Downloaded 16 times

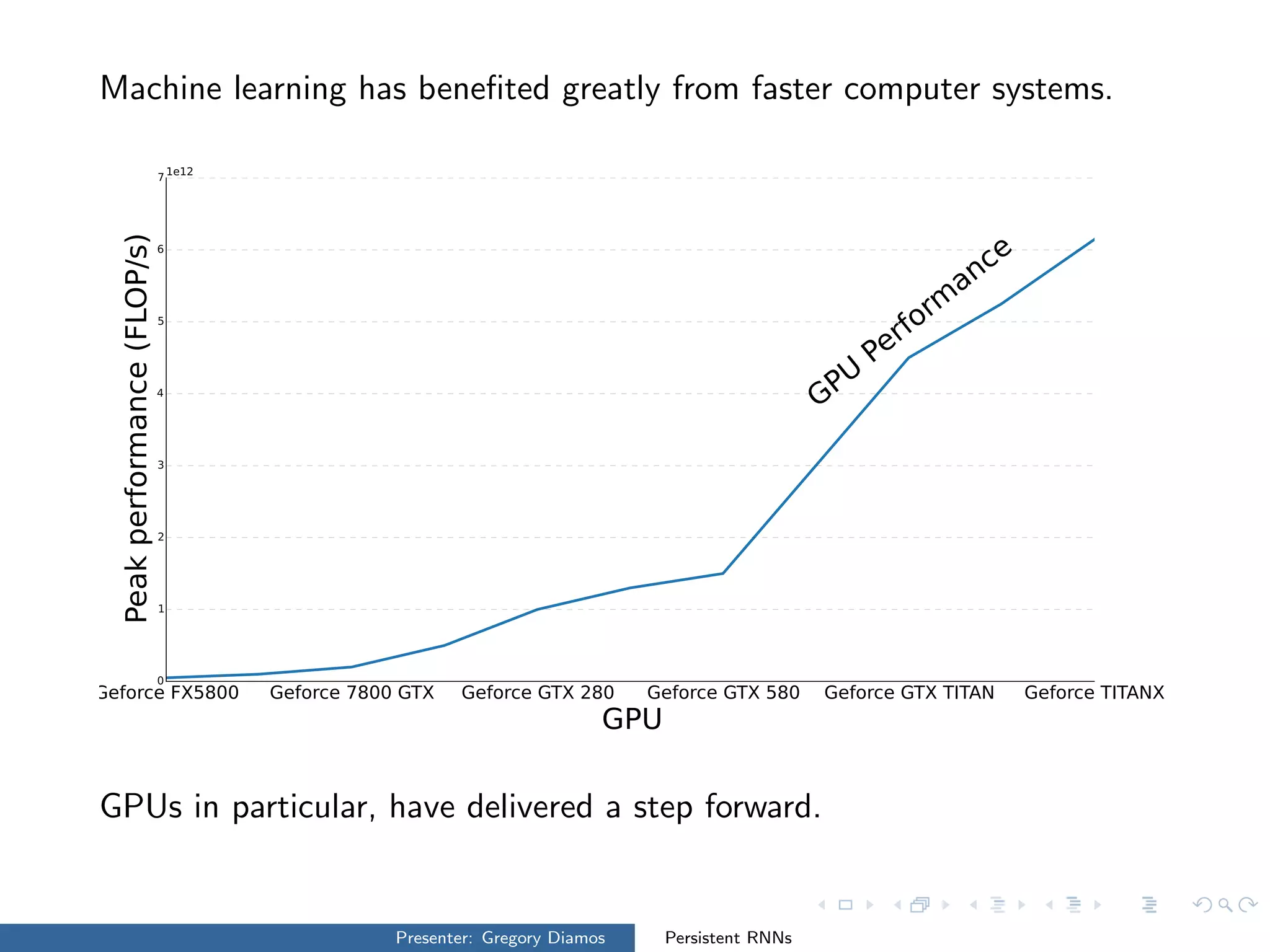

