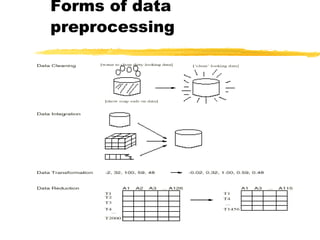
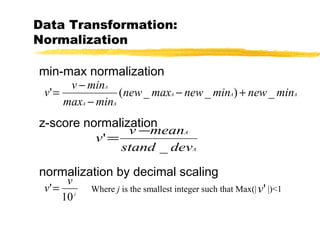
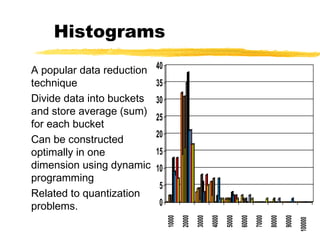
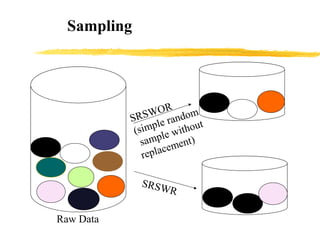
Data preprocessing involves cleaning data by handling missing values, outliers, and inconsistencies. It also includes integrating and transforming data from multiple sources through normalization, aggregation, and dimensionality reduction. The goals of preprocessing are to improve data quality, reduce data size for analysis, and prepare data for mining algorithms through techniques like discretization and concept hierarchy generation.