの擬似コードを示す • 𝜶,
𝜷の更新に関しては3.6節で取り扱う Step1: 𝜶, 𝜷, 𝜽, 𝝓の初期値𝜶 0 , 𝜷 0 , 𝜽 0 , 𝝓 0 と正数𝑆を与える Step2: 𝑠 = 1, ⋯ , 𝑆に対して以下を繰り返す 全ての𝑧 𝑑,𝑖に対して𝑝 𝑧 𝑑,𝑖|𝑤 𝑑,𝑖, 𝜽 𝑑 𝑠−1 , 𝝓 𝑘 𝑠−1 から𝑧 𝑑,𝑖 𝑠 をサンプリング 全ての𝜽 𝑑に対して𝑝 𝜽 𝑑|𝒛 𝑑 𝑠 , 𝜶 から𝜽 𝑑 𝑠 をサンプリング 全ての𝝓 𝑘に対して𝑝 𝝓 𝑘 𝑤 𝑑,𝑖|𝑧 𝑑,𝑖 𝑠 = 𝑘 , 𝒛 𝑠 , 𝜷 から𝝓 𝑘 𝑠 をサンプリング 𝜶, 𝜷を更新する:𝜶 𝑠−1 , 𝜷 𝑠−1 → 𝜶 𝑠 , 𝜷 𝑠
18.
目次 18 • 前回の復習(条件付き独立性) • ギブスサンプリングとは? •
3.2.1節 ギブスサンプリング • 3.2.2節 周辺化ギブスサンプリング • 3.2.3節 LDAのギブスサンプリング • 3.2.4節 LDAの周辺化ギブスサンプリング
19.
周辺化ギブスサンプリングの動機 19 • LDAのギブスサンプリングでは予測分布𝑝 𝑤
𝑑 ∗ 𝒘, 𝜶, 𝜷 を計算するために事後 分布から 𝒛 𝑠 , 𝜽 𝑠 , 𝝓 𝑠 𝑠=1 𝑆 をサンプリングした • より効率的なサンプリング方法として、𝜽, 𝝓を積分消去(周辺化)して𝒛のみを サンプリングする方法がある(逆は不可) • この方法は周辺化ギブスサンプリングと呼ばれる • 周辺化ギブスサンプリングでは以下のように予測分布を近似することになる 𝑝 𝑤 𝑑 ∗ 𝒘, 𝜶, 𝜷 = 𝑝 𝑤 𝑑 ∗ , 𝑧 𝑑 ∗ , 𝒛 𝒘, 𝜶, 𝜷 𝒛𝑧 𝑑 ∗ = 𝑝 𝑤 𝑑 ∗ , 𝑧 𝑑 ∗ 𝒘, 𝒛, 𝜶, 𝜷 𝑝 𝒛 𝒘, 𝜶, 𝜷 𝒛𝑧 𝑑 ∗ ≈ 1 𝑆 𝑝 𝑤 𝑑 ∗ , 𝑧 𝑑 ∗ 𝒘, 𝒛 𝑠 , 𝜶, 𝜷 𝑧 𝑑 ∗ 𝑆 𝑠=1 • 𝑝 𝑤 𝑑 ∗ , 𝑧 𝑑 ∗ 𝒘, 𝒛, 𝜶, 𝜷 の具体的な形については次ページ以降で導出する
20.
条件付き分布の導出その1 20 ◎𝑧 𝑑,𝑖の条件付き分布のみを導出すればよい(𝑤 𝑑,𝑖
= 𝑣とする) 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝑤 𝑑,𝑖, 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 ∝ 𝑝 𝑧 𝑑,𝑖 = 𝑘, 𝑤 𝑑,𝑖, 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 𝜶, 𝜷 = 𝑝 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 𝑝 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 ∝ 𝑝 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 = 𝑝 𝑤 𝑑,𝑖 = 𝑣 𝝓 𝑘 𝐷𝑖𝑟 𝝓 𝑘|𝜷 + 𝒏 𝑘 −𝑑,𝑖 𝑑𝝓 𝑘 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝜽 𝑑 𝐷𝑖𝑟 𝜽 𝑑|𝜶 + 𝒏 𝑑 −𝑑,𝑖 𝑑𝜽 𝑑 = 𝜙 𝑘,𝑣 𝐷𝑖𝑟 𝝓 𝑘|𝜷 + 𝒏 𝑘 −𝑑,𝑖 𝑑𝝓 𝑘 𝜃 𝑑,𝑘 𝐷𝑖𝑟 𝜽 𝑑|𝜶 + 𝒏 𝑑 −𝑑,𝑖 𝑑𝜽 𝑑 = 𝑛 𝑘,𝑣 −𝑑,𝑖 + 𝛽𝑣 𝑛 𝑘,𝑣′ −𝑑,𝑖 + 𝛽𝑣′ 𝑉 𝑣′=1 𝑛 𝑑,𝑘 −𝑑,𝑖 + 𝛼 𝑘 𝑛 𝑑,𝑘′ −𝑑,𝑖 + 𝛼 𝑘′ 𝐾 𝑘′=1 𝑛 𝑘,𝑣 −𝑑,𝑖 , 𝑛 𝑑,𝑘 −𝑑,𝑖 は𝑛 𝑘,𝑣, 𝑛 𝑑,𝑘の計算から𝑧 𝑑,𝑖を 抜いたもの ここの導出は次ページ に記載
21.