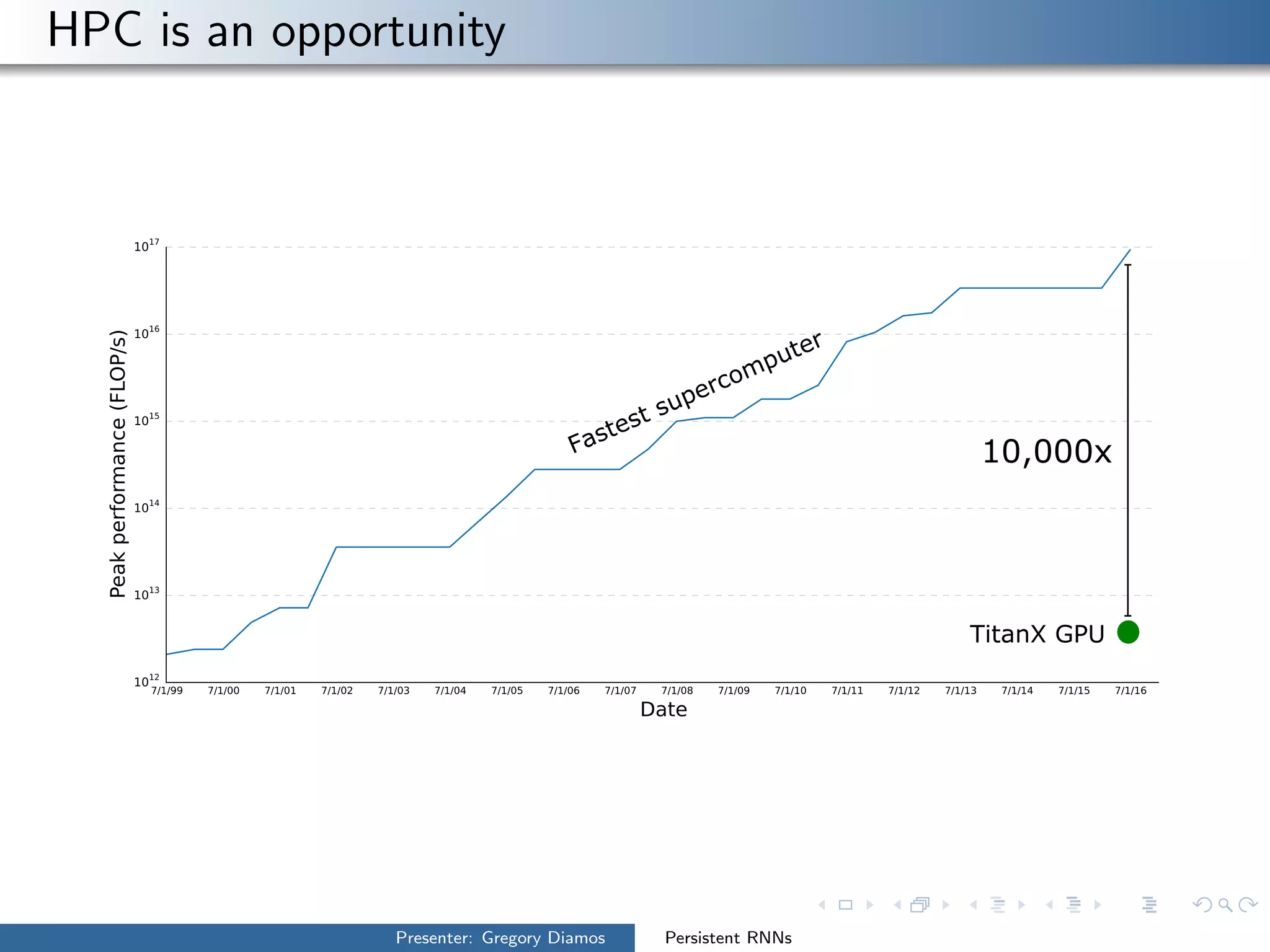

