





![Potter’s Wheel- features Instead of complex transform specifications with regular expressions or custom programs user specifies by example (e.g. splitting) Data auditing extensible with user defined domains Parse „Tayler, Jane, JFK to ORD on April 23, 2000 Coach“ as „[A-Za-z,]* <Airport> to <Airport> on <Date> <Class>“ instead of „[A-Za-z,]* [A-Z]³ to [A-Z]³ on [A-Za-z]* [0-9]*, [0-9]* [A-Za-z]* Allows easier detection of e.g. logical errors like false airport codes Potter‘s Wheel uses Minimun description length method to balance this tradeoff and choose appropriate structure Data auditing in background on the fly (data streaming also possible) Reorderer allows sorting on the fly User only works on a view – real data isn‘t changed until user exports set of transforms e.g. as C program an runs it on the real data Undo without problems: just delete unwanted transform from sequence and redo everything else](https://image.slidesharecdn.com/potterswheel-090522010107-phpapp01/85/Potter-S-Wheel-7-320.jpg)








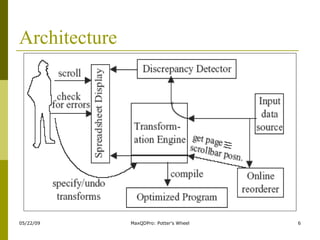
Potter's Wheel is an interactive tool for data transformation, cleaning and analysis. It integrates data auditing, transformation and analysis. The user can specify transformations by example through a spreadsheet interface. It detects discrepancies and flags them for the user. Transformations can be stored as programs to apply to data. It allows interactive exploration of data without waiting through partitioning and aggregation.





















































































