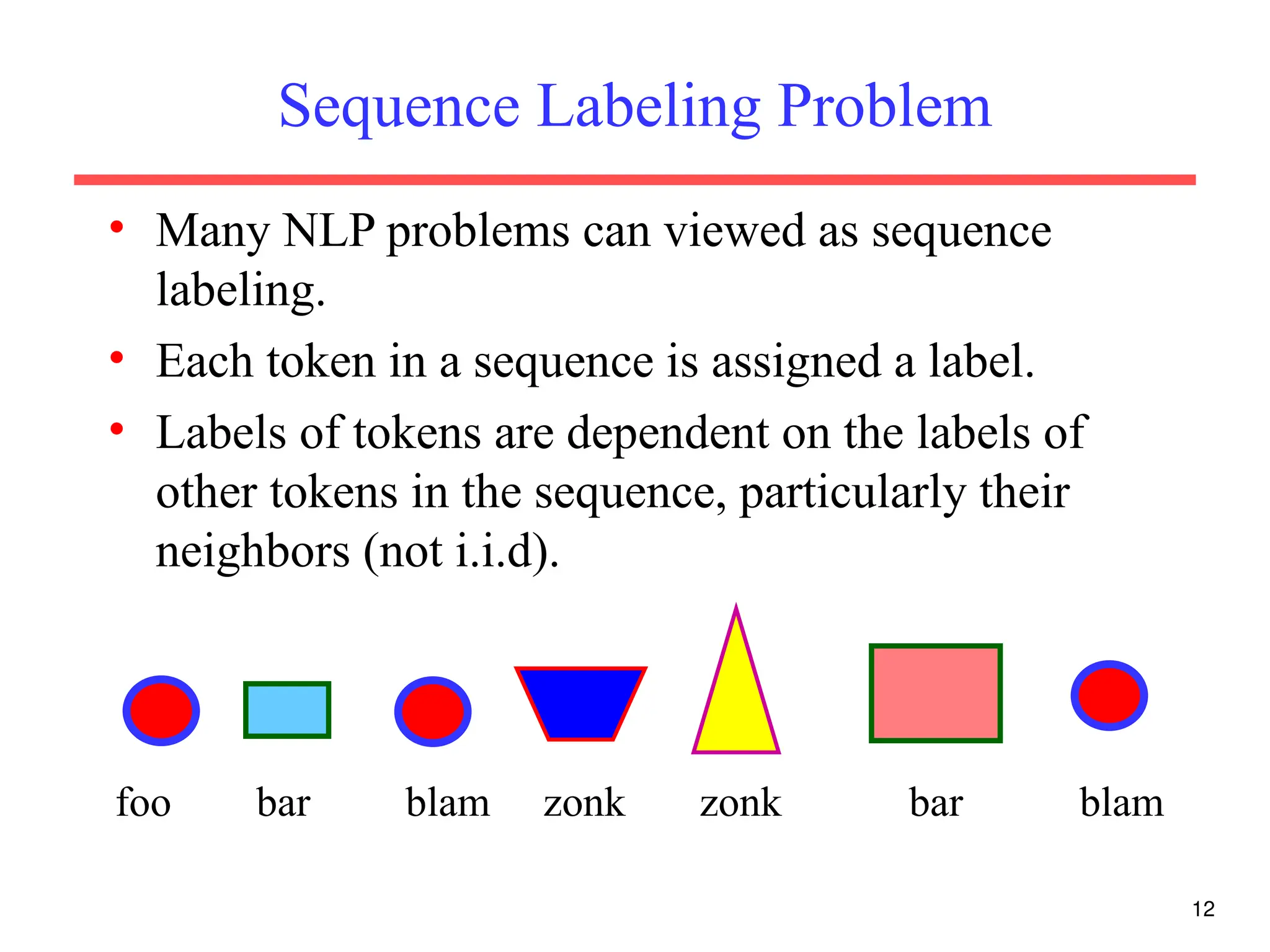
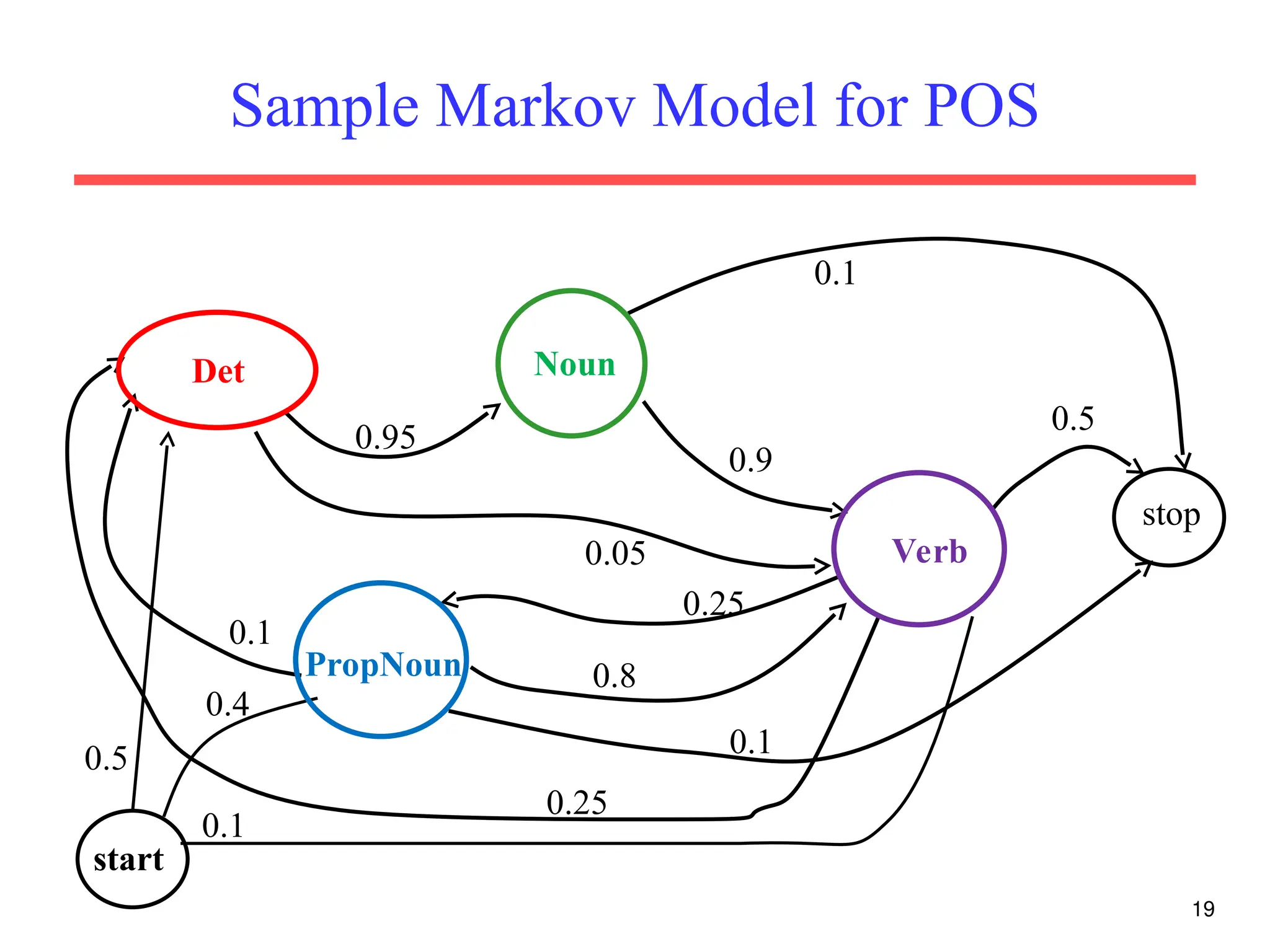
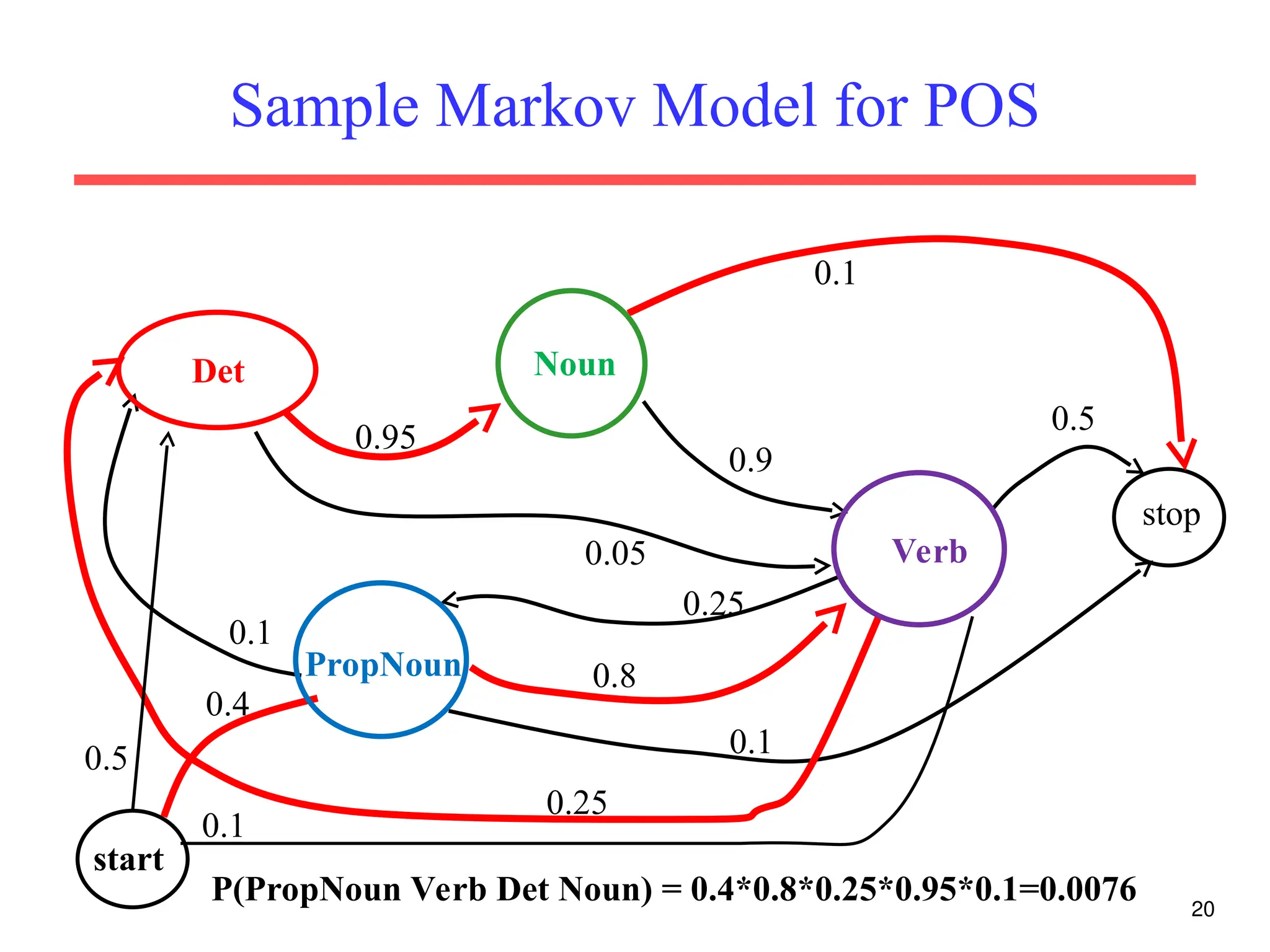
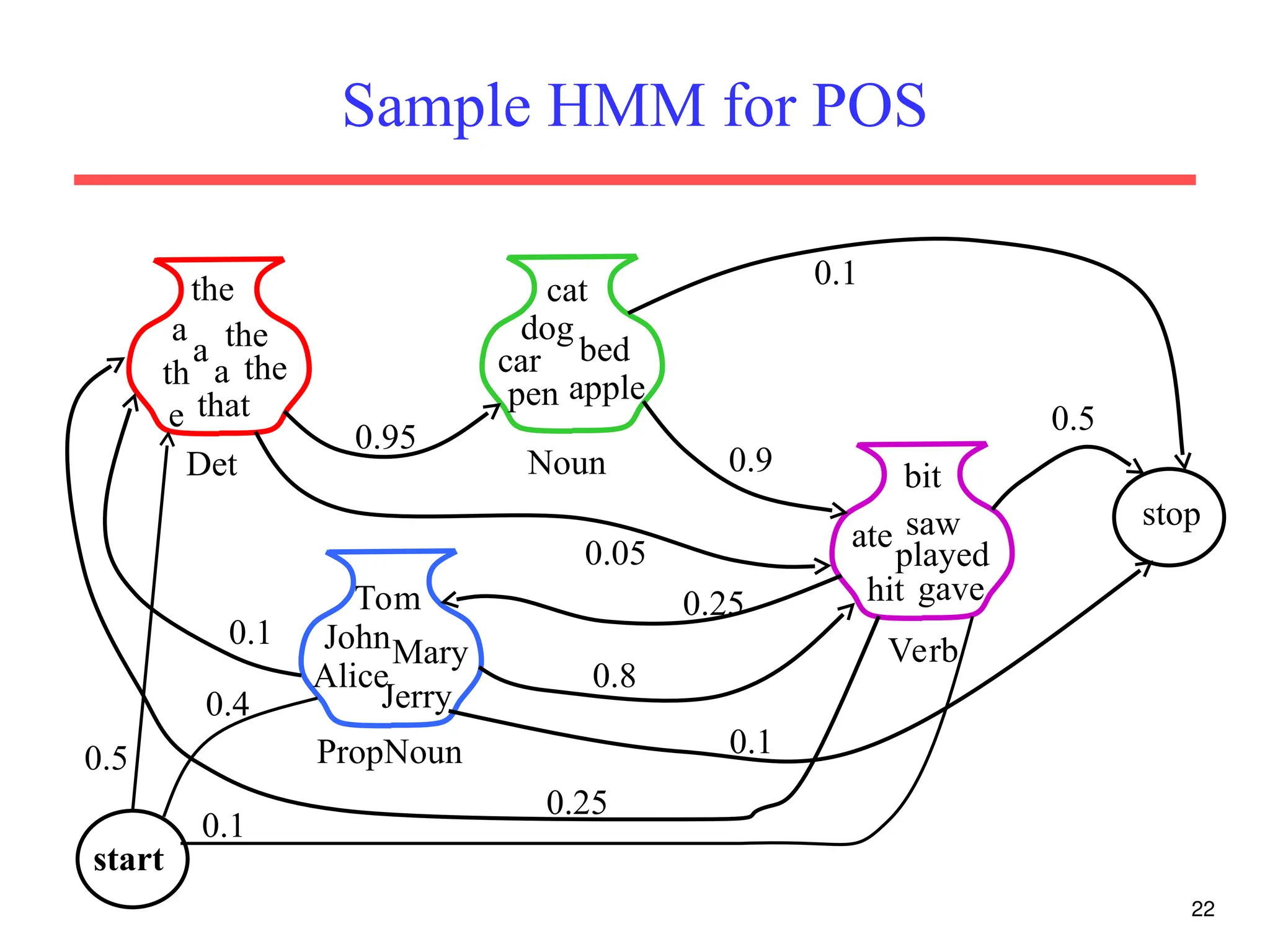
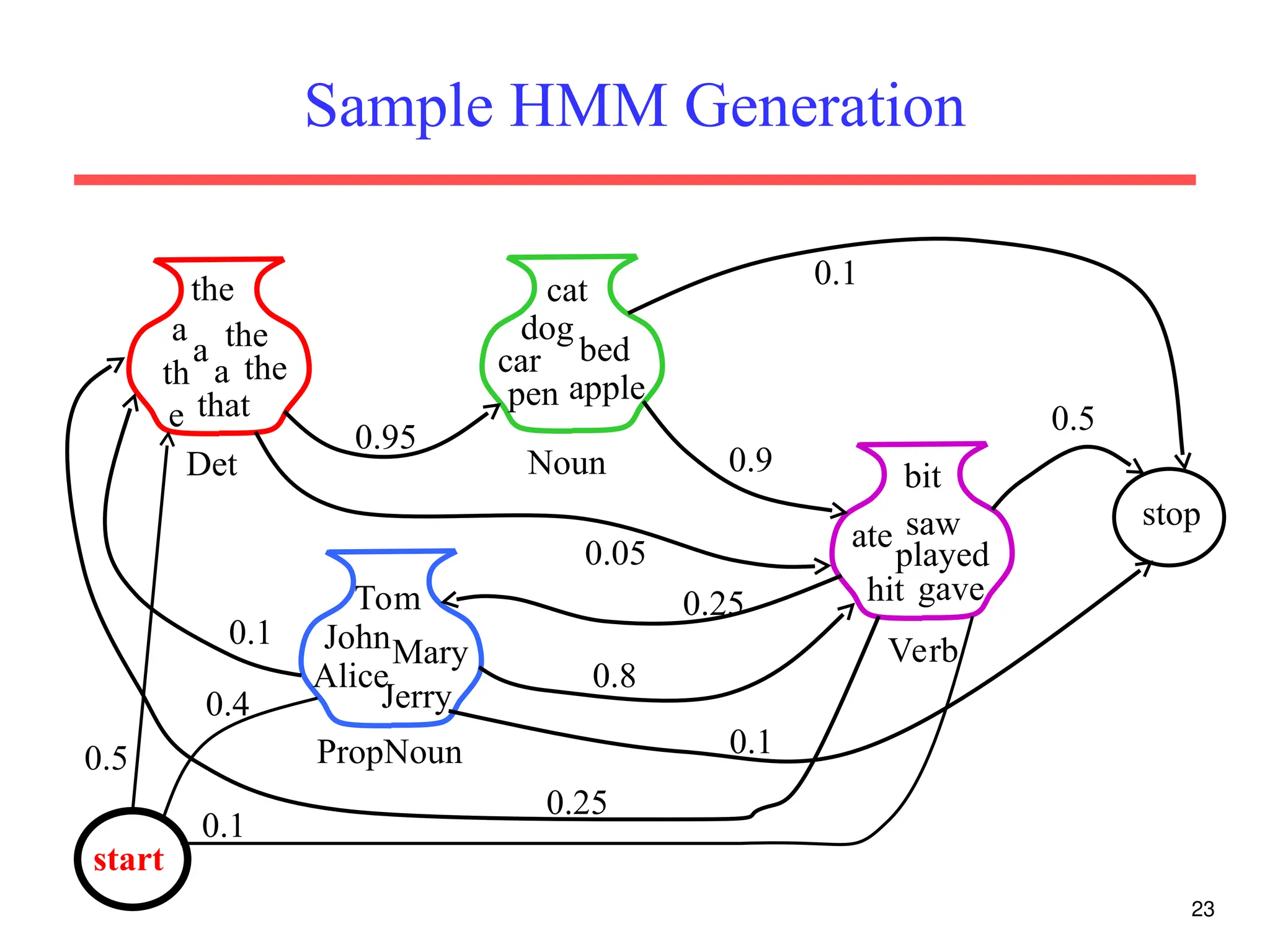
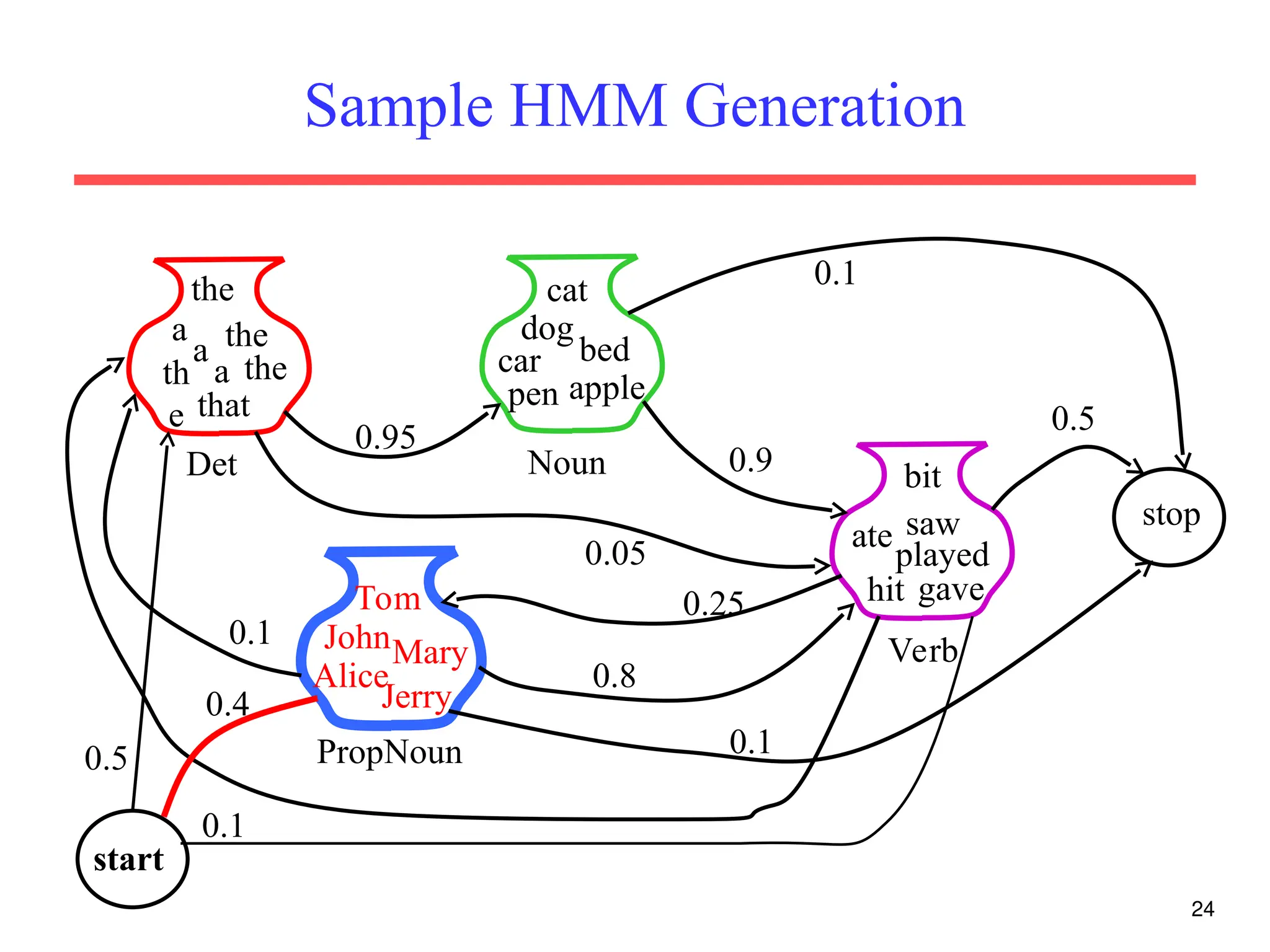
