Download as PDF, PPTX



![Kubernetes TL;DR Edition
● Declarative system.
● Steers cluster towards desired
state.
● EVERYTHING is an API Object.
● Objects generally describe in
YAML.
apiVersion: batch/v1
kind: Job
metadata:
name: job-example
spec:
backoffLimit: 4
completions: 4
parallelism: 2
template:
spec:
containers:
- name: hello
image: alpine:latest
command: ["/bin/sh", "-c"]
args: ["echo hello from $HOSTNAME!"]
restartPolicy: Never](https://image.slidesharecdn.com/kubernetes-thenextresearchplatform-190316162622/85/Kubernetes-The-Next-Research-Platform-4-320.jpg)














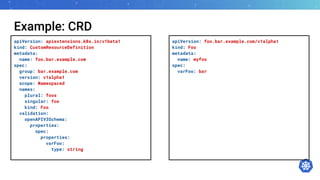


![Native vs CRD
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world
spec:
completions: 1
template:
spec:
containers:
- name: hello
image: alpine:latest
command: ["/bin/sh", "-c"]
args: ["echo Hello World”]
restartPolicy: Never
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: hello
arguments:
parameters:
- name: message
value: Hello World
templates:
- name: hello
inputs:
parameters:
- name: message
container:
image: alpine:latest
command: ["/bin/sh", "-c"]
args: ["echo {{inputs.parameters.message}}"]](https://image.slidesharecdn.com/kubernetes-thenextresearchplatform-190316162622/85/Kubernetes-The-Next-Research-Platform-22-320.jpg)















Kubernetes is a container orchestration system designed for deploying, maintaining, and scaling workloads, supporting both on-premises and cloud environments. It is widely adopted in research for its flexibility and the ability to manage complex applications, though it presents challenges in integrating with traditional infrastructures and high-performance computing. The ecosystem includes tools like Helm for package management, and projects like Kubeflow for machine learning deployments, highlighting Kubernetes' robust extensibility and community support.








































![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)


