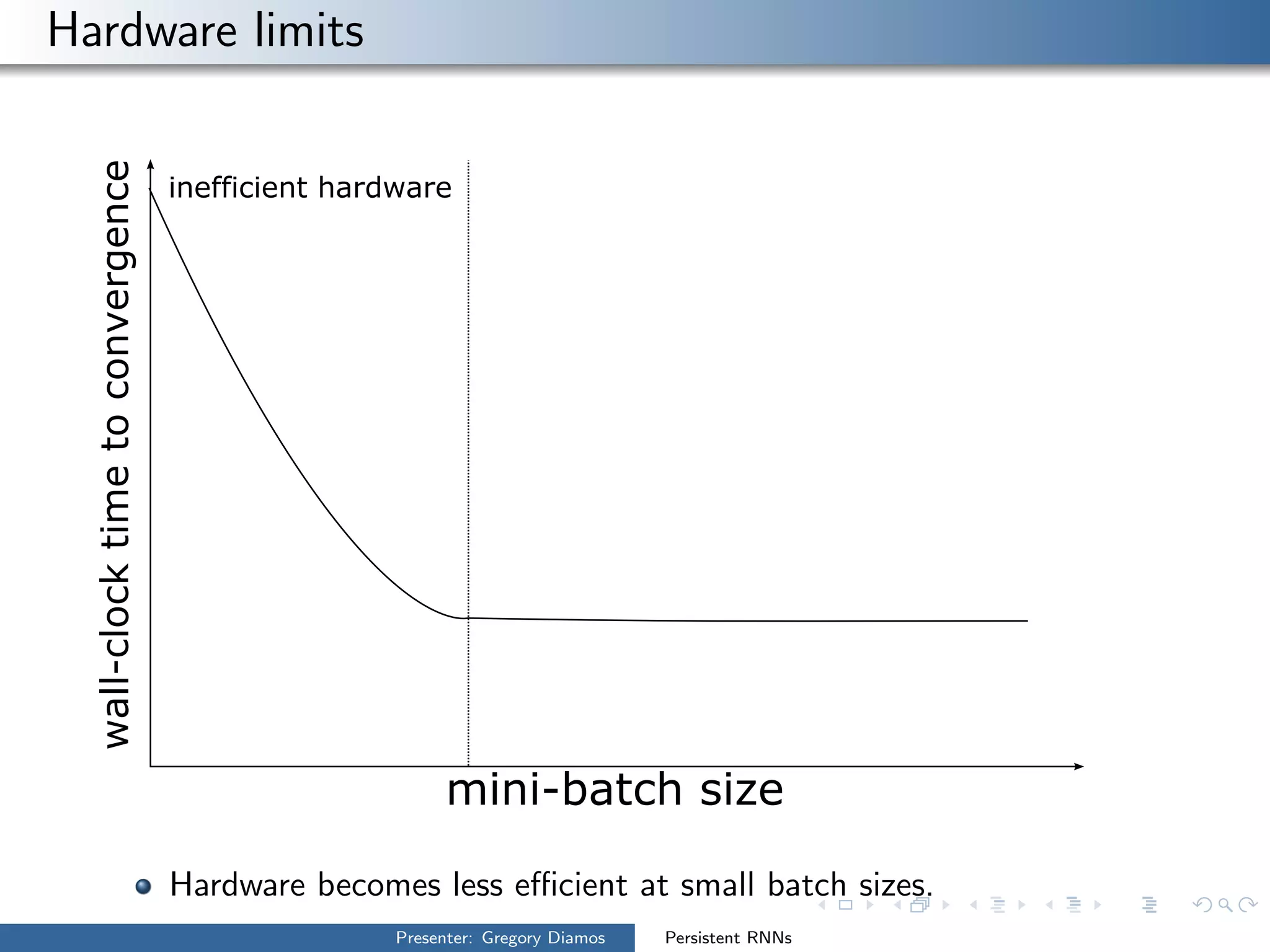
