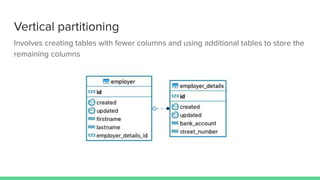
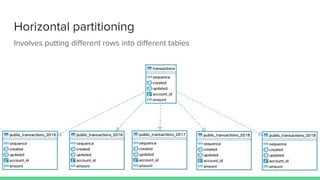
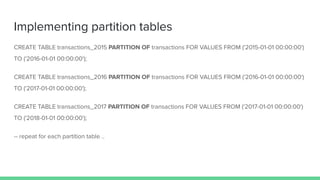
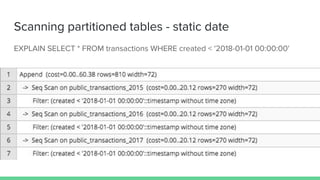
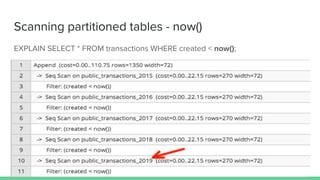
PostgreSQL 10 introduced improvements to table partitioning. Table partitioning involves splitting a logically single table into smaller physical tables. The benefits of partitioning include improved query performance for SQL queries, the ability to bulk load and delete partitions efficiently, and migrating seldom-used data to cheaper storage. PostgreSQL 11 will further enhance partitioning by allowing updates to move rows between partitions, global unique indexes, and default partitions. While partitioning provides benefits, it also has limitations and requires care to implement properly.