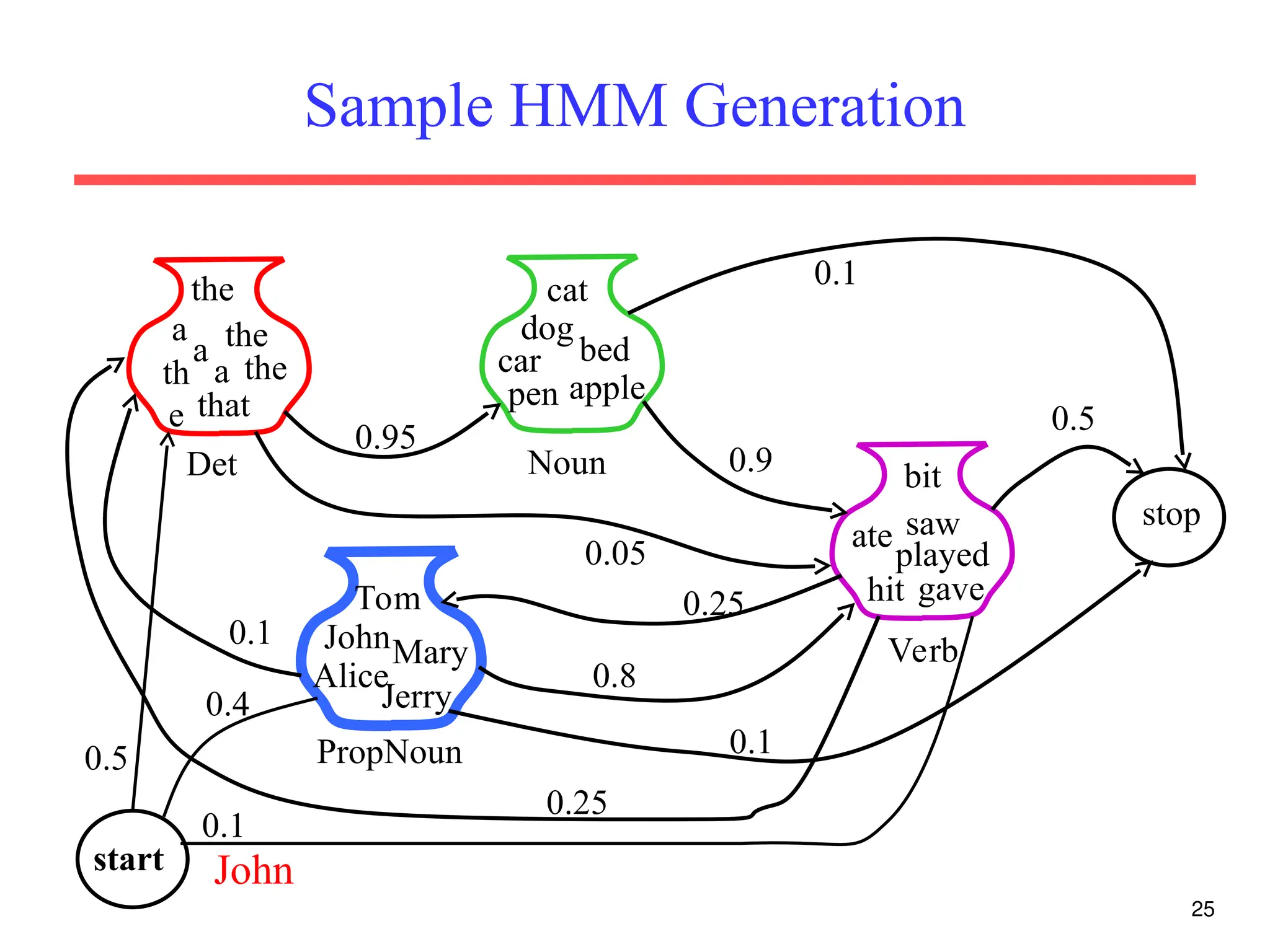
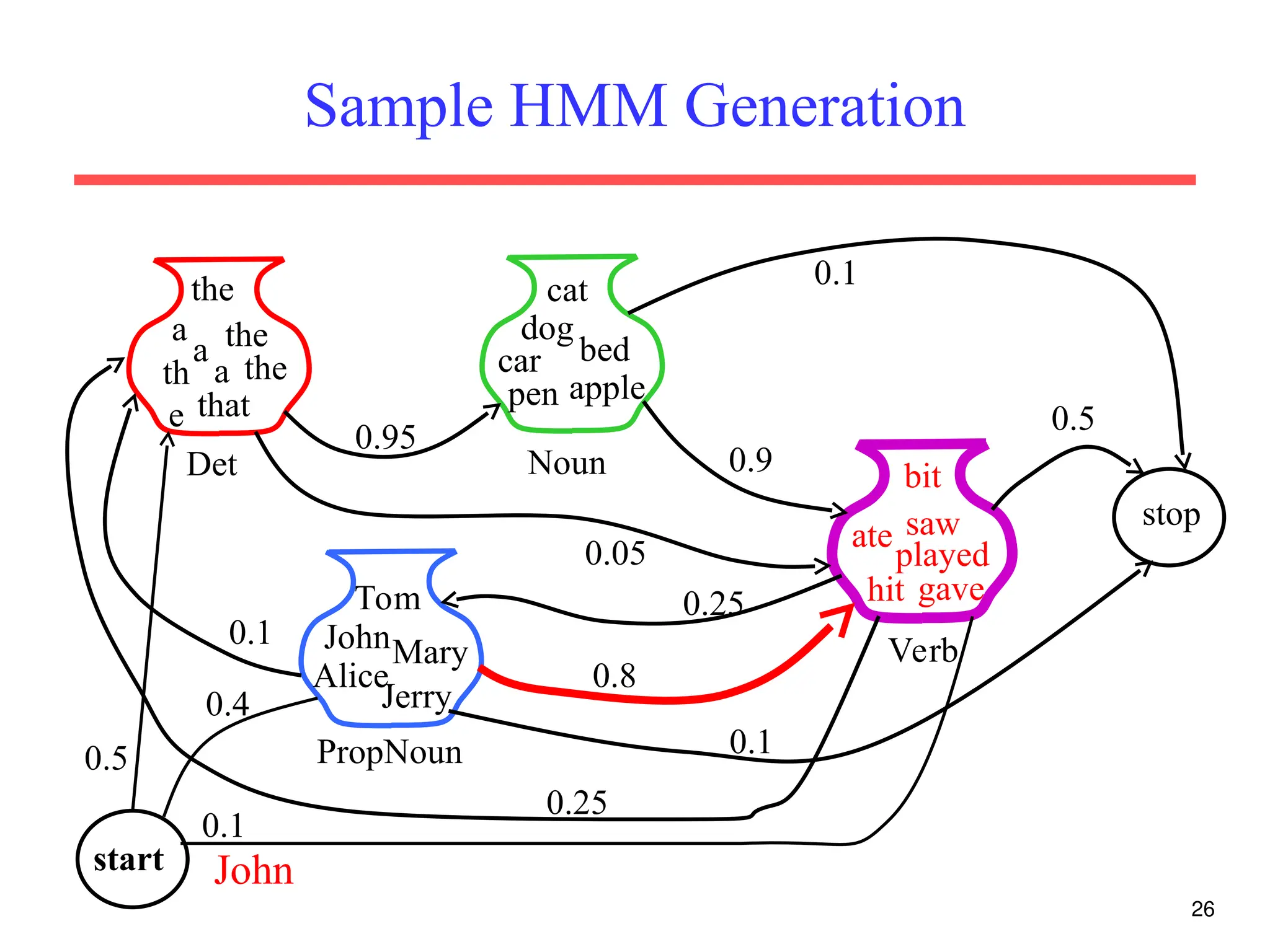
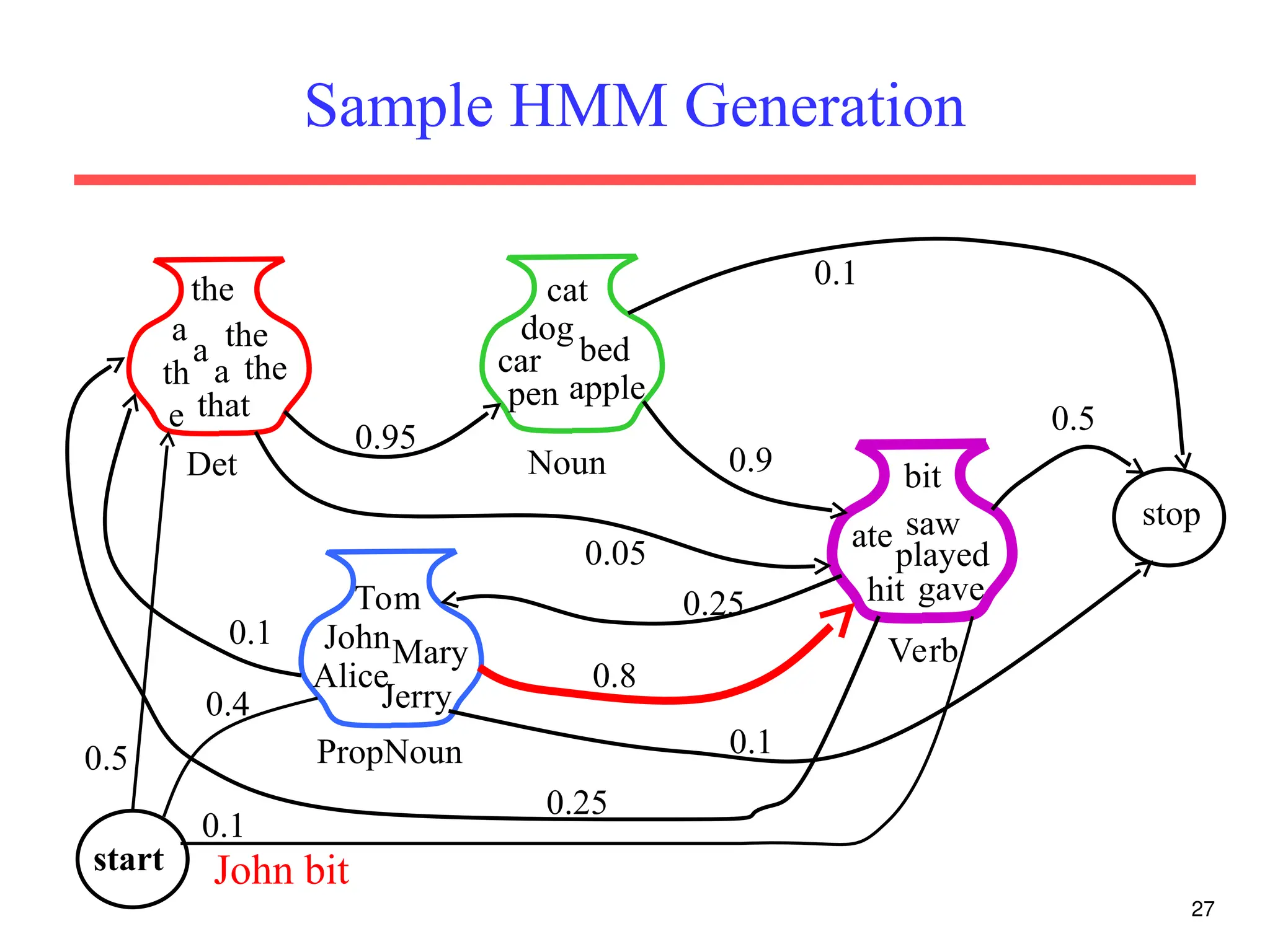
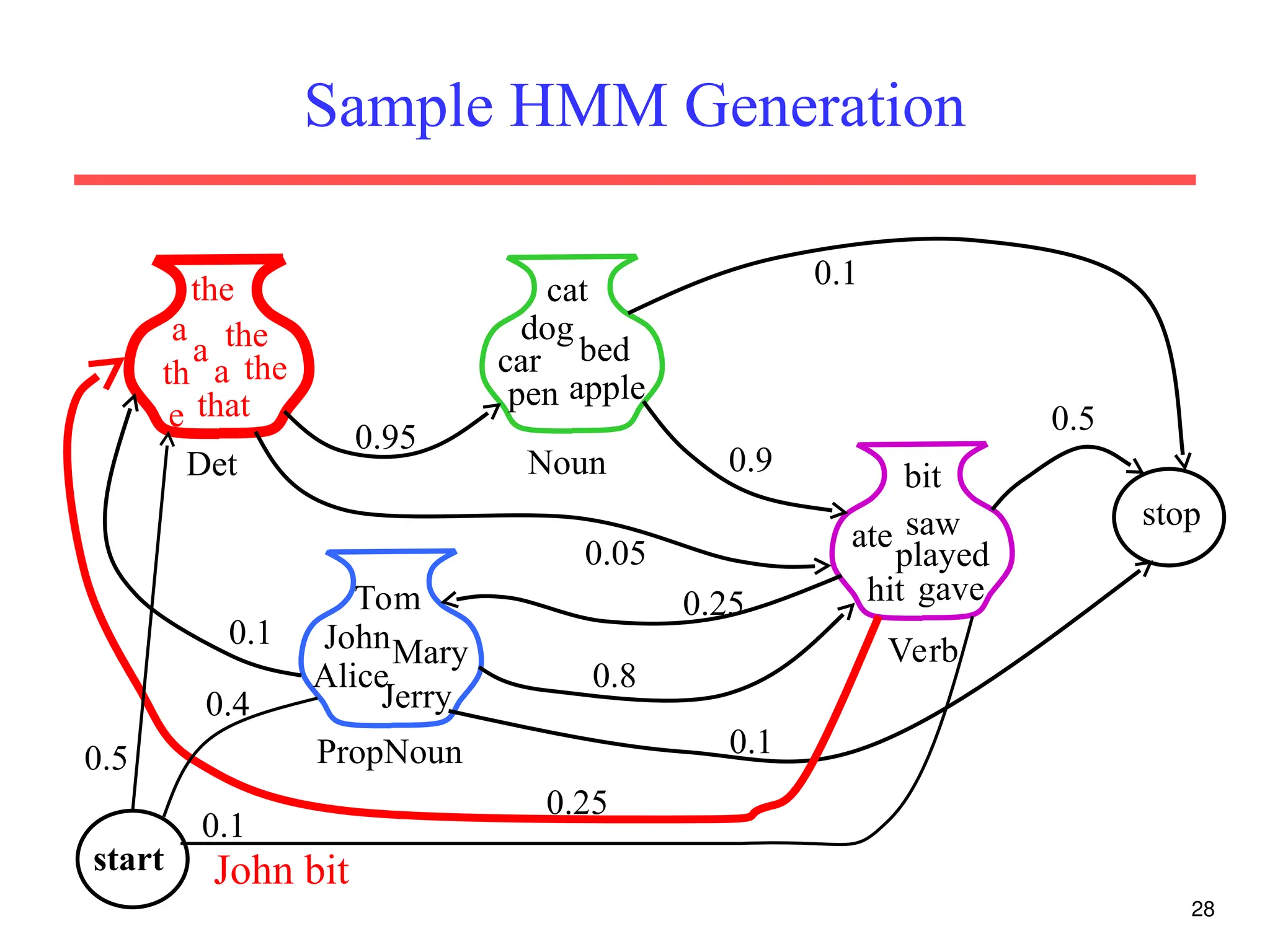
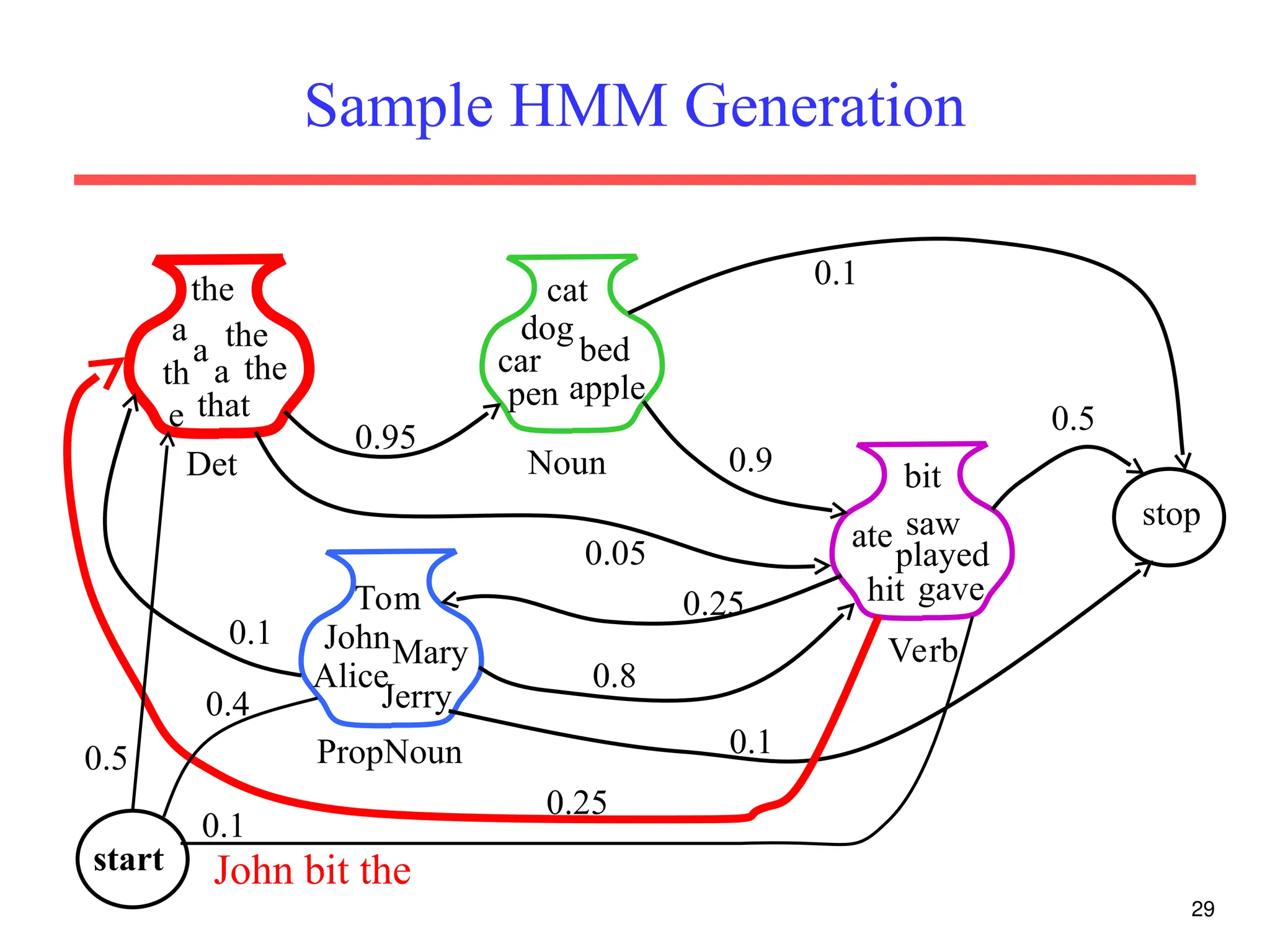
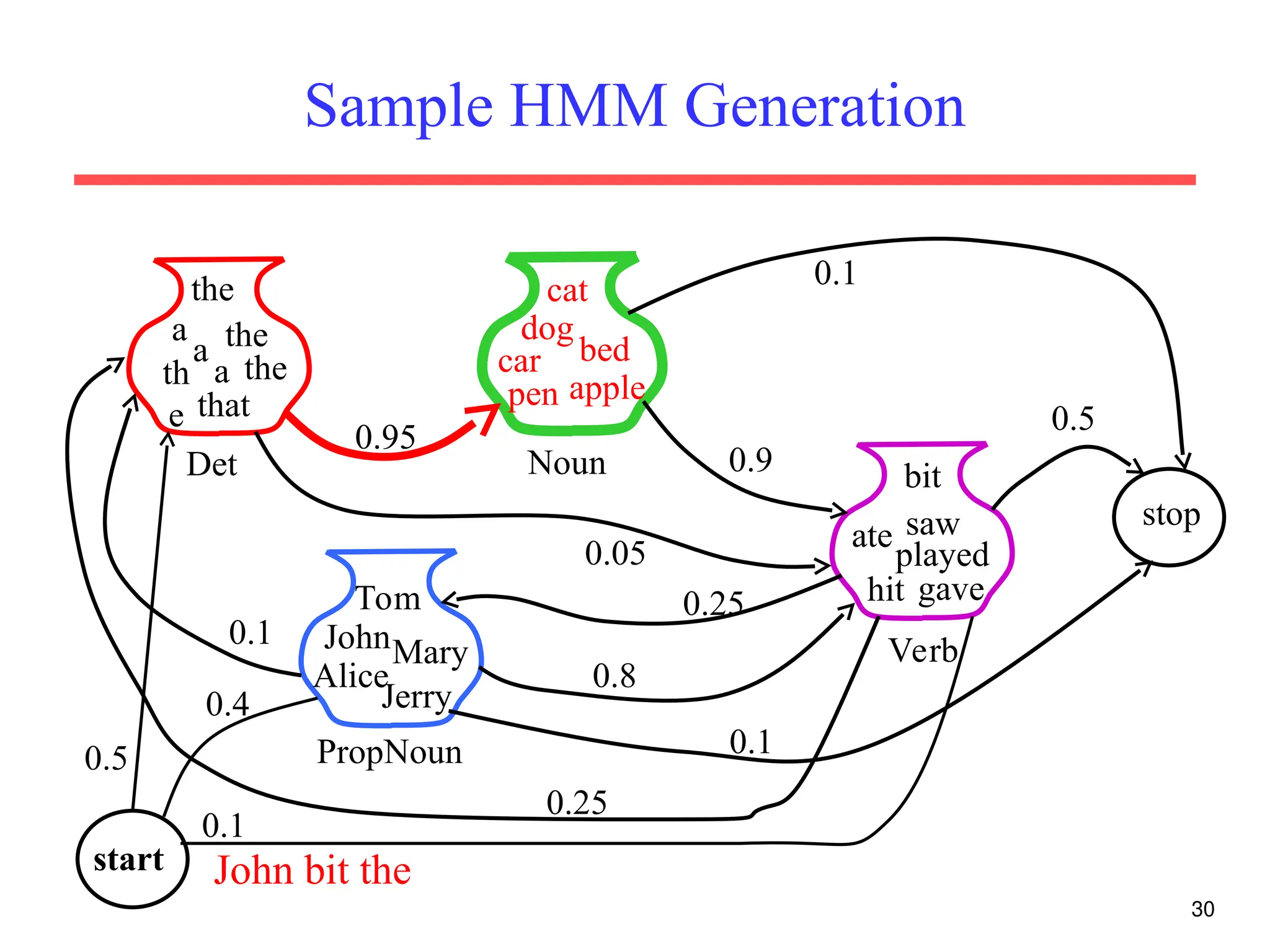
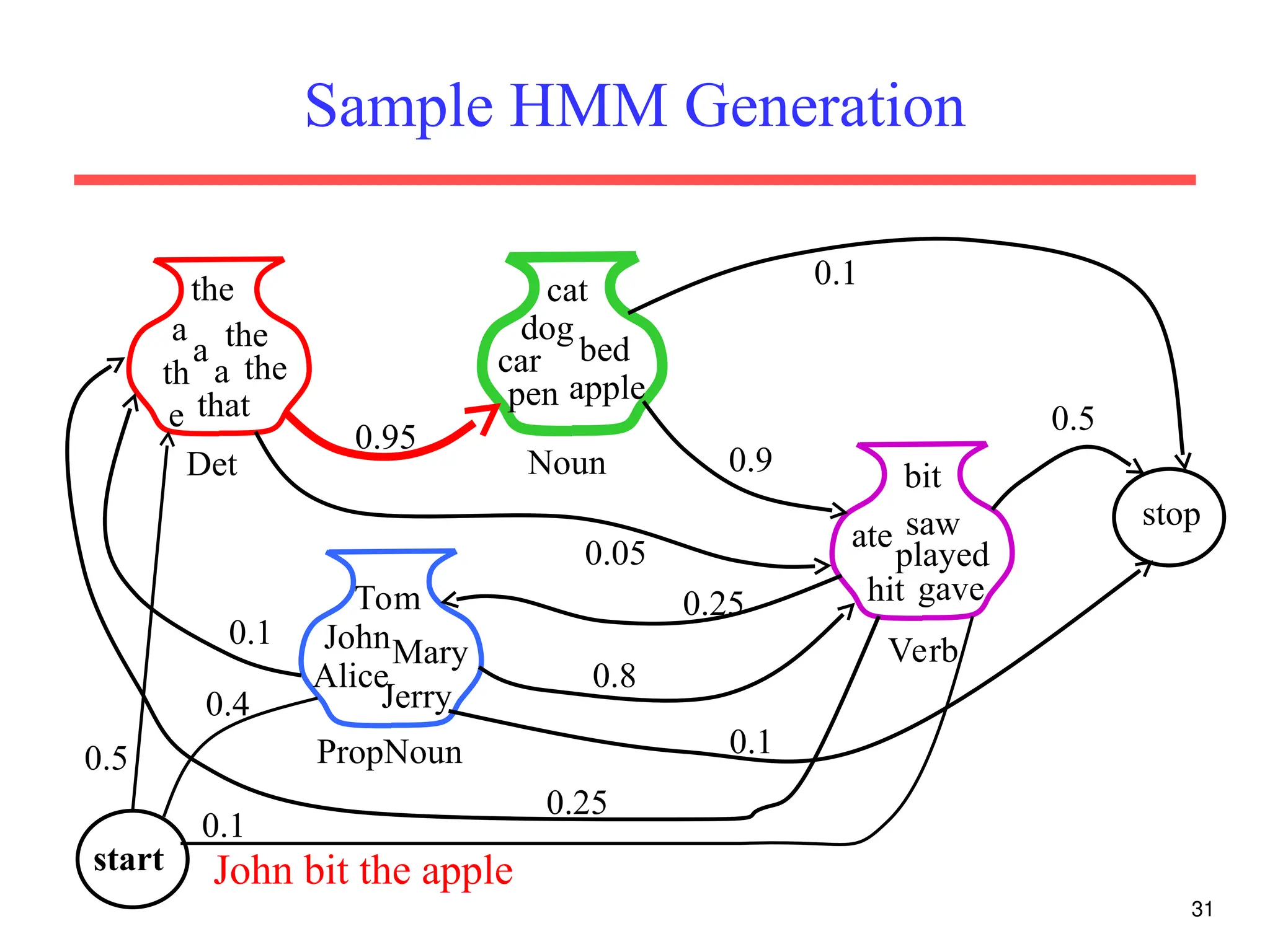