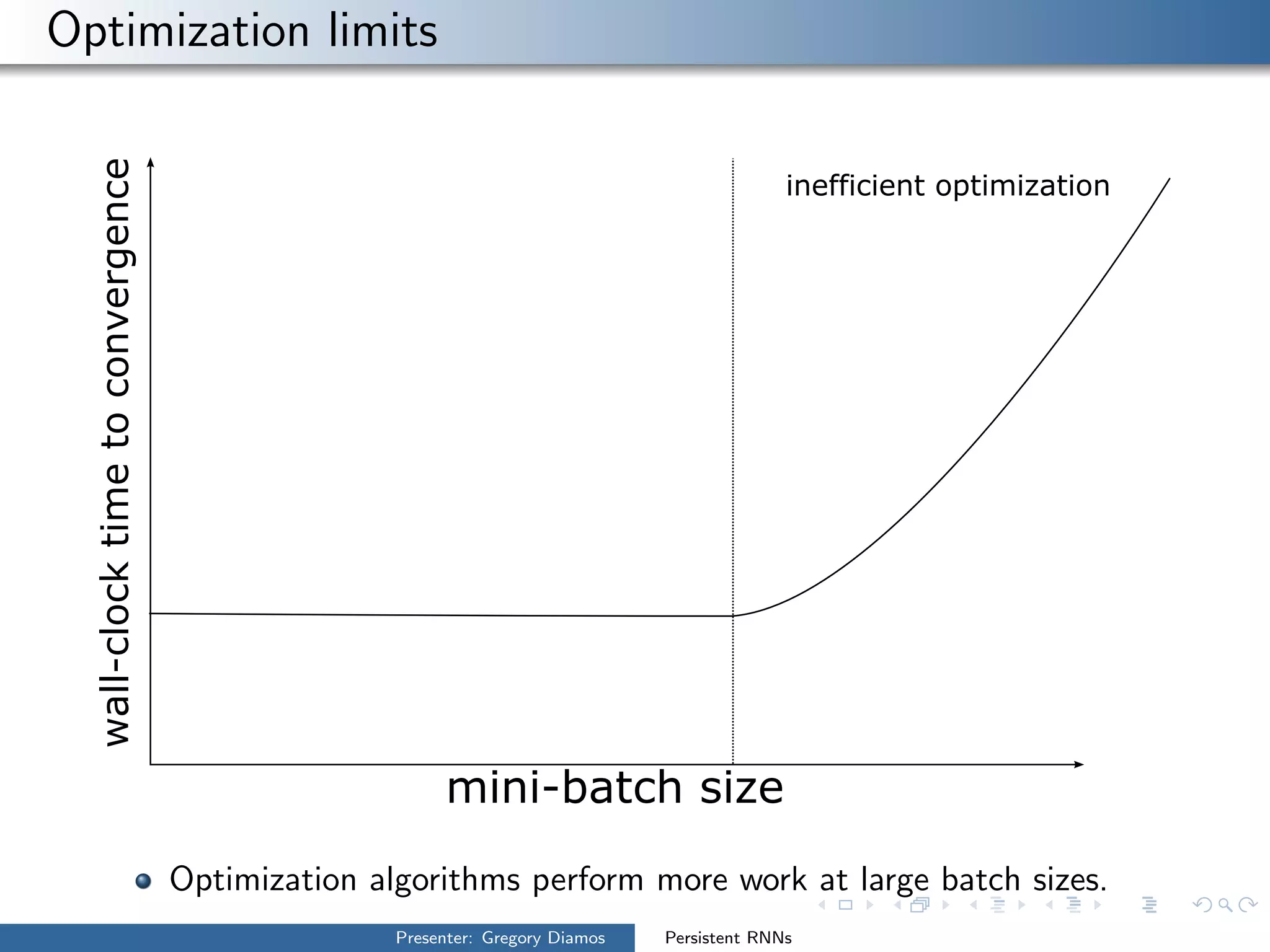
