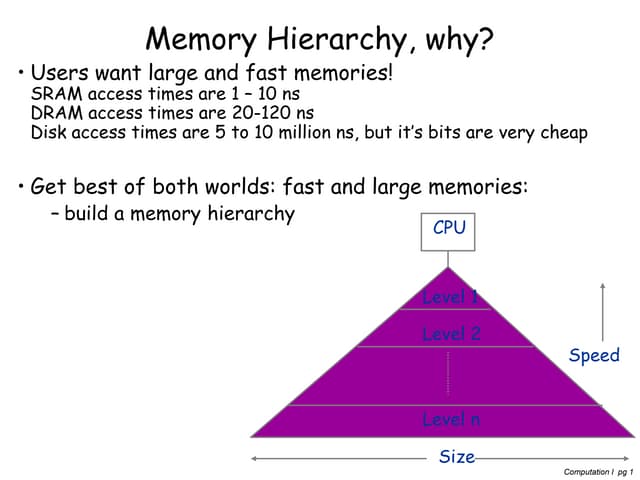
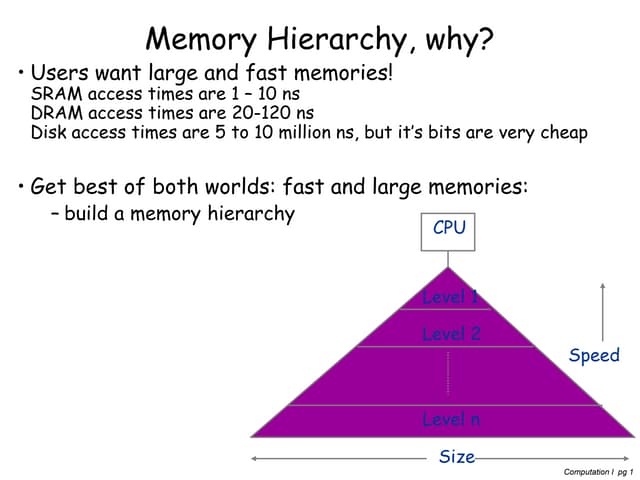
This document provides an overview of cache partitioning techniques (CPTs) in multicore processors. It begins with background on the motivation for CPTs due to increasing cache contention with more cores. It then covers various classifications of CPTs including granularity (way, set, block), static vs dynamic, strict vs pseudo, and hardware vs software control. It discusses challenges of CPTs like profiling overhead and complexity. It also covers techniques for profiling cache usage and determining optimal partitions. The goal of CPTs is to improve performance by reducing interference between applications sharing a cache.





















![Classification 3. Whether strict or pseudo
Strict (hard) CPT: cache quota is strictly enforced
Pseudo (soft) CPT: cache quota not strictly
enforced, actual allocation may differ from target quota
Ex.: 8-way cache, quota App1 =3 ways, App2 = 5 ways
Strict: Enforce [3,5] in all intervals
Pseudo: Quota = [3,5] in most intervals but [2,6] or
[4,4] in other intervals](https://image.slidesharecdn.com/pptoncachepartitioningtechniques-230417014743-7d5f77d0/85/PPT_on_Cache_Partitioning_Techniques-pdf-22-320.jpg)





![CPTs in real processors
Some Intel processors provides support for way-based
CP [Int16]
Page coloring-based CP [Lin08] in Linux kernel
Intel Xeon processor E5-2600 v3 family: support for
implementing shared cache QoS. It has
“cache monitoring technology” to track cache usage
“cache allocation technology” for allocating cache quotas,
e.g. to avoid cache starvation
AMD Opteron: pseudo-CPT to restrict cache quota of
cache-polluting apps
[Int16: Intel 64 and IA-32 Architectures Developer’s Manual: Vol. 3B http://goo.gl/sw24WL ]
[Lin08: Lin et al. HPCA’08]](https://image.slidesharecdn.com/pptoncachepartitioningtechniques-230417014743-7d5f77d0/85/PPT_on_Cache_Partitioning_Techniques-pdf-28-320.jpg)