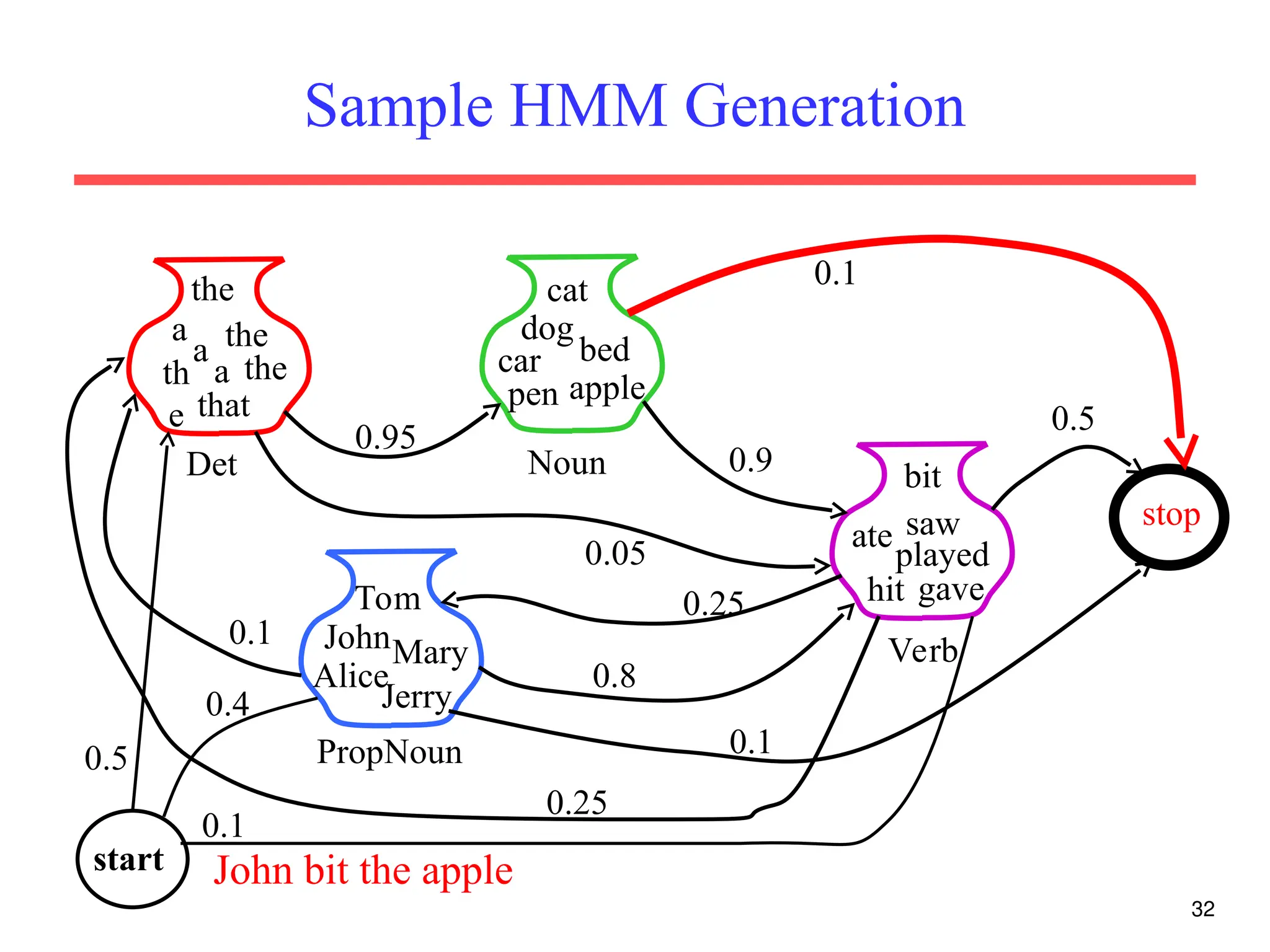
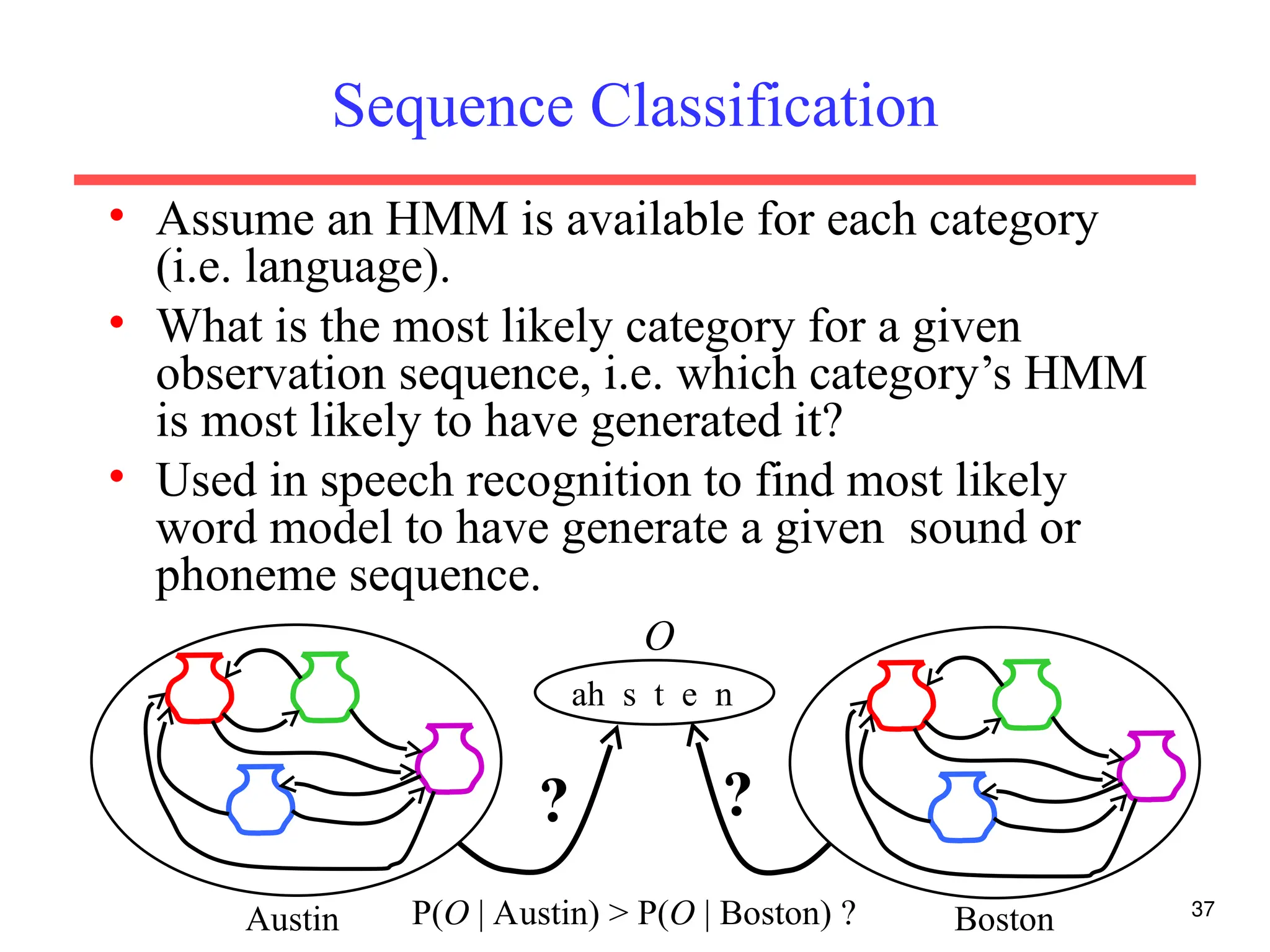
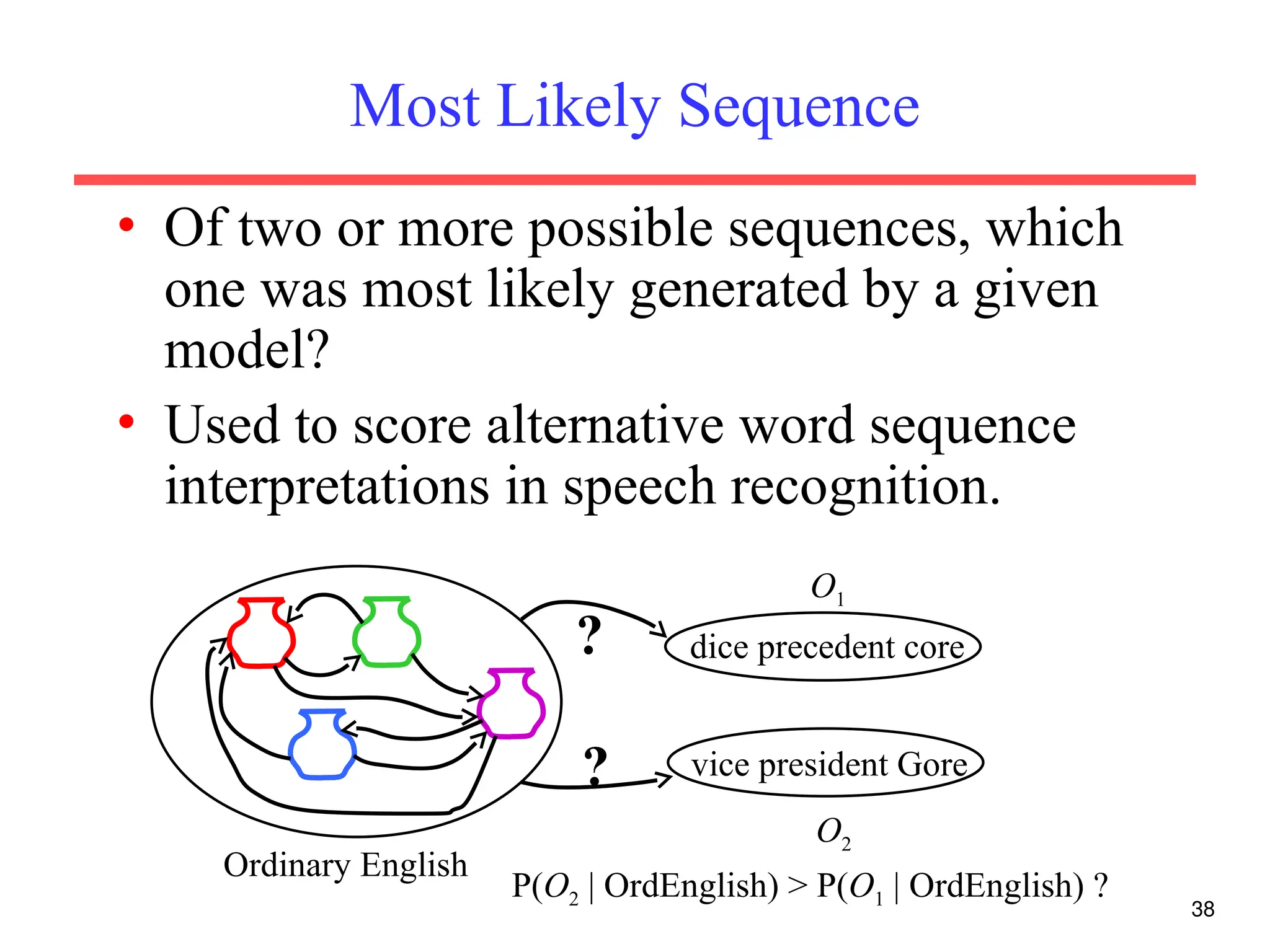
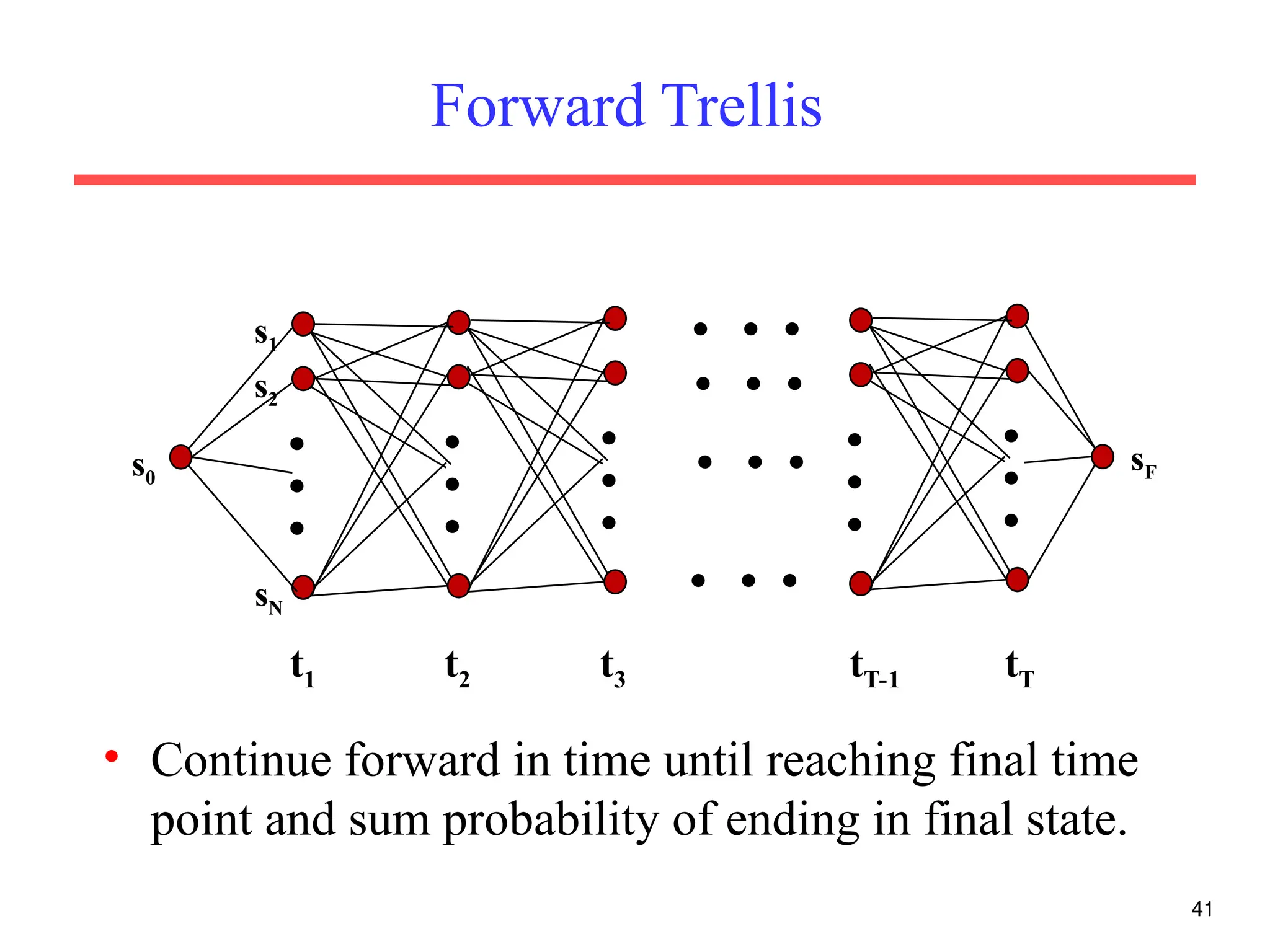
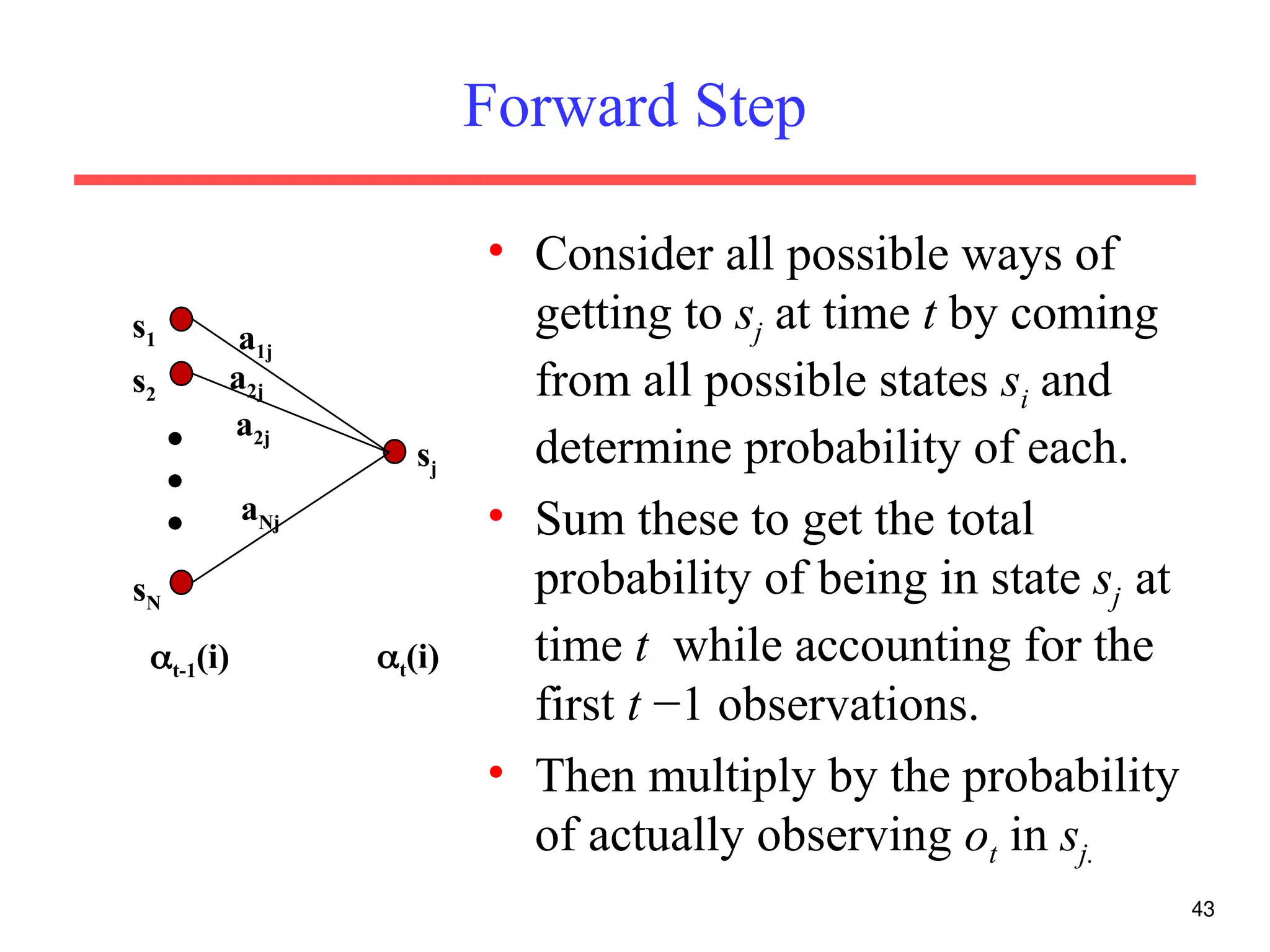
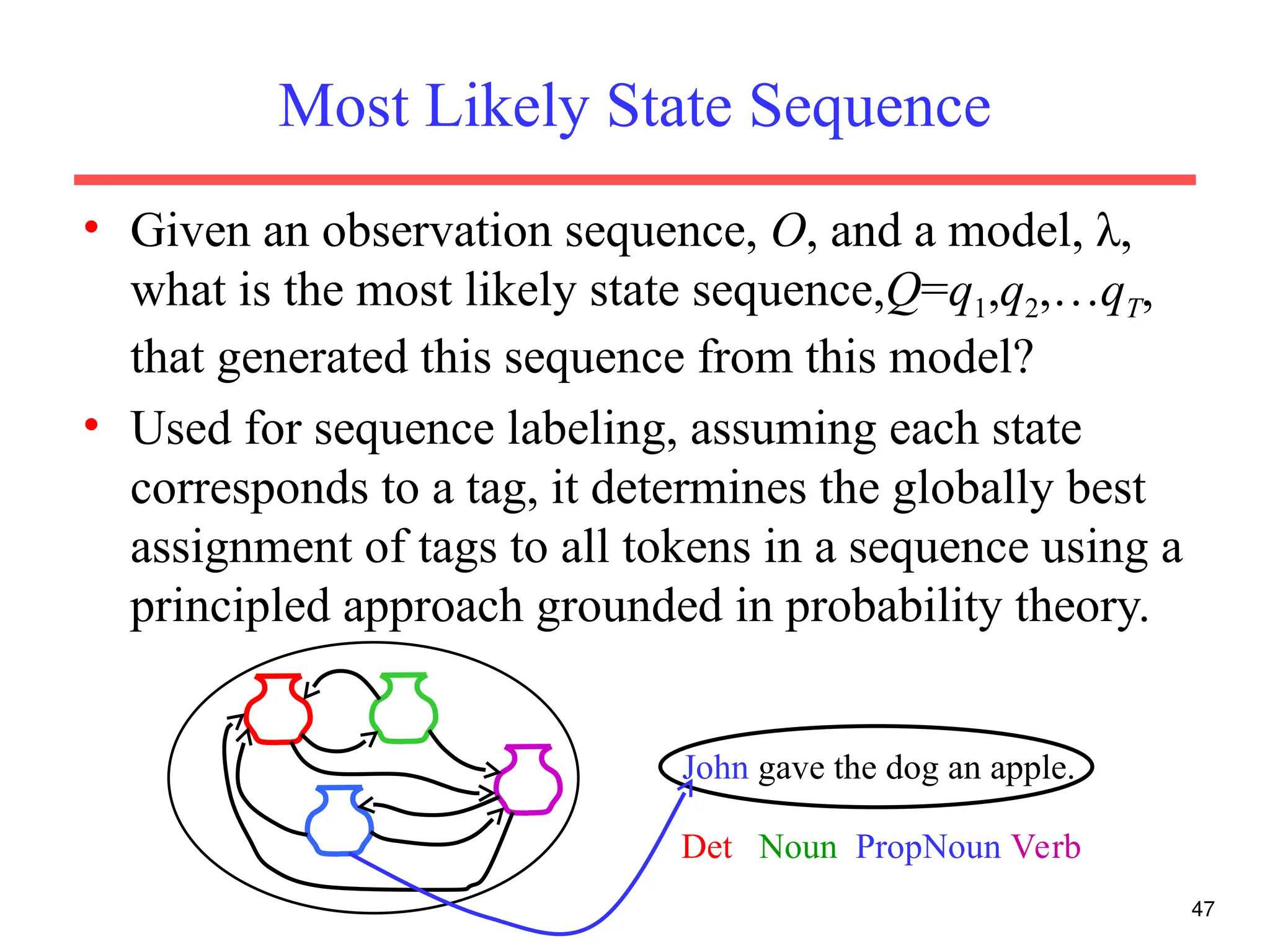
