Downloaded 126 times







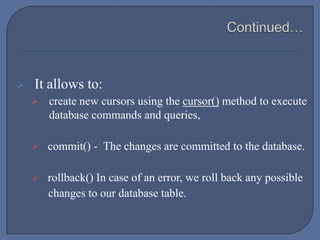










![ The Python string operator % is not used: the execute() method accepts a
tuple or dictionary of values as second parameter.
For positional variables binding, the second argument must always be a
sequence, even if it contains a single variable:
cur.execute("INSERT INTO foo VALUES (%s)", "bar") # WRONG
cur.execute("INSERT INTO foo VALUES (%s)", ("bar")) # WRONG
cur.execute("INSERT INTO foo VALUES (%s)", ("bar",)) # correct
cur.execute("INSERT INTO foo VALUES (%s)", ["bar"]) # correct](https://image.slidesharecdn.com/psycopg2-140427081409-phpapp01/85/Psycopg2-Connect-to-PostgreSQL-using-Python-Script-19-320.jpg)









This document provides an overview of connecting to PostgreSQL databases using Python, particularly through the psycopg2 adapter and pygresql module. It includes instructions on installation, creating connections, executing SQL commands, handling transactions, and using different types of cursors for data retrieval. The document also elaborates on various functionalities and methods available in the psycopg2 library for database interactions.




























![Connecting and using PostgreSQL database with psycopg2 [Python 2.7]](https://cdn.slidesharecdn.com/ss_thumbnails/database-psycopg2-181228131207-thumbnail.jpg?width=640&height=640&fit=bounds)






