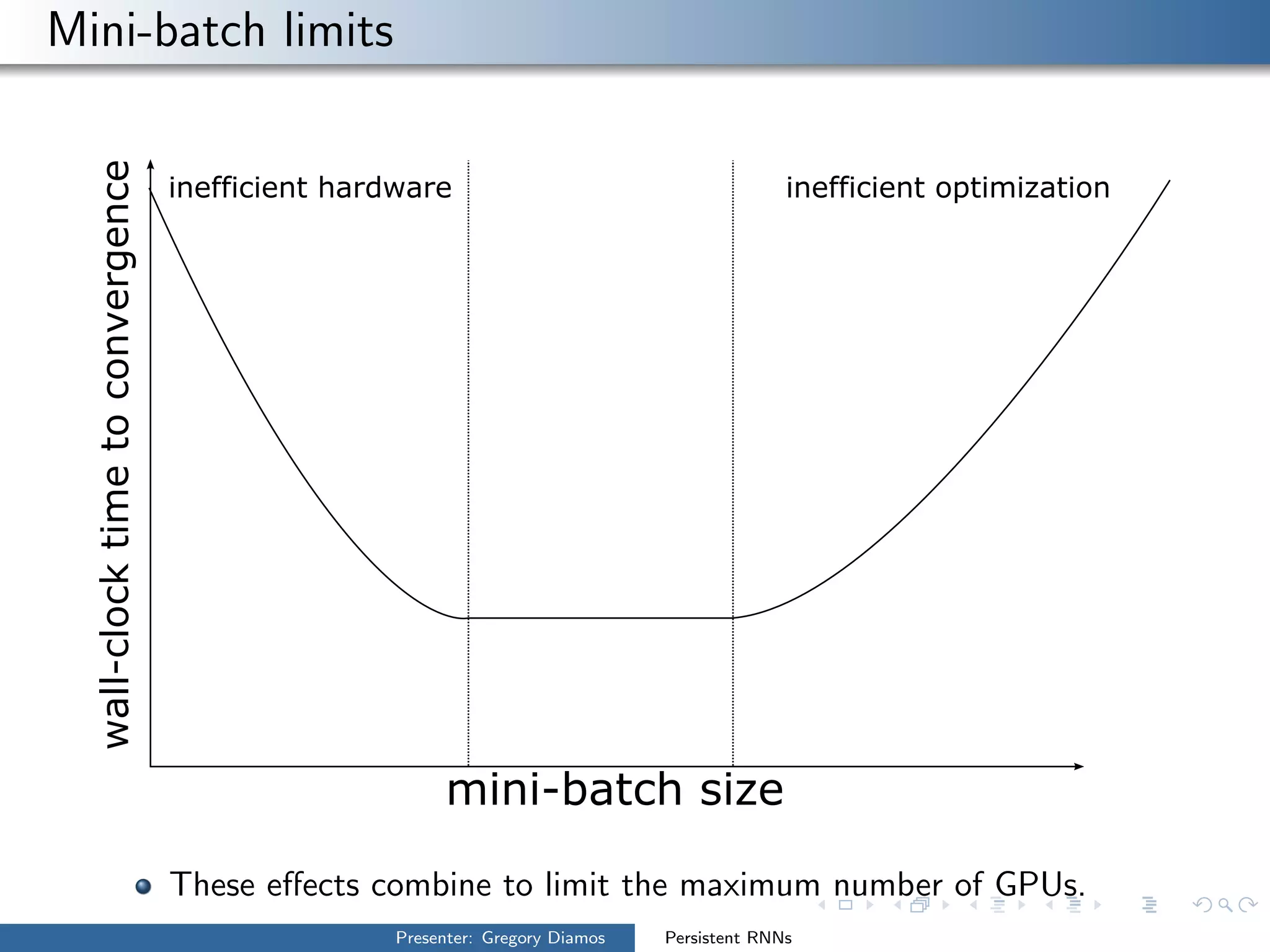