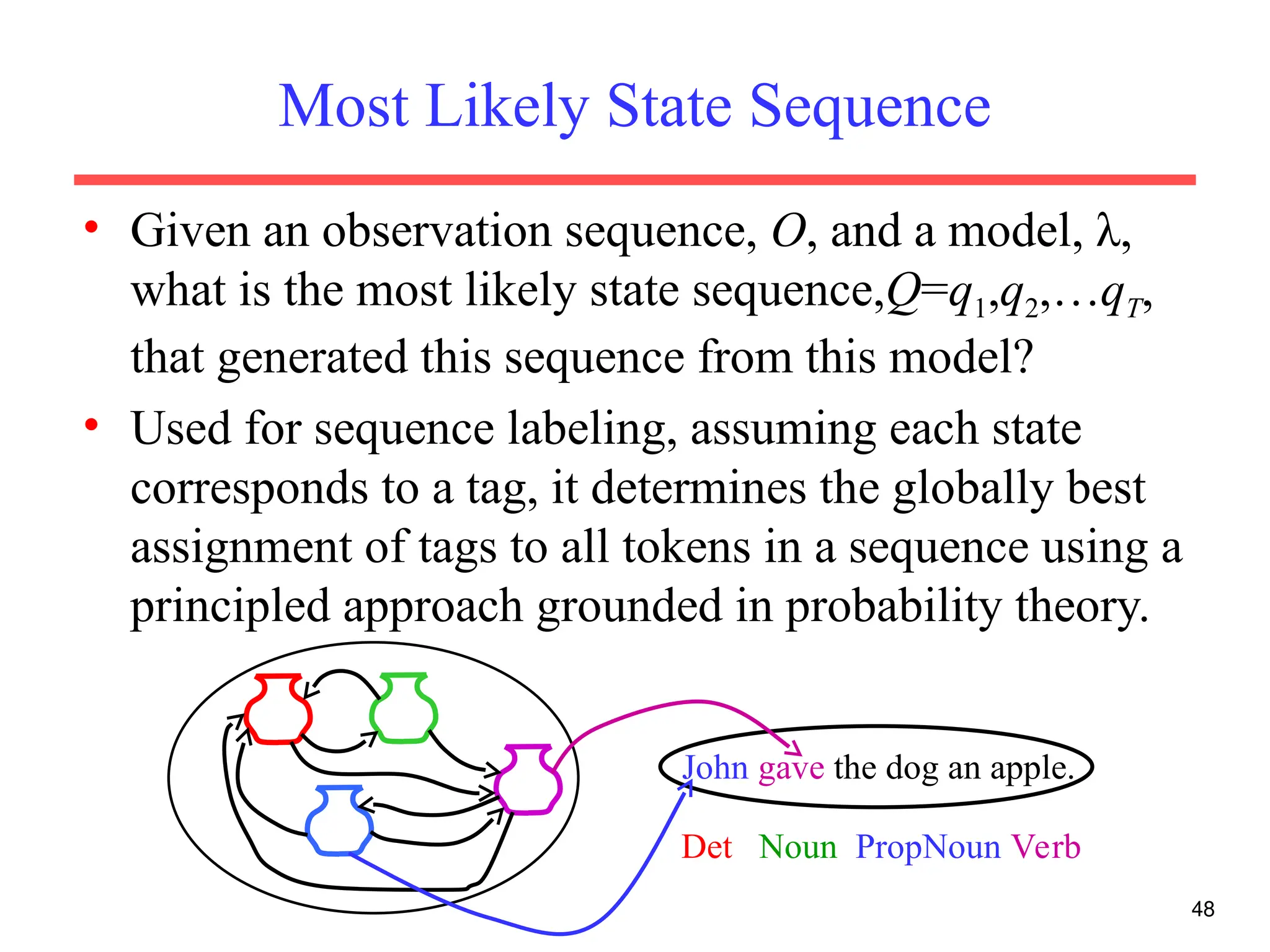
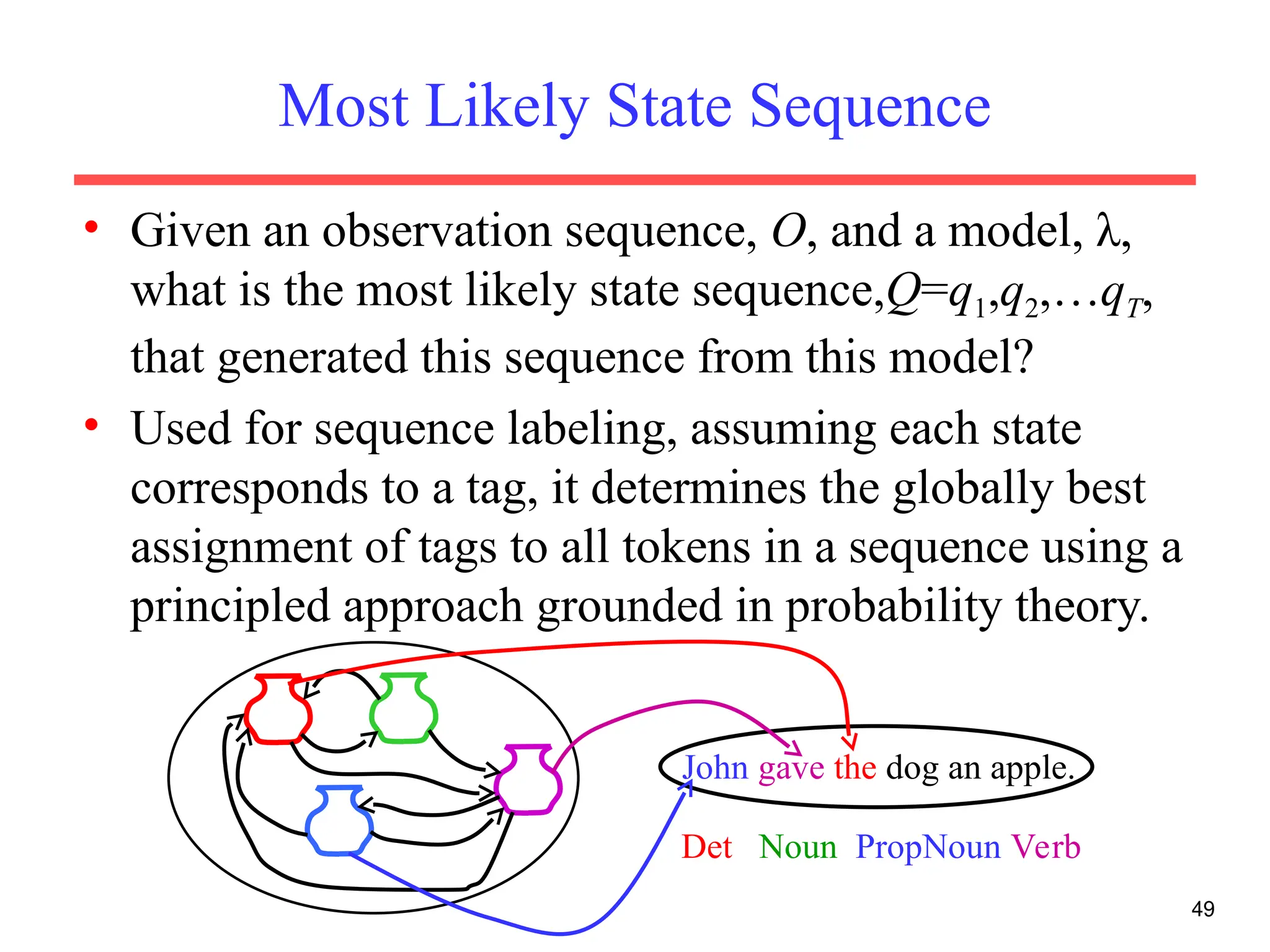
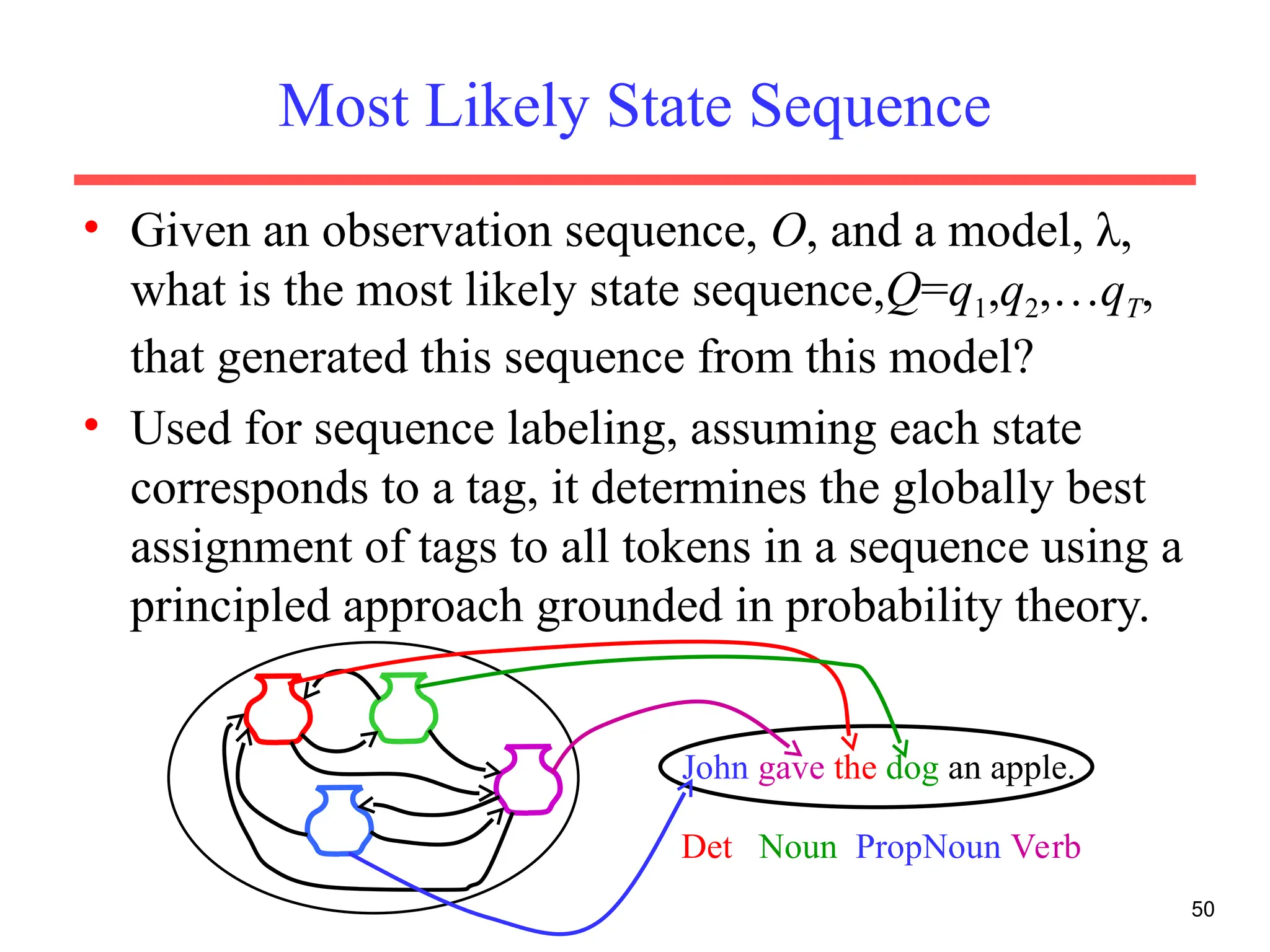
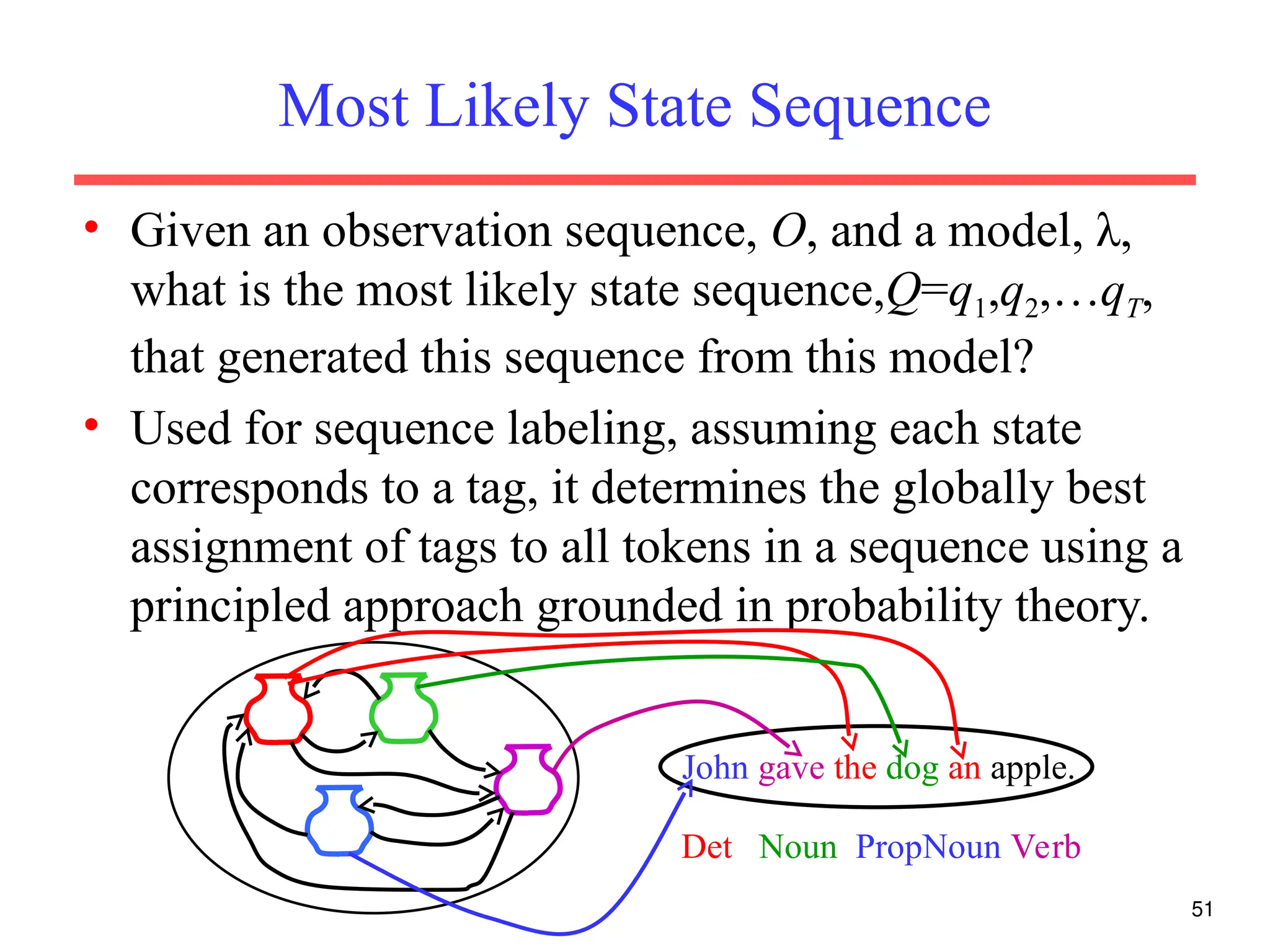
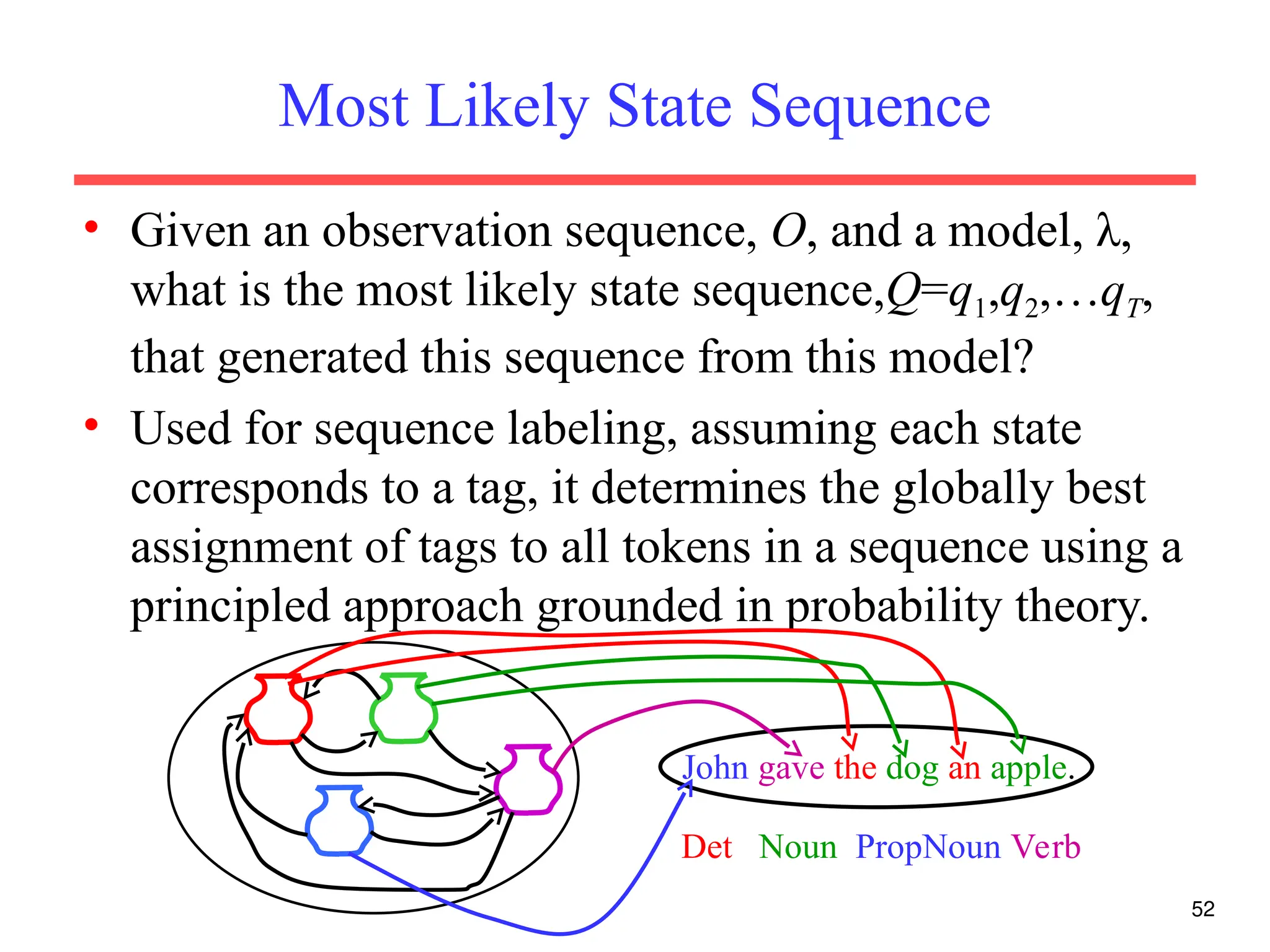
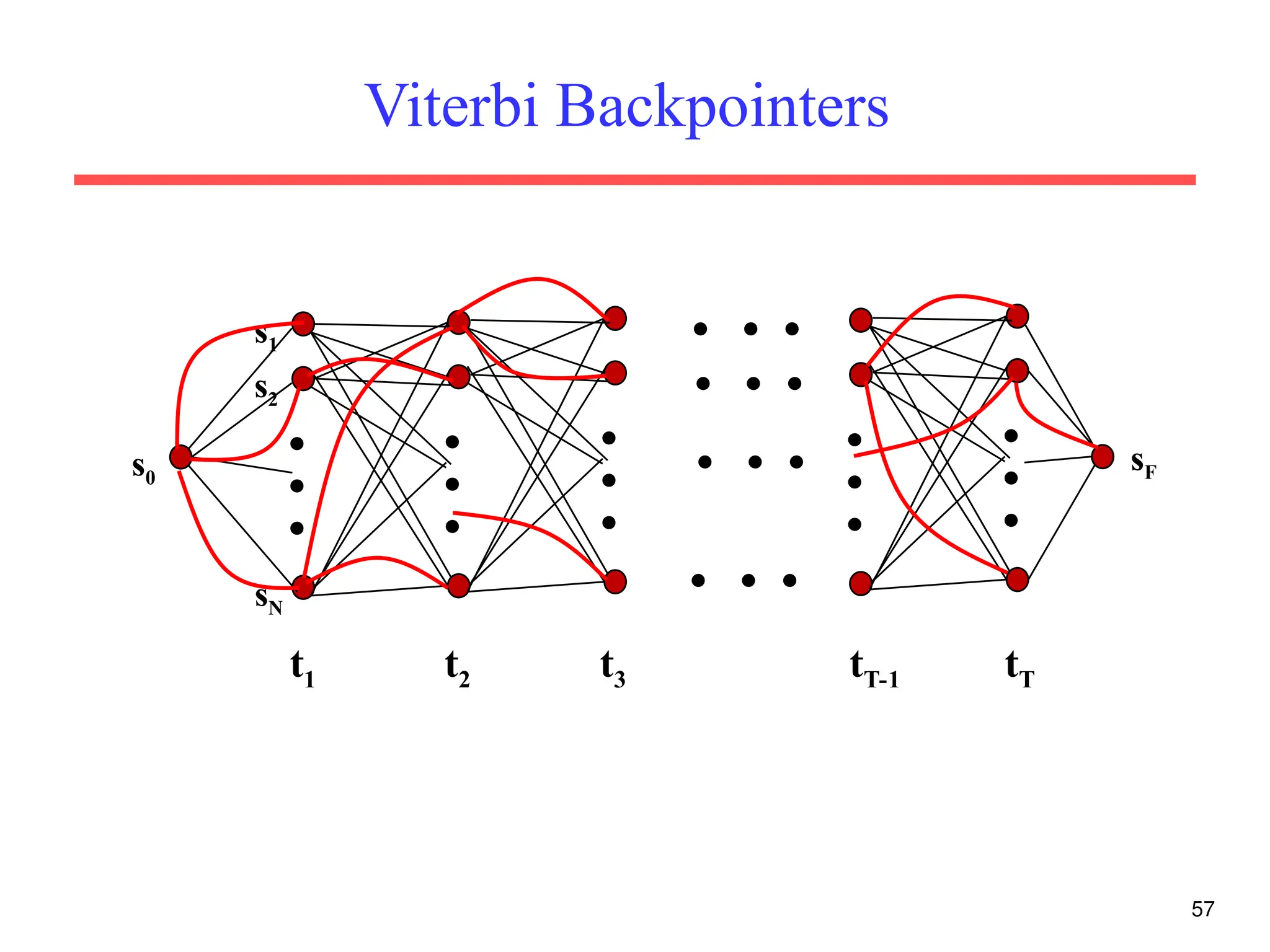
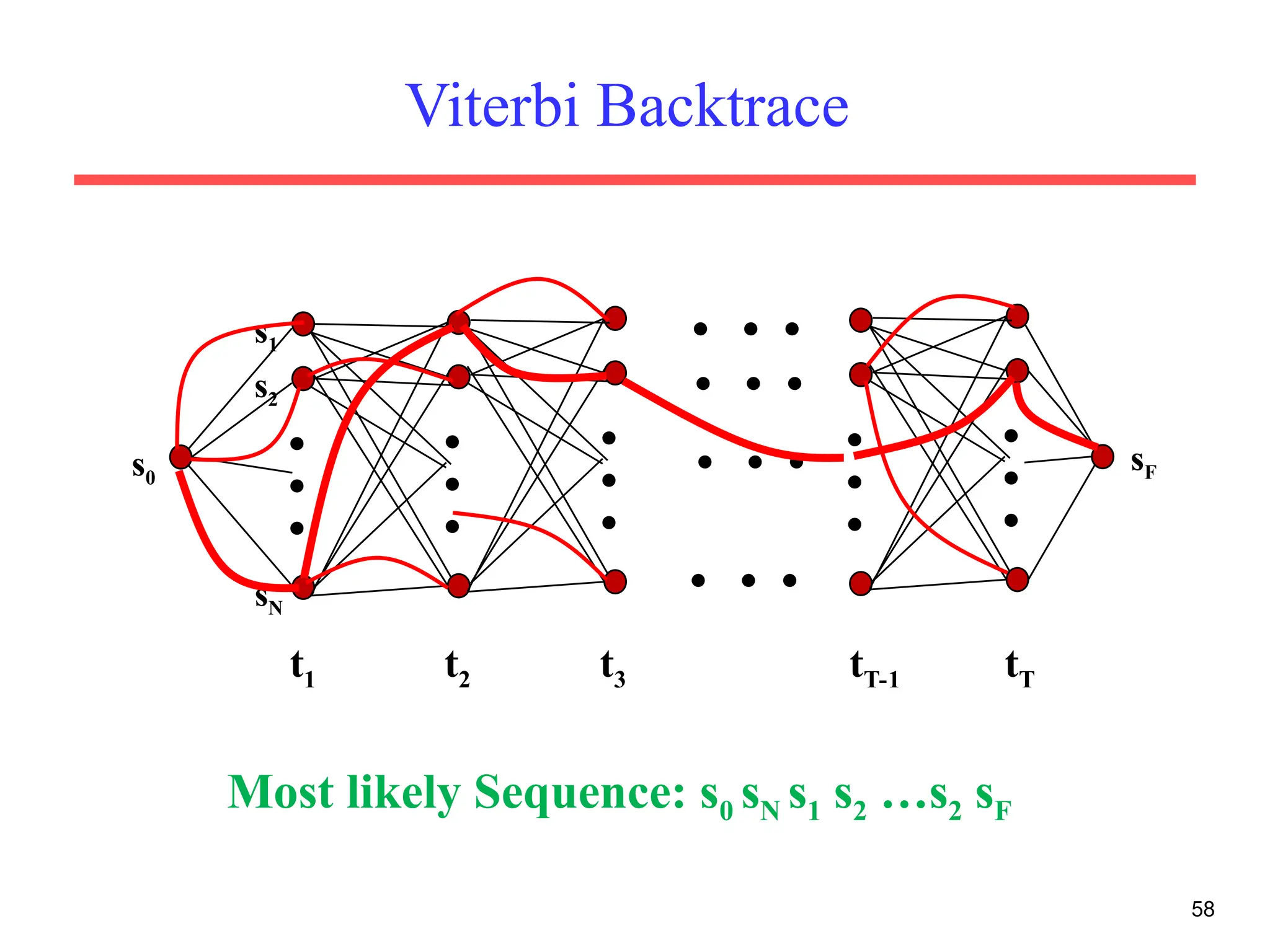
