Download to read offline



![... and back to chaos...
Different team specialize on „local’ addresses [countrywise data
cleaning]
Standards (i.e. sequence in toponym, street name, number) differ
from country to country
Enrichments / links to other data may need special data structure
Eventually data parsing and cleaning will
produce very different results among different
workteams.
2](https://image.slidesharecdn.com/addrnamesstd-wash20111115b-121031061804-phpapp01/85/Sharing-names-and-address-cleaning-patterns-for-Patstat-3-320.jpg)

![Metadata structure proposal (II)
LAST_NAME Surname / company name
FIRST_NAME First name (blank for companies)
MIDDLE_NAME Second, third, 4th names … (blank for companies)
NAME_EXTENSION Jr/Sr/academic title; type of business entity in companies
ADDRESS Typically: toponym, name, number
LOCALITY City area (optional)
ADDR_OTHER Other specifics different than toponyms (floor, building, but
also c/o company name) [should be data not relevant for standardization]
CITY Municipality name
COUNTY Administrative level above municipality
REGION Administrative level above county
STATE Administrative level above region for federal nations
ZIP_CODE Alphanumeric zip code
4](https://image.slidesharecdn.com/addrnamesstd-wash20111115b-121031061804-phpapp01/85/Sharing-names-and-address-cleaning-patterns-for-Patstat-6-320.jpg)




![Pre-conditions: match patterns
Eventually, at string level, this is the core of our interchange format.
Our proposal is to use SQL REGEXP operator patterns as default, including the
following parameters
LIKE pattern to be found (inclusion criteria)
LIKE NOT [OPTIONAL] pattern not to be in (exclusion criteria)
POSITION (begin / end) start / end position where pattern can be
SQLSTANDARD gives the standard used for filling the
patterns (sql „dialect‟, like vs regexp…) in
order to make easier translation
10](https://image.slidesharecdn.com/addrnamesstd-wash20111115b-121031061804-phpapp01/85/Sharing-names-and-address-cleaning-patterns-for-Patstat-12-320.jpg)







![Appendix: Interchange data structure
proposal (I)
This is the list of the fields needed; where not indicated meaning of the field is
explained in previous slides
APPLICATION AUTHORITY 2 char string % may indicate valid for
all
COUNTRY CODE 2 char string % may indicate any
country
DATE FROM date [optional] empty means
no exclusion
DATE TO date [optional] empty means
no exclusion
PATSTATFROM MMYYYY [optional] empty means
no exclusion
PATSTATTO MMYYYY [optional] empty means
no exclusion
A1](https://image.slidesharecdn.com/addrnamesstd-wash20111115b-121031061804-phpapp01/85/Sharing-names-and-address-cleaning-patterns-for-Patstat-20-320.jpg)
![Interchange data structure proposal (II)
Where not indicated meaning of the field is explained in previous slides
ALIKE string (is not called LIKE cause it may
cause errors in some SQL )
LIKE NOT [OPTIONAL] string
FIND string
FIND2 string when literal find do not work
and we need a fix len
REPLACE string
POSFROM integer start point of string position
POSTO integer end of position where string can be
SQLSTANDARD string
A1](https://image.slidesharecdn.com/addrnamesstd-wash20111115b-121031061804-phpapp01/85/Sharing-names-and-address-cleaning-patterns-for-Patstat-21-320.jpg)

![Appendix2: Some examples
ID 1 2 99 100 106
OPERATIONKIND EEED EEEE BBBB BBBB BBBB
APPLICATION AUTHORITY EP % % % %
COUNTRY CODE US % % % %
PO BOX [0-9][0-
LIKE 9][0-9][0-9] %,,% '[0-9] - [0-9]' '[0-9] BIS [0-9]' '[0-9] A [0-9]'
LIKE NOT ' - .+ - ' ' BIS .+ BIS ' ' A .+ A '
FIND PO BOX ,, '-' ' BIS ' 'A'
FIND2 PO BOX ####
REPLACE , '-' '-' '-'
POSFROM 1 1 2 2 2
POSTO 1 9999 9999 9999 9999
SQLSTANDARD MYSQL50 MYSQL50 MYSQL50 MYSQL50 MYSQL50
DATE FROM
DATE TO
PATSTATFROM
PATSTATTO
moves PO BOX Removes these are different formats aiming to set multiple street
DESCRIPTION from city to double comma number in address to format #-#
addr_other in city
A2](https://image.slidesharecdn.com/addrnamesstd-wash20111115b-121031061804-phpapp01/85/Sharing-names-and-address-cleaning-patterns-for-Patstat-23-320.jpg)

![Appendix 3: Deep into one pattern (II):
“WAGNER STRASSE 3 BIS 12” VS “ BIS “
update applicant a, corrections b
set a.address=trim(concat( new address field is trimmed aggregation
LEFT(a.address, INSTR(a.address,b.find)-1), of what was before the change (“WAGNER
b.replace, STRASSE 3“)
“-“
right(a.address, LENGTH(a.address) -
length(b.find)-INSTR(a.address, “12”
b.find)+1) ))
where
b.OPERATIONKIND = “BBBB”
INSTR(a.address, b.find) >= b.posfrom this means “ – “ is from position 2 onward
and INSTR(a.address, b.find) <= b.POSTO this means “ – “ is before position 9999
and a.address regexp b.like address contains reg. expr. '[0-9] BIS [0-9]'
and a. address not regexp b.likenot addr. don‟t contain ' BIS .+ BIS „that means twice„ BIS
and b.datefrom is null and b.dateto is null and „
no criteria on date or patstat ediction
b.pastatfrom is null and b.pastatto is null;
A3](https://image.slidesharecdn.com/addrnamesstd-wash20111115b-121031061804-phpapp01/85/Sharing-names-and-address-cleaning-patterns-for-Patstat-25-320.jpg)

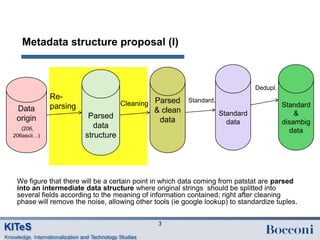
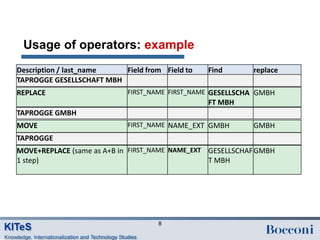
This document proposes a data structure for standardizing person metadata, such as inventor and applicant names and addresses, extracted from patent documents. It discusses: - Four main steps to cleaning and standardizing person data: re-parsing, cleaning, standardization, and deduplication. - Challenges with different teams specializing in local address cleaning and varying address standards between countries. - A proposed metadata structure splitting name and address fields into standardized subfields like first name, last name, street, city, etc. - Operators for cleaning like map+correct to transform strings between fields while correcting errors, and conditions for applying transformations based on country, time period, or text patterns in the data




























