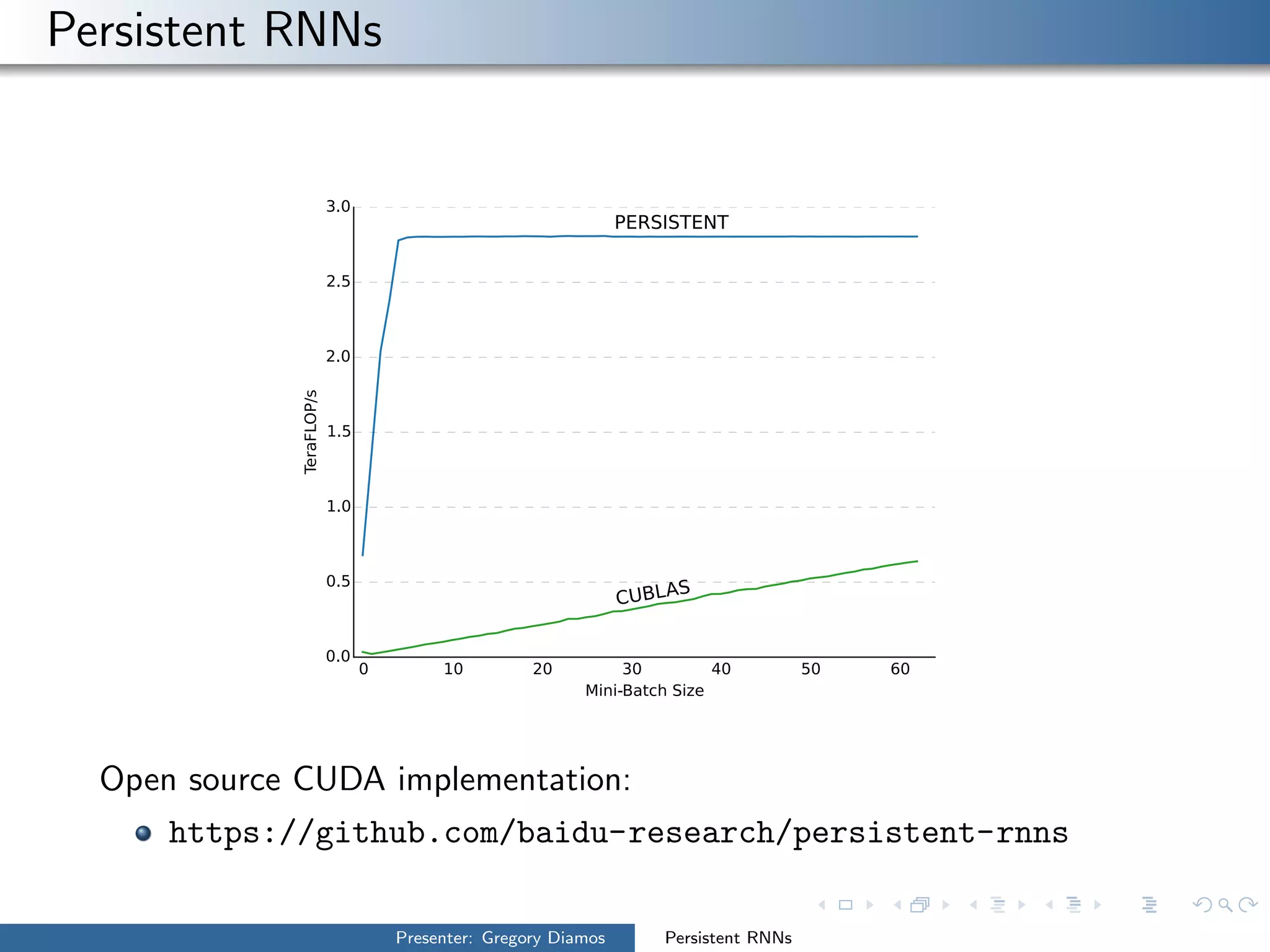

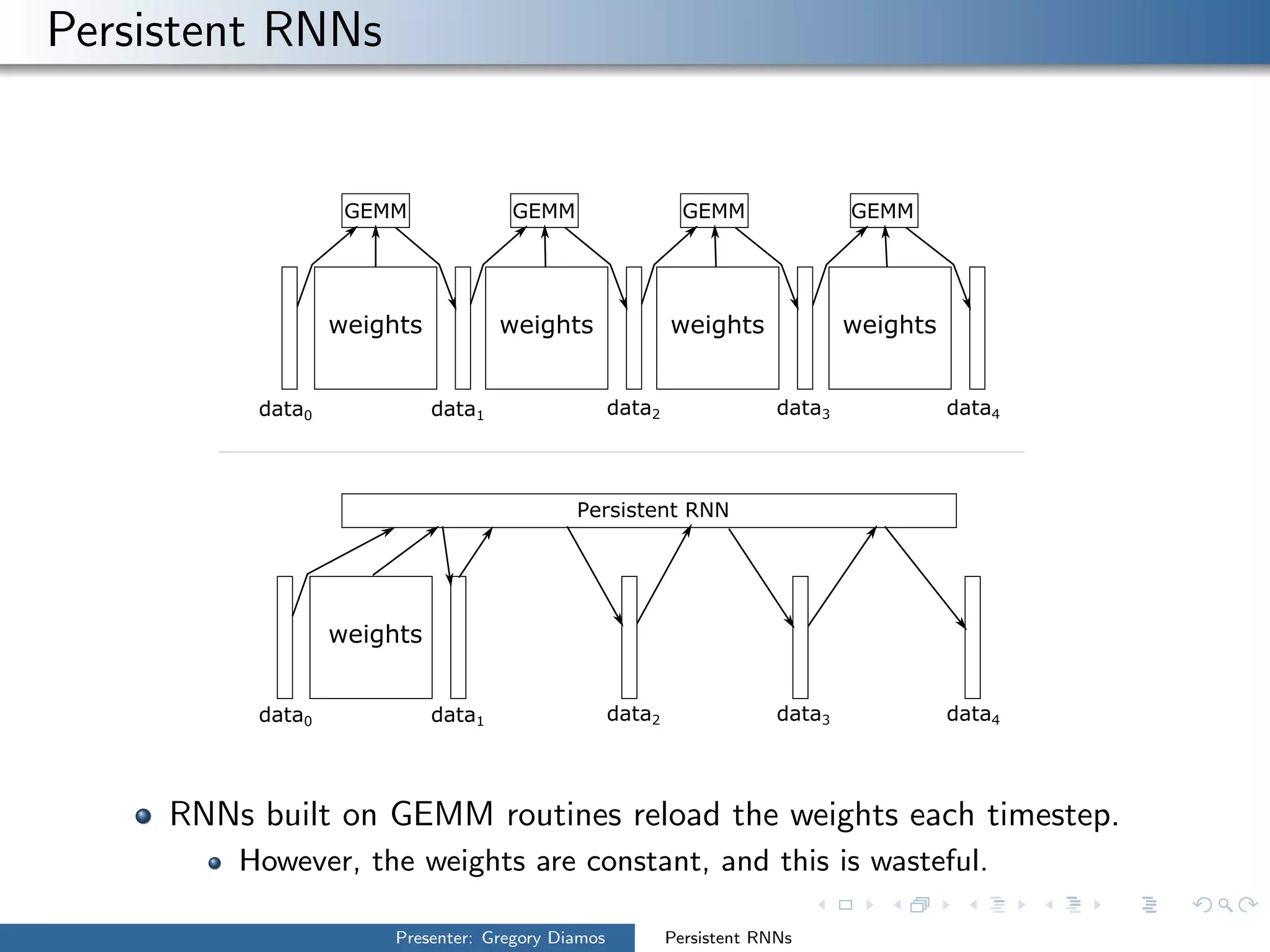