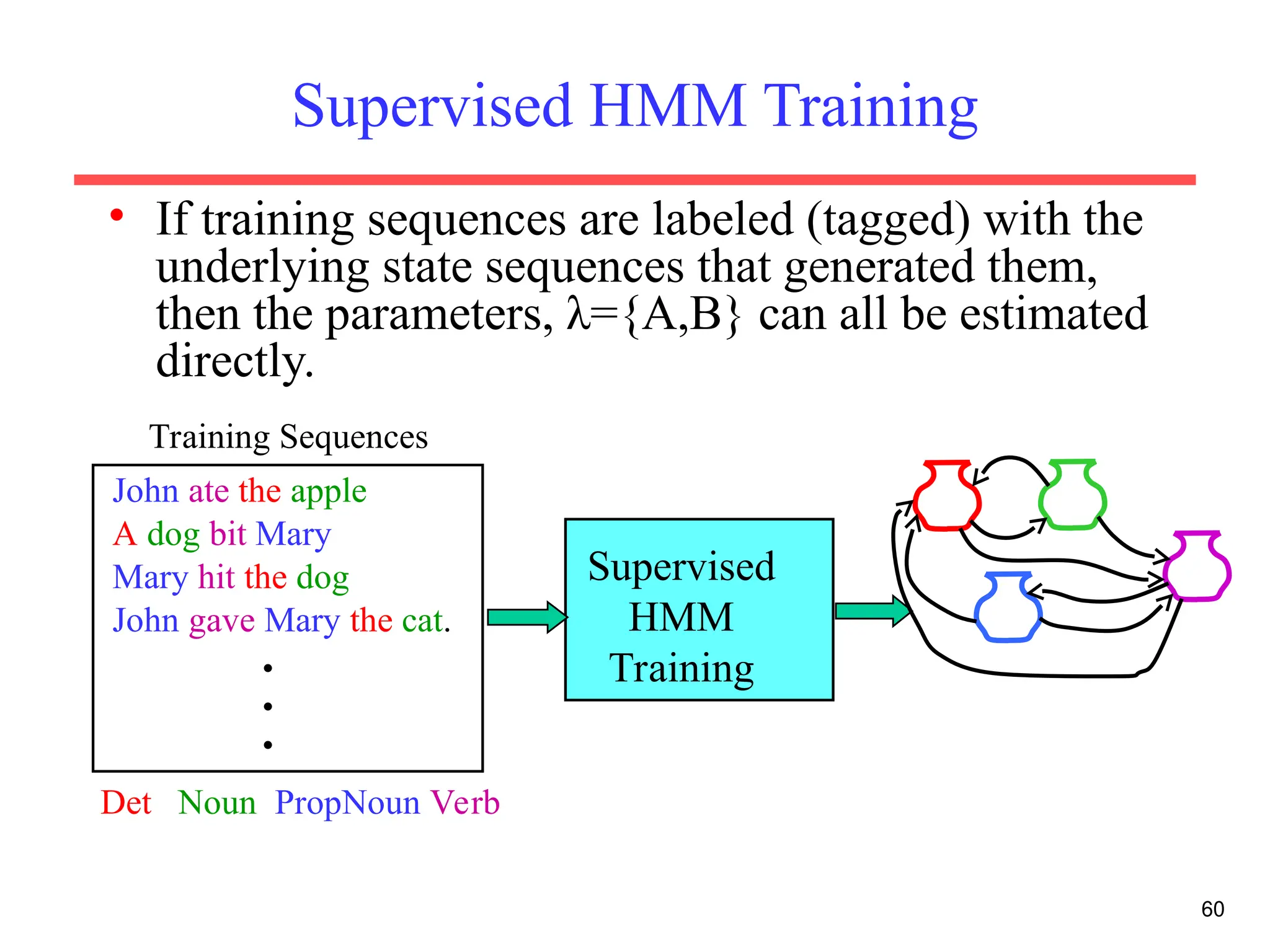
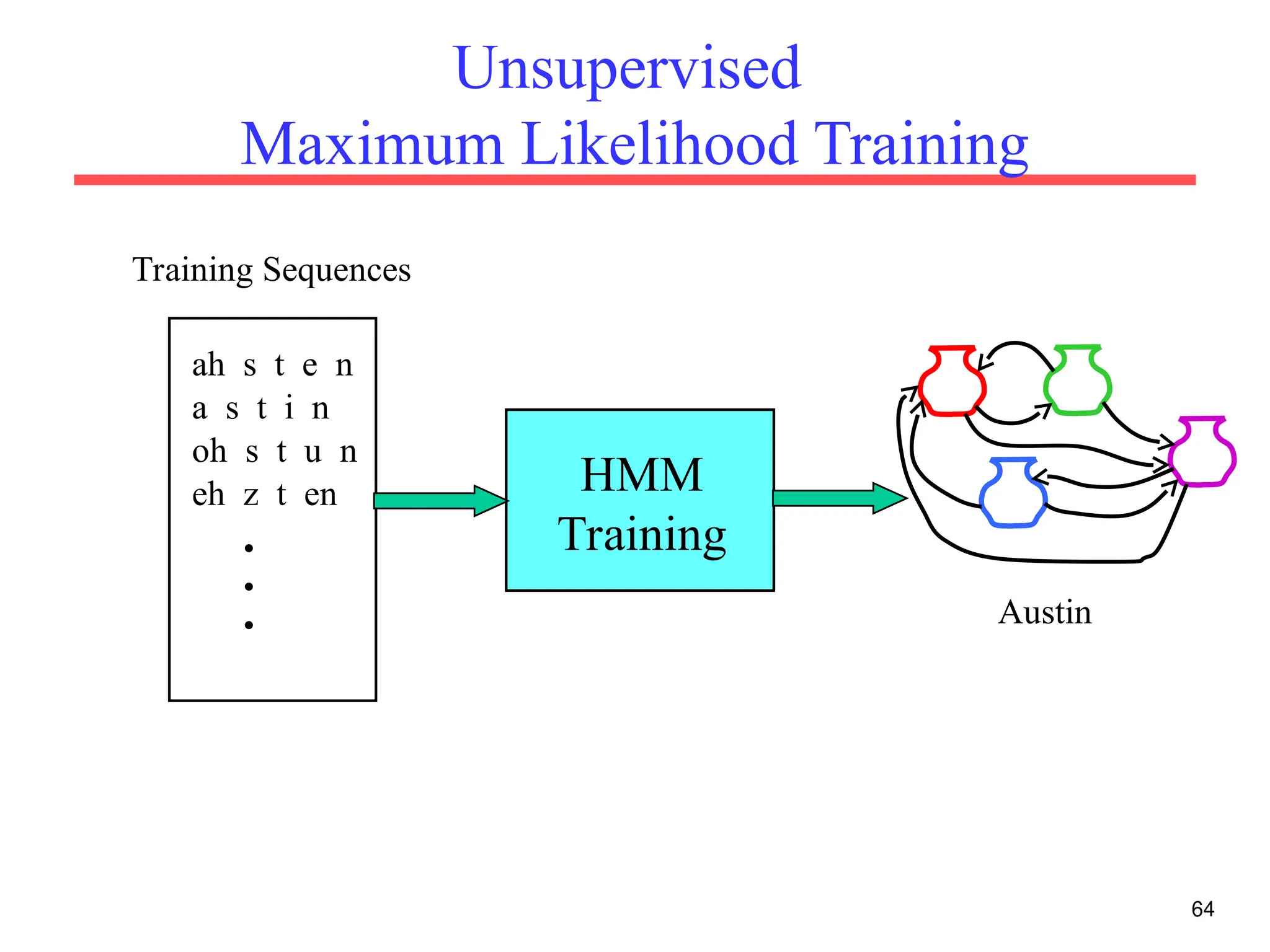
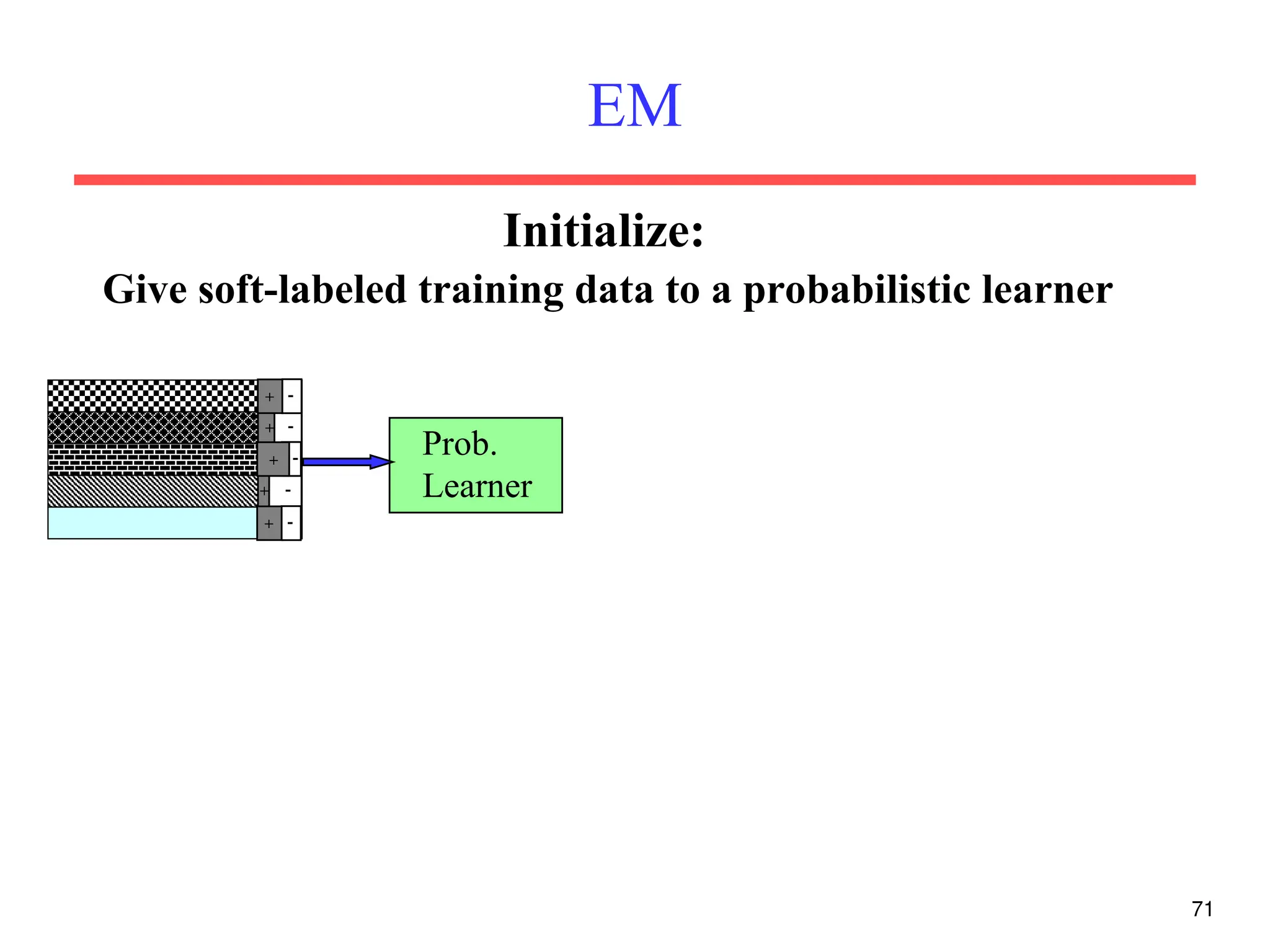
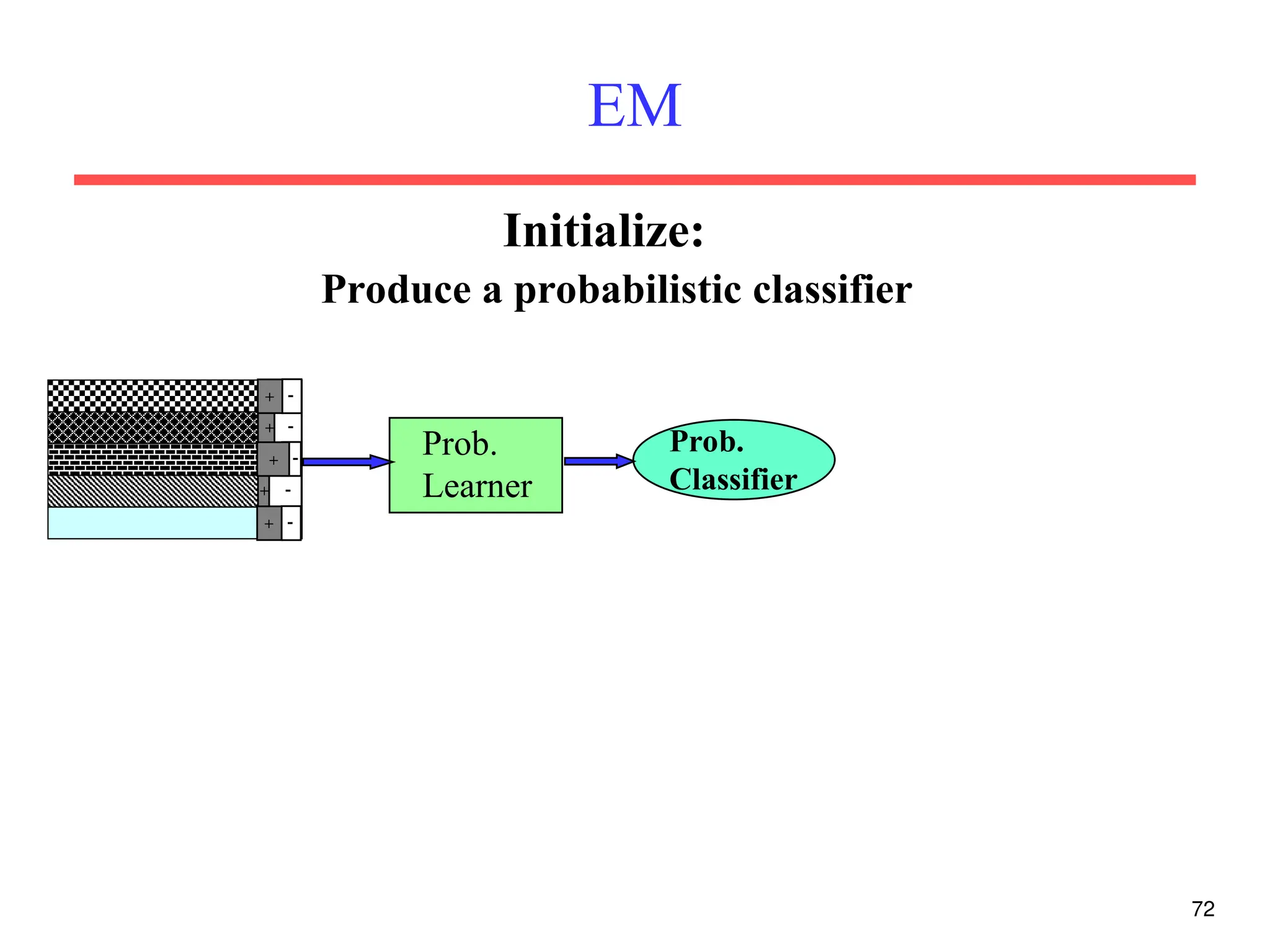
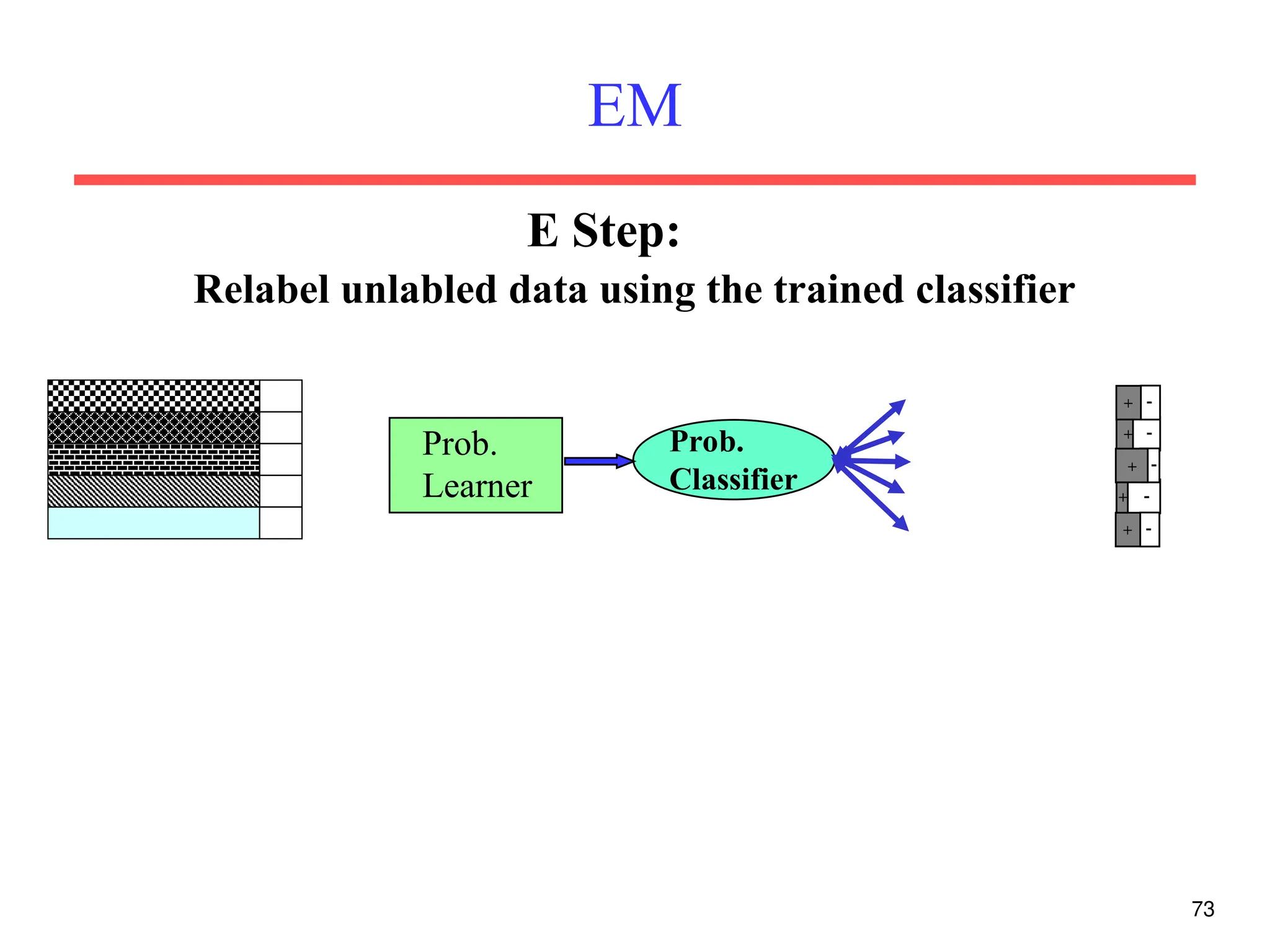
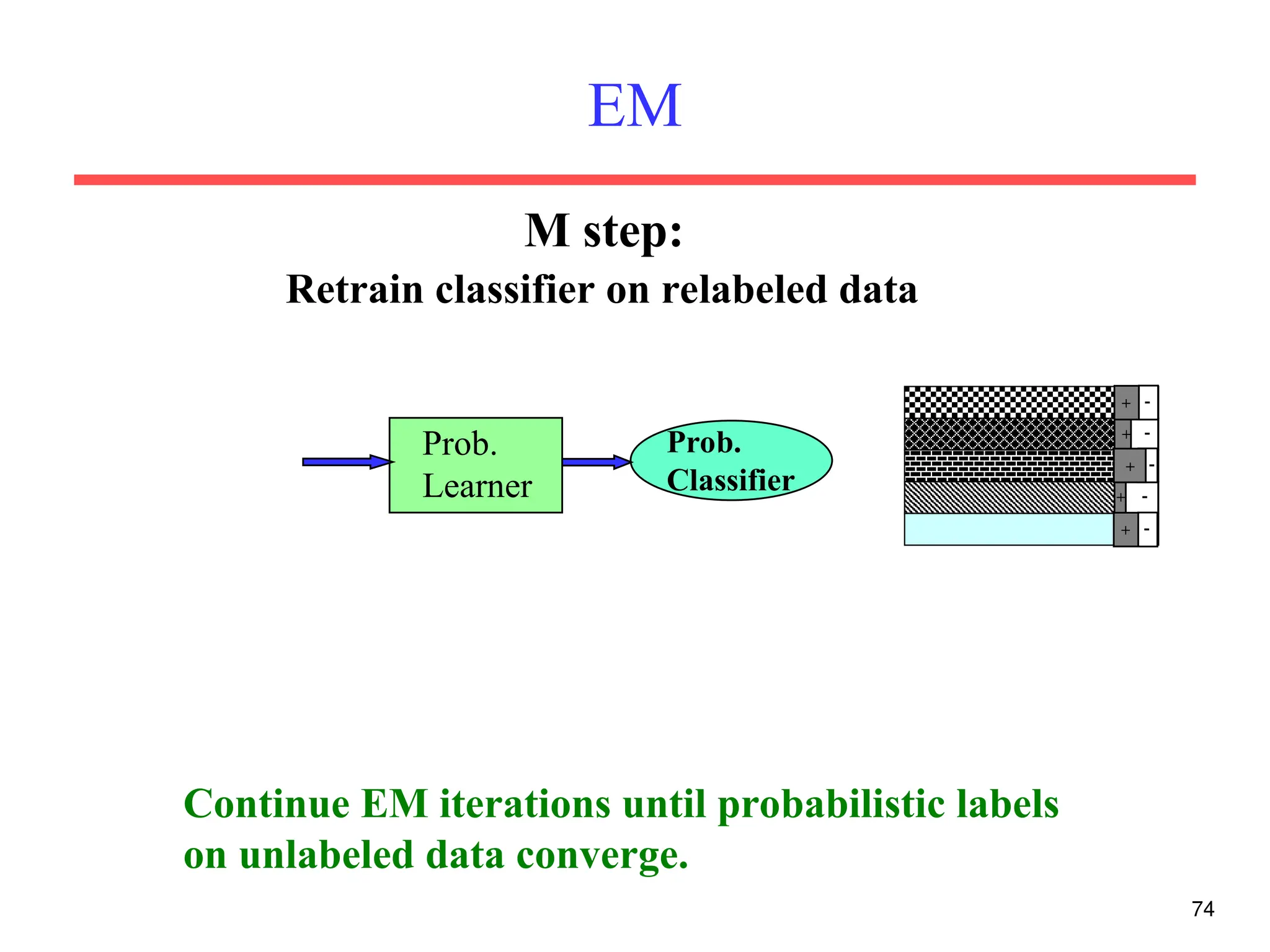
