Downloaded 26 times








![Partitioning Predicate usage in query: CREATE PARTITION FUNCTION RangePF1 ( int ) AS RANGE FOR VALUES (10, 100, 1000) ; SELECT $PARTITION.RangePF1 (10) ; GO SELECT $PARTITION.TransactionRangePF1(TransactionDate) AS Partition, COUNT(*) AS [COUNT] FROM Production.TransactionHistory GROUP BY PARTITION.TransactionRangePF1(TransactionDate) ORDER BY Partition ;](https://image.slidesharecdn.com/sqlserver2008performanceenhancements-110311084205-phpapp01/85/SQL-Server-2008-Performance-Enhancements-10-320.jpg)














![MERGE Statement Outperforms equivalent multiple statement query which achieve the same query goal. Simplifies multiple operations in 1 query syntax – easy to read and understand. MERGE INTO [AdventureWorks].[Person].[Contact_Base] AS Target USING ( SELECT ContactID,Title,FirstName,MiddleName,LastName,EmailAddress FROM [AdventureWorks].[Person].[Contact_Temp]) AS Source (ContactID,Title,FirstName,MiddleName,LastName,EmailAddress) ON Target.ContactID = Source.ContactID WHEN MATCHED THEN UPDATE SET EmailAddress = Source.EmailAddress WHEN NOT MATCHED BY TARGET THEN INSERT (ContactID,Title,FirstName,MiddleName,LastName,EmailAddress) VALUES (ContactID,Title,FirstName,MiddleName,LastName,EmailAddress);](https://image.slidesharecdn.com/sqlserver2008performanceenhancements-110311084205-phpapp01/85/SQL-Server-2008-Performance-Enhancements-26-320.jpg)


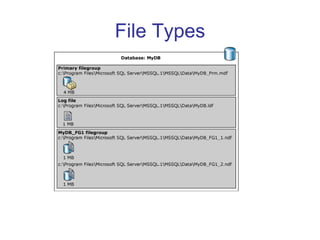
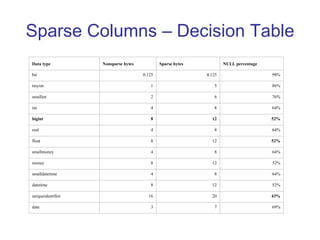
This document summarizes several performance improvements introduced in SQL Server 2008 including partitioning enhancements, sparse columns, filtered indexes, plan freezing, and the MERGE statement. It provides information on how each feature works and example use cases.



































