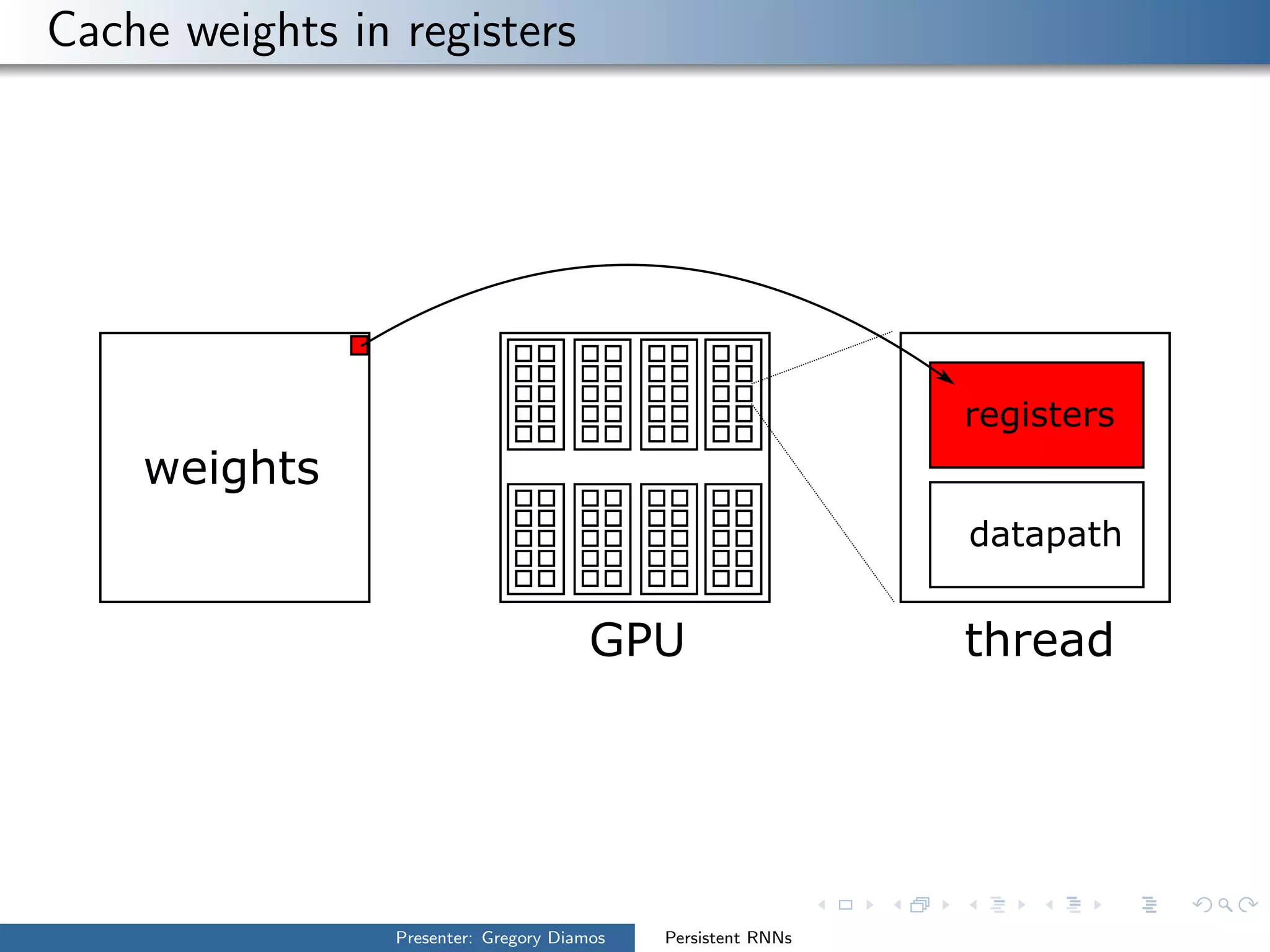