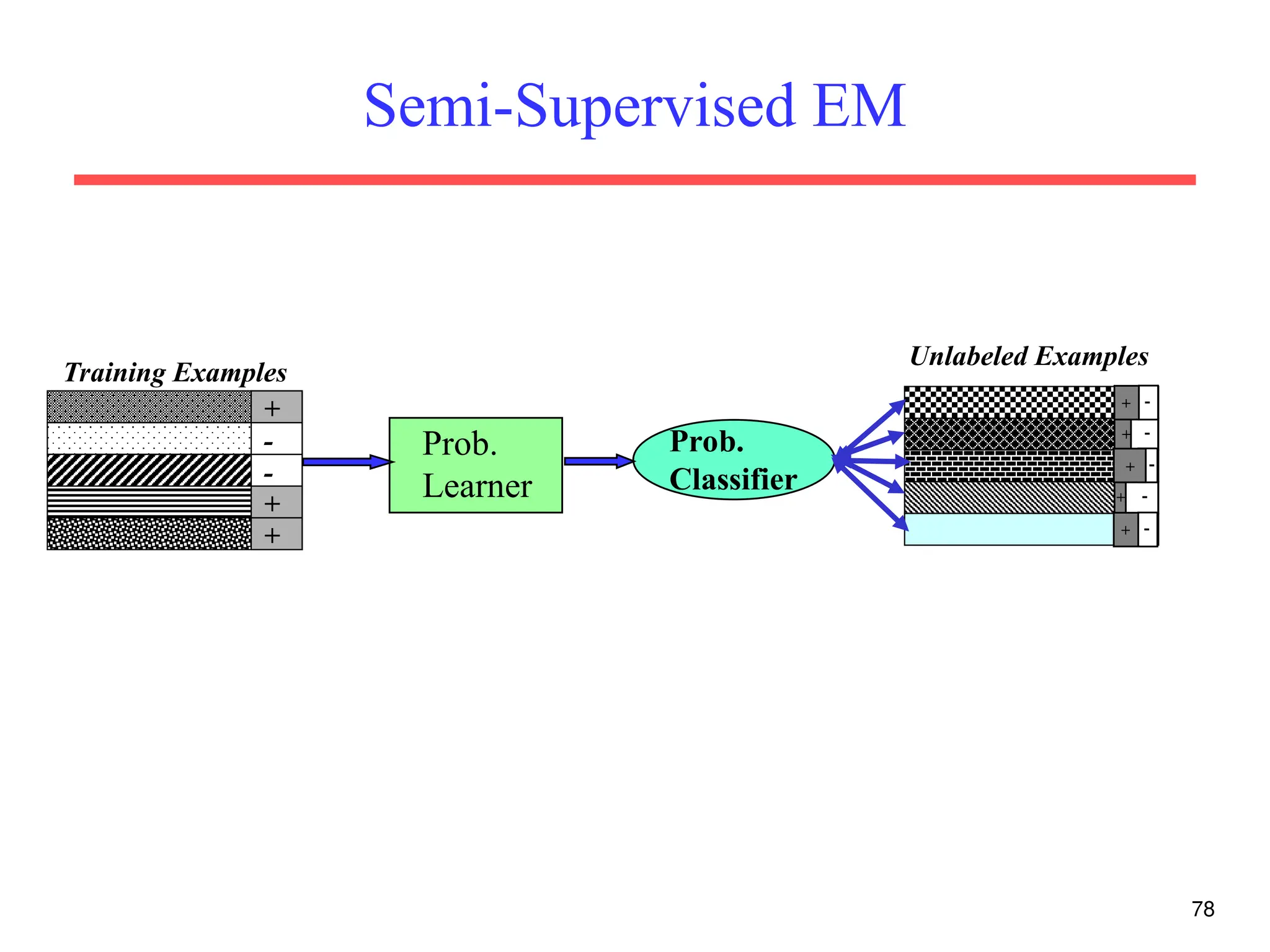
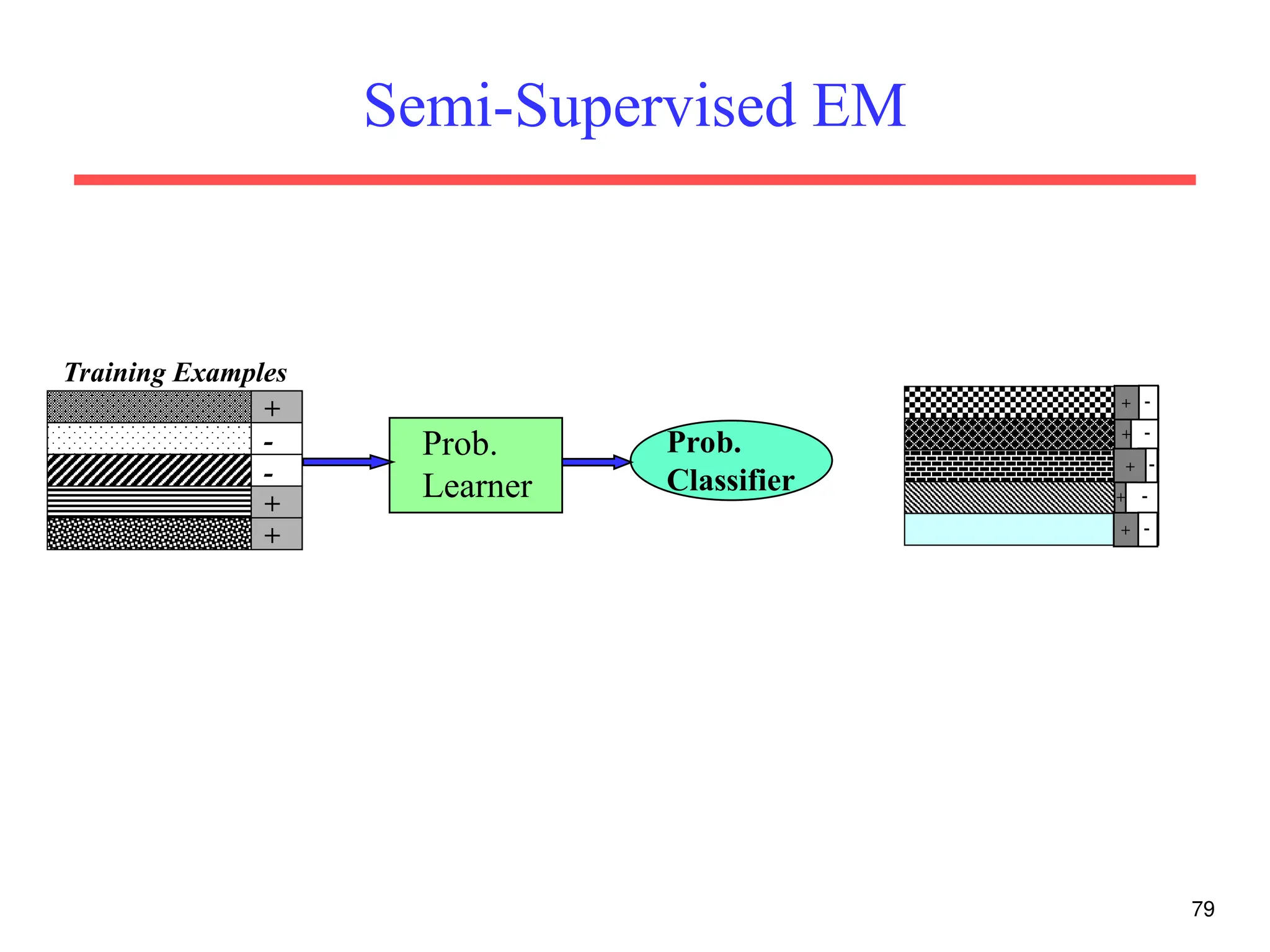
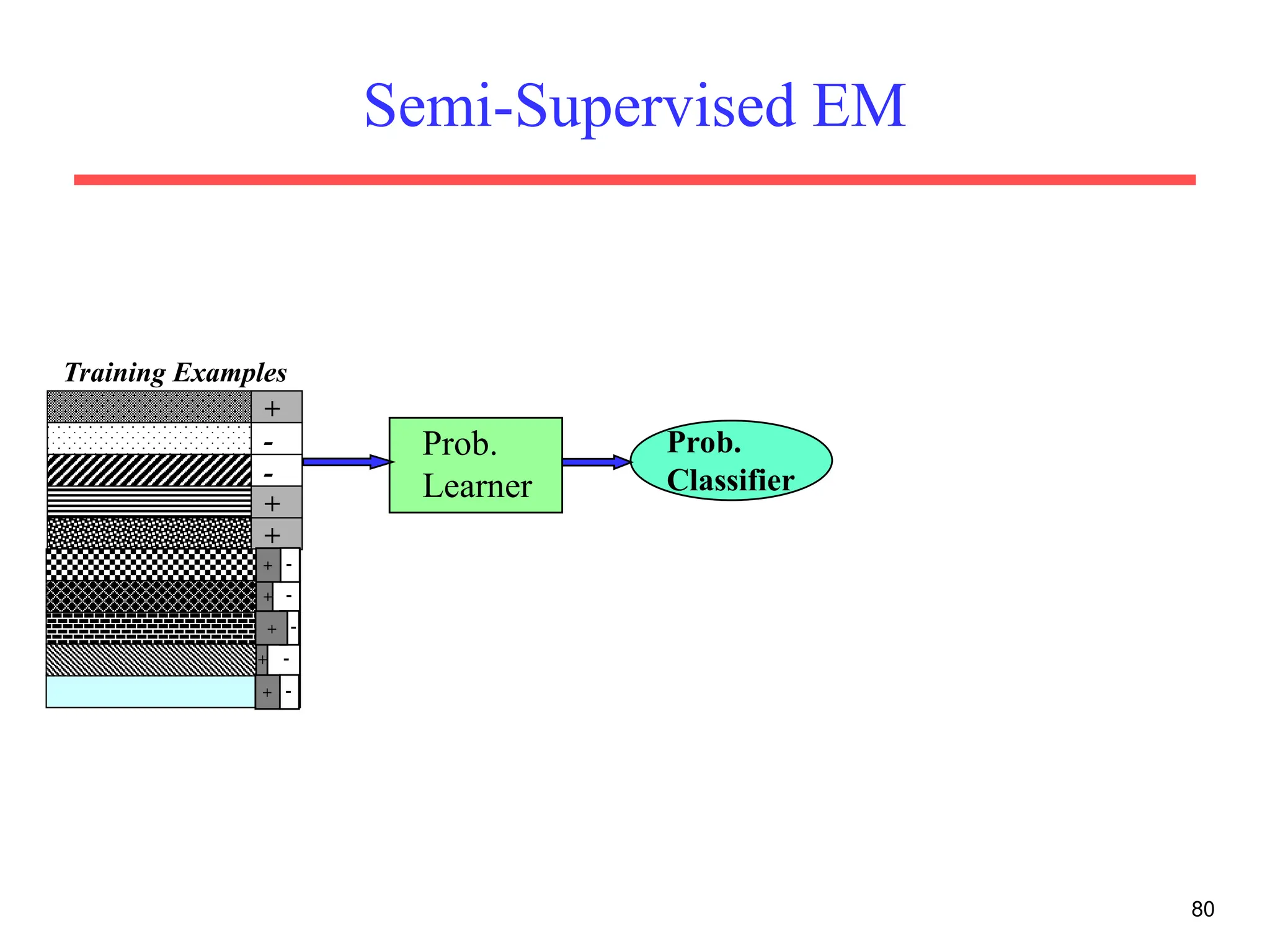
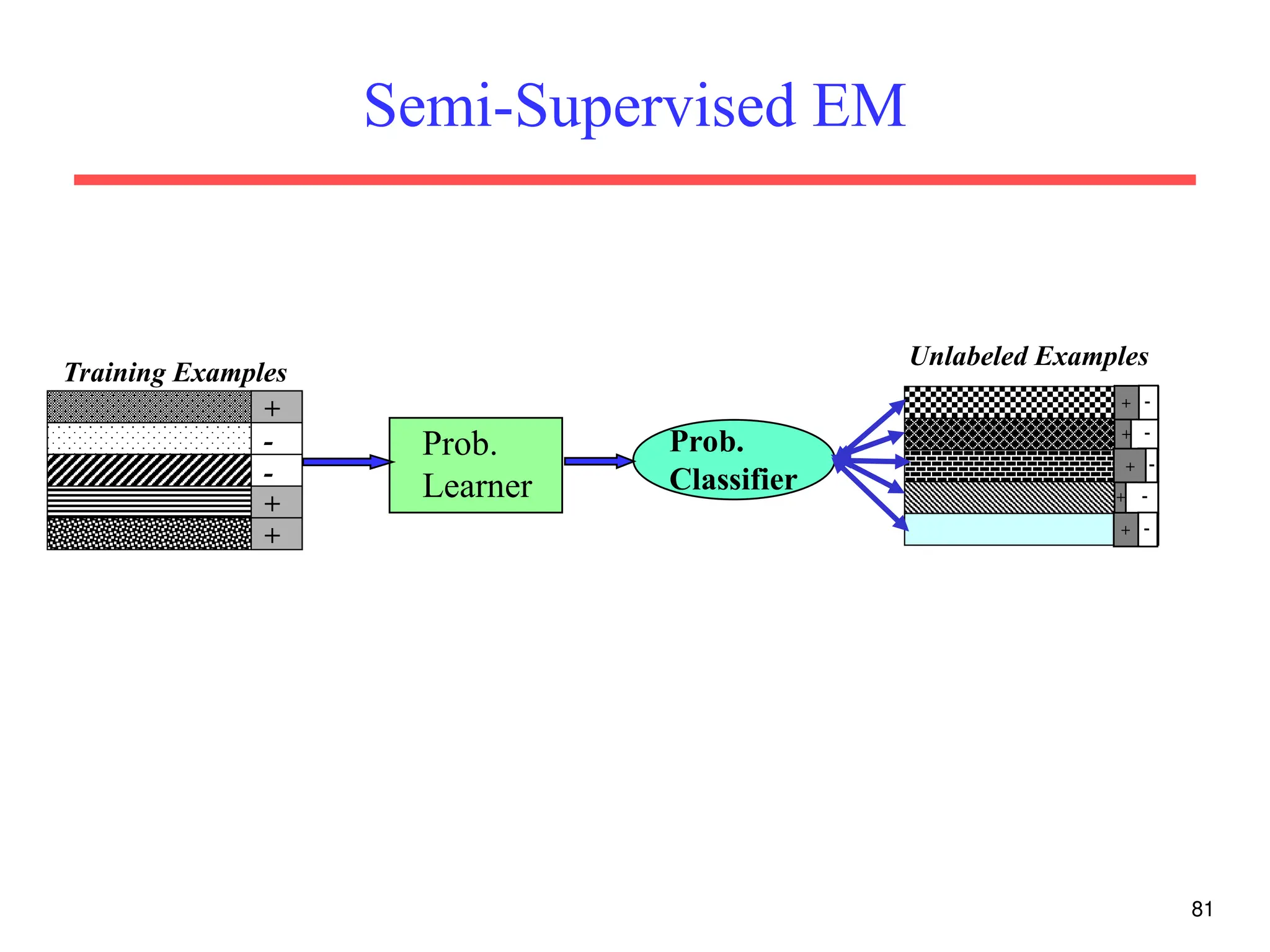
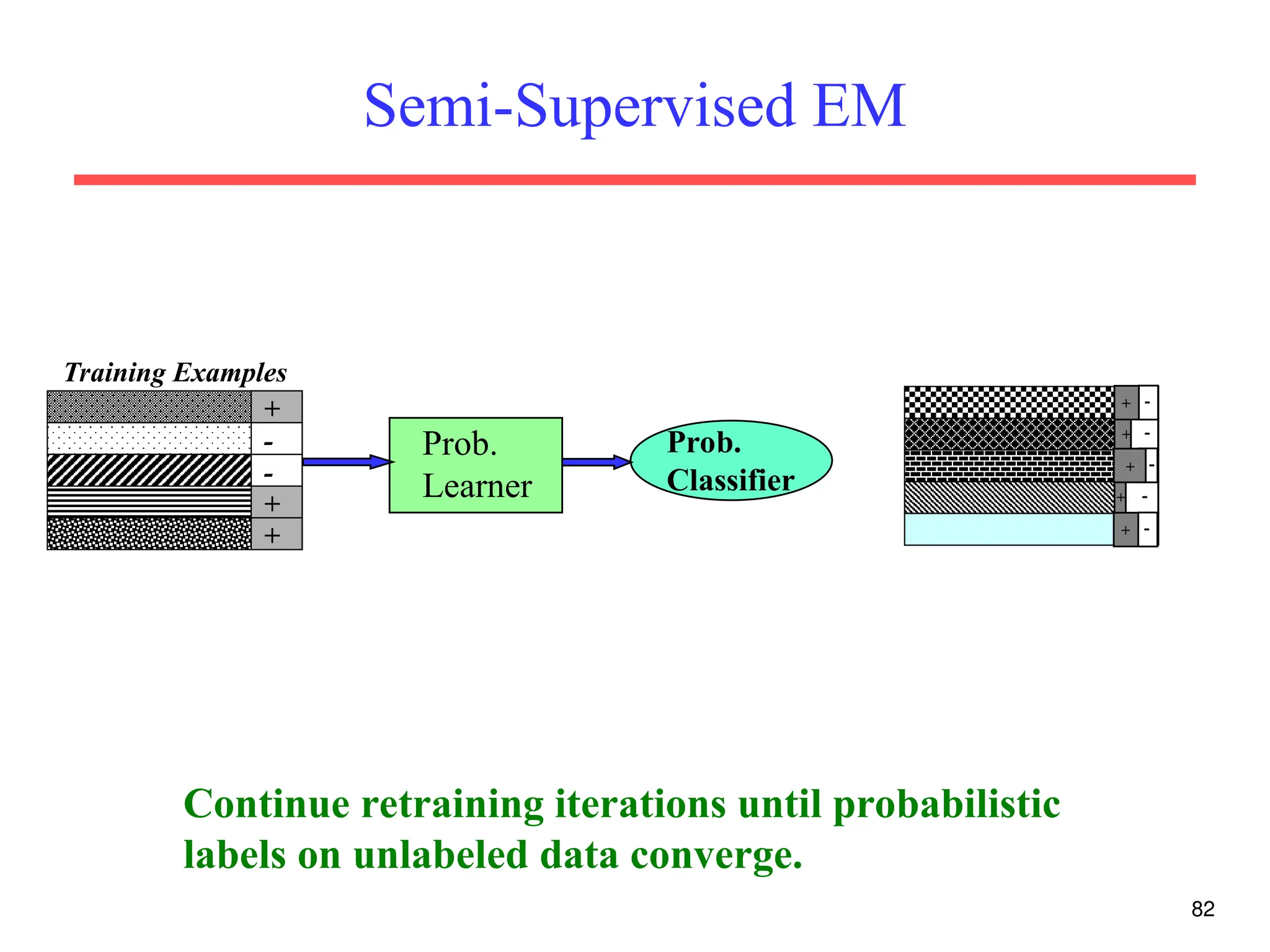
The document discusses part-of-speech (POS) tagging, a fundamental natural language processing (NLP) task that involves annotating words in sentences with their respective grammatical categories. It covers various types of English POS tags, tagging processes, and different approaches including rule-based and learning-based methods, highlighting the effectiveness of probabilistic models like Hidden Markov Models (HMMs) for sequence labeling tasks. Additionally, it explores challenges in POS tagging, ambiguity in language, and applications such as information extraction and semantic role labeling.