The document provides a comprehensive overview of vector databases, specifically focusing on Pinecone, a cloud-native vector database designed for managing vector embeddings essential for AI applications. It discusses key features such as creating and managing projects, indexes, and records, as well as operations like inserting, updating, querying, and backing up data. The document also highlights the scalability, low latency performance, and the importance of vector embeddings in tasks involving large language models and semantic search.








![Record
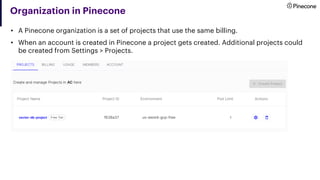
• A Pinecone Project can
contain many Indexes. Each
Index contains multiple
records.
• A record contains an
• ID,
• Values which is a vector
or array of float/
numbers
• Additional Metadata
(optional).
• As Pinecone is a NoSQL
vector database, defining
the schema is not reqd.
Organization
Project N
Project 2
Project 1
Index N
Index 1
1 [ 1.0,2.0, …. 10.0] {“key1”: “val1”, “key2”: “val2”}
2 [ 1.0,2.0, …. 10.0] {“key1”: “val1”, “key2”: “val2”}
N [ 1.0,2.0, …. 10.0] {“key1”: “val1”, “key2”: “val2”}
ID Values Metadata](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-10-320.jpg)

![Index – creating
• Distance metric could be of three type –
o Euclidean - This is used to calculate the distance between two data points in a plane. It is one of the most
commonly used distance metric.
o Cosine - This is often used to find similarities between different documents. This is the default value. The
advantage is that the scores are normalized to [-1,1] range.
o Dotproduct - This is used to multiply two vectors. You can use it to tell us how similar the two vectors are. The
more positive the answer is, the closer the two vectors are in terms of their directions.
• Distance metric could be of three type – No of pods and pod type also could be specified –
pinecone.create_index(name="third-index", dimension=10, metric="cosine", shards=3,
pods=5, pod_type="p2")](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-12-320.jpg)
![Index – listing index, getting details and deleting
• List Pinecone indexes
pinecone.list_indexes()
['first-index’]
• Get details of an index
pinecone.describe_index("second-index")
IndexDescription(name='second-index', metric='cosine', replicas=1, dimension=5.0,
shards=1, pods=1, pod_type='starter', status={'ready': True, 'state': 'Ready'},
metadata_config=None, source_collection=‘’)
• Delete an index
pinecone.delete_index("first-index")](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-13-320.jpg)