条件付き分布の導出その2 21 ◎𝑝 𝑤 𝑑,𝑖
𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 の計算に関して 𝑝 𝑤 𝑑,𝑖, 𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 = 𝑝 𝑤 𝑑,𝑖 = 𝑣 𝝓 𝑘 𝑝 𝑤 𝑑′,𝑖′ 𝝓 𝑘 𝑧 𝑑,𝑖=𝑘 𝑑′,𝑖′≠𝑑,𝑖 𝑝 𝝓 𝑘 𝜷 𝑑𝝓 𝑘 × 𝐹 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖 ≠ 𝑘 , 𝒛 𝑝 𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 = 𝑝 𝑤 𝑑′,𝑖′ 𝝓 𝑘 𝑧 𝑑,𝑖=𝑘 𝑑′,𝑖′≠𝑑,𝑖 𝑝 𝝓 𝑘 𝜷 𝑑𝝓 𝑘 × 𝐹 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖 ≠ 𝑘 , 𝒛 したがって 𝑝 𝑤 𝑑,𝑖 𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 = 𝑝 𝑤 𝑑,𝑖 = 𝑣 𝝓 𝑘 𝐷𝑖𝑟 𝝓 𝑘|𝜷 + 𝒏 𝑘 −𝑑,𝑖 𝑑𝝓 𝑘
22.
条件付き分布の導出その3 22 ◎𝑝 𝑧 𝑑,𝑖
= 𝑘 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 の計算に関して 𝑝 𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 = 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝜽 𝑑 𝑝 𝑧 𝑑,𝑖′ 𝜽 𝑑 𝑖′=𝑖 𝑝 𝜽 𝑑 𝜶 𝑑𝜽 𝑑 × 𝐹 𝑤−𝑑,𝑖, 𝒛−𝑑 𝑝 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 = 𝑝 𝑧 𝑑,𝑖′ 𝜽 𝑑 𝑖′=𝑖 𝑝 𝜽 𝑑 𝜶 𝑑𝜽 𝑑 × 𝐹 𝑤−𝑑,𝑖 , 𝒛−𝑑 したがって 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖 , 𝒛−𝑑,𝑖 , 𝜶, 𝜷 = 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝜽 𝑑 𝐷𝑖𝑟 𝜽 𝑑|𝜷 + 𝒏 𝑑 −𝑑,𝑖 𝑑𝜽 𝑑
23.
予測分布の具体的な形 23 ◎積み残しにしていた𝑝 𝑤 𝑑 ∗ ,
𝑧 𝑑 ∗ 𝒘, 𝒛, 𝜶, 𝜷 の具体的な形に関して 前ページまでの結果から 𝑝 𝑤 𝑑,𝑖 = 𝑣, 𝑧 𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 = 𝑝 𝑤 𝑑,𝑖 = 𝑣 𝑧 𝑑,𝑖 = 𝑘, 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 𝑝 𝑧 𝑑,𝑖 = 𝑘 𝒘−𝑑,𝑖, 𝒛−𝑑,𝑖, 𝜶, 𝜷 = 𝑛 𝑘,𝑣 −𝑑,𝑖 + 𝛽𝑣 𝑛 𝑘,𝑣′ −𝑑,𝑖 + 𝛽𝑣′ 𝑉 𝑣′=1 𝑛 𝑑,𝑘 −𝑑,𝑖 + 𝛼 𝑘 𝑛 𝑑,𝑘′ −𝑑,𝑖 + 𝛼 𝑘′ 𝐾 𝑘′=1 したがって 𝑝 𝑤 𝑑 ∗ = 𝑣, 𝑧 𝑑 ∗ = 𝑘 𝒘, 𝒛, 𝜶, 𝜷 = 𝑛 𝑘,𝑣 + 𝛽𝑣 𝑛 𝑘,𝑣′ + 𝛽𝑣′ 𝑉 𝑣′=1 𝑛 𝑑,𝑘 + 𝛼 𝑘 𝑛 𝑑,𝑘′ + 𝛼 𝑘′ 𝐾 𝑘′=1
24.
LDAの周辺化ギブスサンプリングの擬似コード 24 • 以下に、LDAの周辺化ギブスサンプリングの擬似コードを示す • 𝜶,
𝜷の更新に関しては3.6節で取り扱う Step1: 𝜶, 𝜷, 𝒛の初期値 𝜶 0 , 𝜷 0 , 𝒛 0 (=𝑛 𝑘,𝑣, 𝑛 𝑑,𝑘)と正数𝑆を与える Step2: 𝑠 = 1, ⋯ , 𝑆に対して以下を繰り返す 全ての𝑑, 𝑖 に対して以下を繰り返す 𝑛 𝑘,𝑣 −𝑑,𝑖 , 𝑛 𝑑,𝑘 −𝑑,𝑖 𝑘 = 1, ⋯ , 𝐾 を計算する 𝑛 𝑘,𝑣 −𝑑,𝑖 +𝛽 𝑣 𝑛 𝑘,𝑣′ −𝑑,𝑖 +𝛽 𝑣′ 𝑉 𝑣′=1 𝑛 𝑑,𝑘 −𝑑,𝑖 +𝛼 𝑘 𝑛 𝑑,𝑘′ −𝑑,𝑖 +𝛼 𝑘′ 𝐾 𝑘′=1 から𝑧 𝑑,𝑖 𝑠 をサンプリング 𝑛 𝑘,𝑣, 𝑛 𝑑,𝑘を更新する 𝜶, 𝜷を更新する:𝜶 𝑠−1 , 𝜷 𝑠−1 → 𝜶 𝑠 , 𝜷 𝑠
Download

























![[DL輪読会]Deep Learning 第2章 線形代数](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]Deep Learning 第3章 確率と情報理論](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning3-180601014703-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)





































