Download as PDF, PPTX



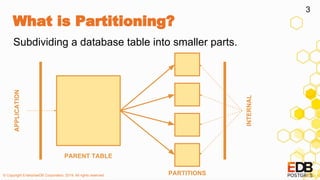
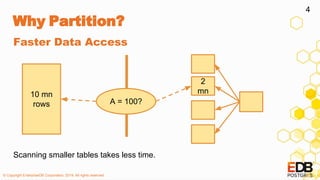
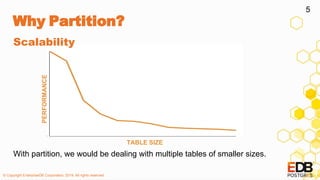
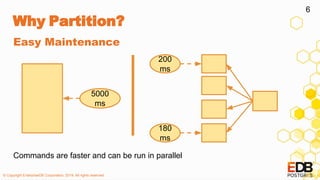










![© Copyright EnterpriseDB Corporation, 2019. All rights reserved.
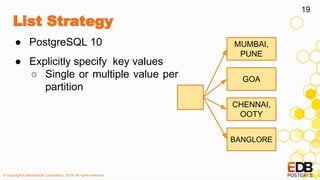
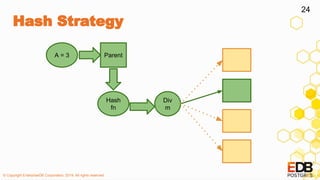
List Strategy
● Create Partitioned Table
CREATE TABLE parent ( <col list > )
PARTITION BY LIST ( <partition key> );
● Create Partitions
CREATE TABLE child PARTITION OF parent
FOR VALUES
IN ( <val1> [, <val2>] ) ;
20](https://image.slidesharecdn.com/postgresqldecodingpartitionfinal1-190214115324/85/PostgreSQL-Decoding-Partitions-20-320.jpg)










![© Copyright EnterpriseDB Corporation, 2019. All rights reserved.
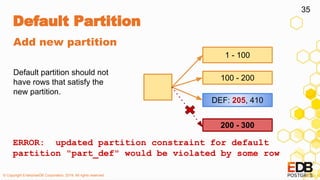
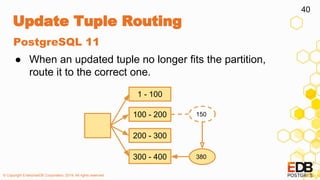
● PostgreSQL 11
● Catch tuples that do not match
partition bounds of others.
● Support for: list, range
● Syntax:
CREATE TABLE child
PARTITION OF parent
DEFAULT
A
B
C
DEFAULT
Default Partition
Z
(NOT (col1 IS NOT NULL) AND
(col1 = ANY (ARRAY[ 'A', 'B', 'C' ])))
34](https://image.slidesharecdn.com/postgresqldecodingpartitionfinal1-190214115324/85/PostgreSQL-Decoding-Partitions-34-320.jpg)





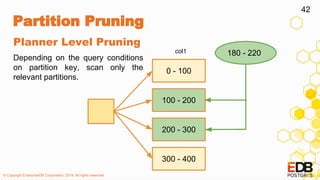



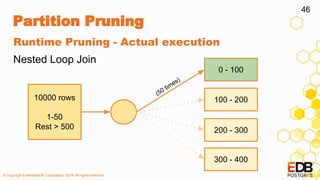



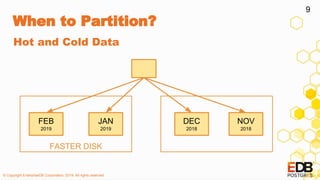
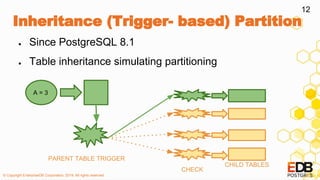
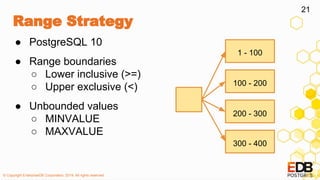
The document provides a detailed overview of partitioning in PostgreSQL, discussing its definitions, benefits, and various partitioning strategies such as list, range, and hash. It explains when to partition, cautions against poor partitioning practices, and describes declarative partitioning introduced in PostgreSQL 10, which simplifies partition management. Additionally, the document covers advanced features like multi-column partitioning, foreign table partitions, and partition pruning enhancements in PostgreSQL 11.





















