![Insert data
• To insert, update, delete or perform any operation, Get a reference to the index created before -
index = pinecone.Index("second-index")
• Insert a single record by using the upsert method. The record contain Id, vector embeddings and
optional metadata -
index.upsert([("hello world", [1.0, 2.234, 3.34, 5.6, 7.8])])
• Insert multiple records using the same operations passing all the records as array -
index.upsert(
[
("Bangalore", [1.0, 2.234, 3.34, 5.6, 7.8]),
("Kolkata", [2.0, 1.234, 3.34, 5.6, 7.8]),
("Chennai", [3.0, 5.234, 3.34, 5.6, 7.8]),
("Mumbai", [4.0, 6.234, 3.34, 5.6, 7.8])
])
• Insert records (multiple) with metadata
index.upsert(
[
("Delhi", [1.0, 2.234, 3.34, 5.6, 7.8], {"type": "city", "sub-type": "metro"}),
("Pune", [2.0, 1.234, 3.34, 5.6, 7.8], {"type": "city", "sub-type": "non-metro"})
])](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-15-320.jpg)
![Update data – partial and full update
• Pinecone supports Full update and partial update of records.
• Full Update allows updating both vector values and metadata, while partial update allowing either
vector values or metadata
• To insert, update, delete or perform any operation, Get a reference to the index created before -
index = pinecone.Index("second-index")
• To partially update the record, use the update method
Following code update the vector values of the record -
index.update(id="hello world", values=[2.0, 3.1, 6.4, 9.6, 11.8])
Following code update the metadata the record -
index.update(id="hello-world", metadata={"city1":"Blore", "city2":"Kolkata"})
• To fully update the record use the same upsert method used earlier to insert the data -
index.upsert([("hello-world", [10.0, 20.1, 31.4, 55.6, 75.8], {"city1":"Blore",
"city2":"Kolkata", "city3":"Delhi"})])](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-16-320.jpg)
![Backup data using Collection
• Collections are used to backup an Index. A collection is a static copy of your index that only
consumes storage
• Create a collection by specifying name of the collection and the name of the index -
pinecone.create_collection(name="bakcup_collection", source=“first-index")
pinecone.list_collections()
['bakcup-collection’]
pinecone.describe_collection("bakcup-collection")](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-17-320.jpg)
![Collection – listing, get details and deleting
• All existing collections could be easily listed -
pinecone.list_collections()
['bakcup-collection’]
• All existing collections could be easily listed -
pinecone.describe_collection("bakcup-collection")
• Delete collection -
pinecone.delete_collection("bakcup-collection")](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-18-320.jpg)
![Dense vector vs Sparse data
• Pinecone supports both Dense vector and Sparse vector.
• Till now, we have only played with Dense vectors.
Index 1
1 [ 1.0,2.0, …. 10.0] indices [1,2], values [10,0, 20.5] {“key1”: “val1”, “key2”: “val2”}
2 [ 1.0,2.0, …. 10.0] indices [1,2], values [10,0, 20.5] {“key1”: “val1”, “key2”: “val2”}
N [ 1.0,2.0, …. 10.0] indices [1,2], values [10,0, 20.5] {“key1”: “val1”, “key2”: “val2”}
ID Dense Vector Sparse Vector Metadata
both Dense vector and Sparse vector could be part of a record](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-19-320.jpg)
![Inserting sparse data
• Sparse vector values can be upserted alongside dense vector values -
index.upsert(vectors=[{'id': 'id1', 'values': [0.1, 0.2, 0.3, 0.4, 0.5],
'sparse_values':{ 'indices':[1,2], 'values': [10.0, 20.5] } }])
• Note that you cannot upsert a record with sparse vector values without dense vector values
index.upsert(vectors=[{'id': 'id1', 'sparse_values':{ 'indices':[1,2], 'values':
[10.0, 20.5] } }])
ValueError: Vector dictionary is missing required fields: ['values']](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-20-320.jpg)
![Fetch data, and update data
• Fetch data by passing ids of the record
index.fetch(ids=['Bangalore', 'Kolkata’])
{'namespace': '',
'vectors': {'Bangalore': {'id': 'Bangalore', 'metadata': {}, 'values': [1.0, 2.234,
3.34, 5.6, 7.8]},
'Kolkata': {'id': 'Kolkata', 'metadata': {}, 'values': [2.0, 1.234,
3.34, 5.6, 7.8]}}}
• Update a record – both values (vector) and metadata could be updated
index.update(id='Bangalore', set_metadata={"type":"city", "sub-type":"non-metro"},
values=[1.0, 2.0, 3.0, 4.0, 5.0])
index.fetch(ids=['Bangalore’])
{'namespace': '',
'vectors': {'Bangalore': {'id': 'Bangalore', 'metadata': {'sub-type': 'non-metro',
'type': 'city'}, 'values': [1.0, 2.0, 3.0, 4.0, 5.0]}}}](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-21-320.jpg)
![Query data
• Query data by vector match
index.query(vector=[1.0, 2.0, 3.0, 5, 7.0], top_k=3, include_values=True)
{'matches': [{'id': 'Bangalore', 'score': 0.999296784, 'values': [1.0, 2.0, 3.0,
5.0, 7.0]},
{'id': 'Delhi', 'score': 0.997676671, 'values': [1.0, 2.234, 3.34,
5.6, 7.8]},
{'id': 'Den Haag', 'score': 0.997676671, 'values': [1.0, 2.234, 3.34,
5.6, 7.8]}], 'namespace': ‘’}
• Apart from id and values (vector data), metadata of each matched record also could be retrieved
index.query(vector=[1.0, 2.0, 3.0, 5, 7.0], top_k=3, include_values=True,
include_metadata=True)](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-22-320.jpg)
![Namespace
• Pinecone allows you to partition the records in an index into namespaces. Queries and other
operations are then limited to one namespace, so different requests can search different subsets of
your index.
• A new namespace could be created by inserting a record to an index by specifying a new namespace
-
index.upsert(
vectors = [
("Howrah", [1.0, 2.234, 3.34, 5.6, 7.8], {"type": "city", "sub-type":
"metro"}),
("Siliguri", [2.0, 1.234, 3.34, 5.6, 7.8], {"type": "city", "sub-type":
"non-metro"})
], namespace='my-first-namespace')
• By default each index contains a single default index.](https://image.slidesharecdn.com/pineconevectordatabase-231007151633-ea996d0b/85/Pinecone-Vector-Database-pdf-23-320.jpg)










































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)