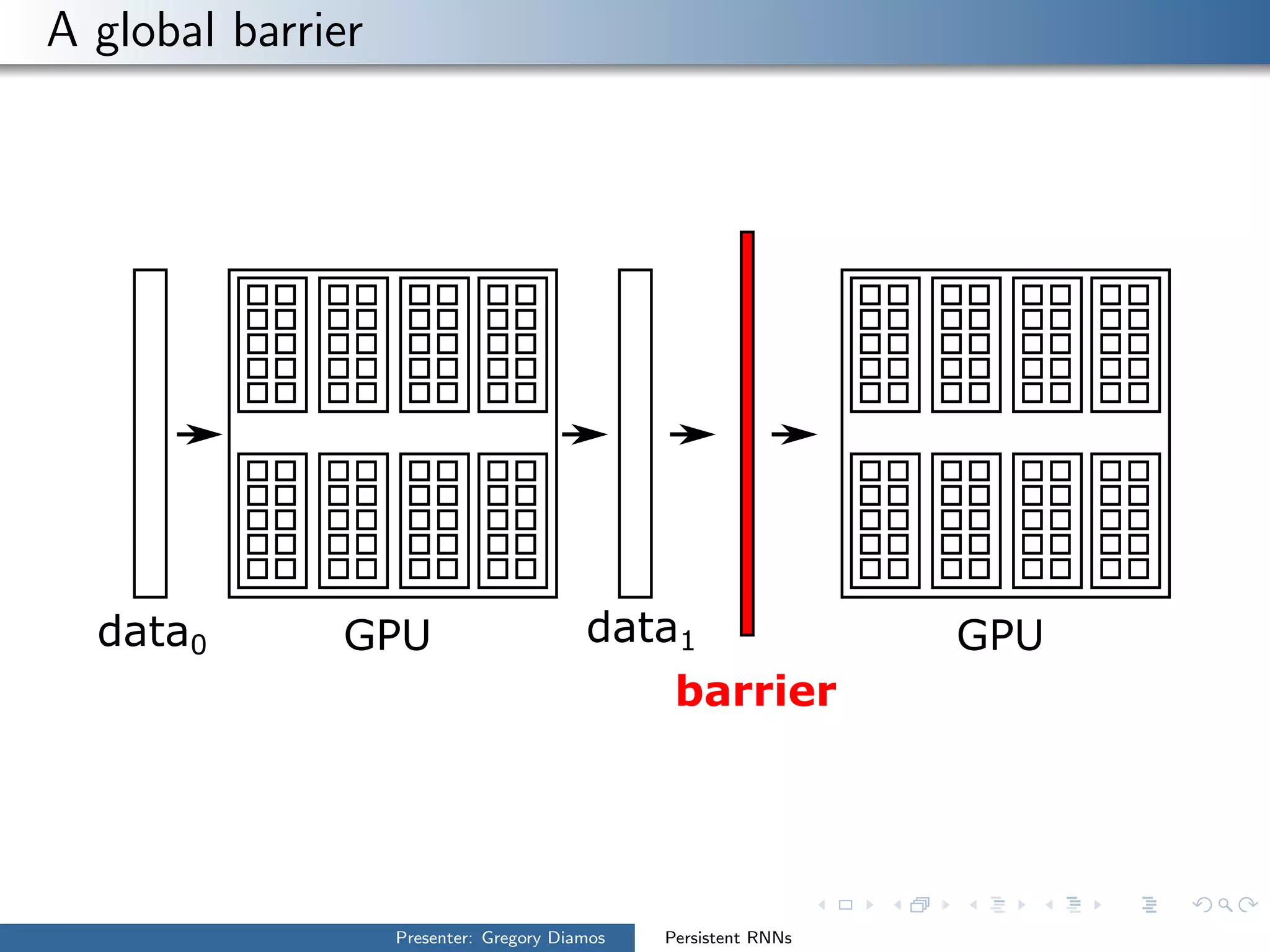

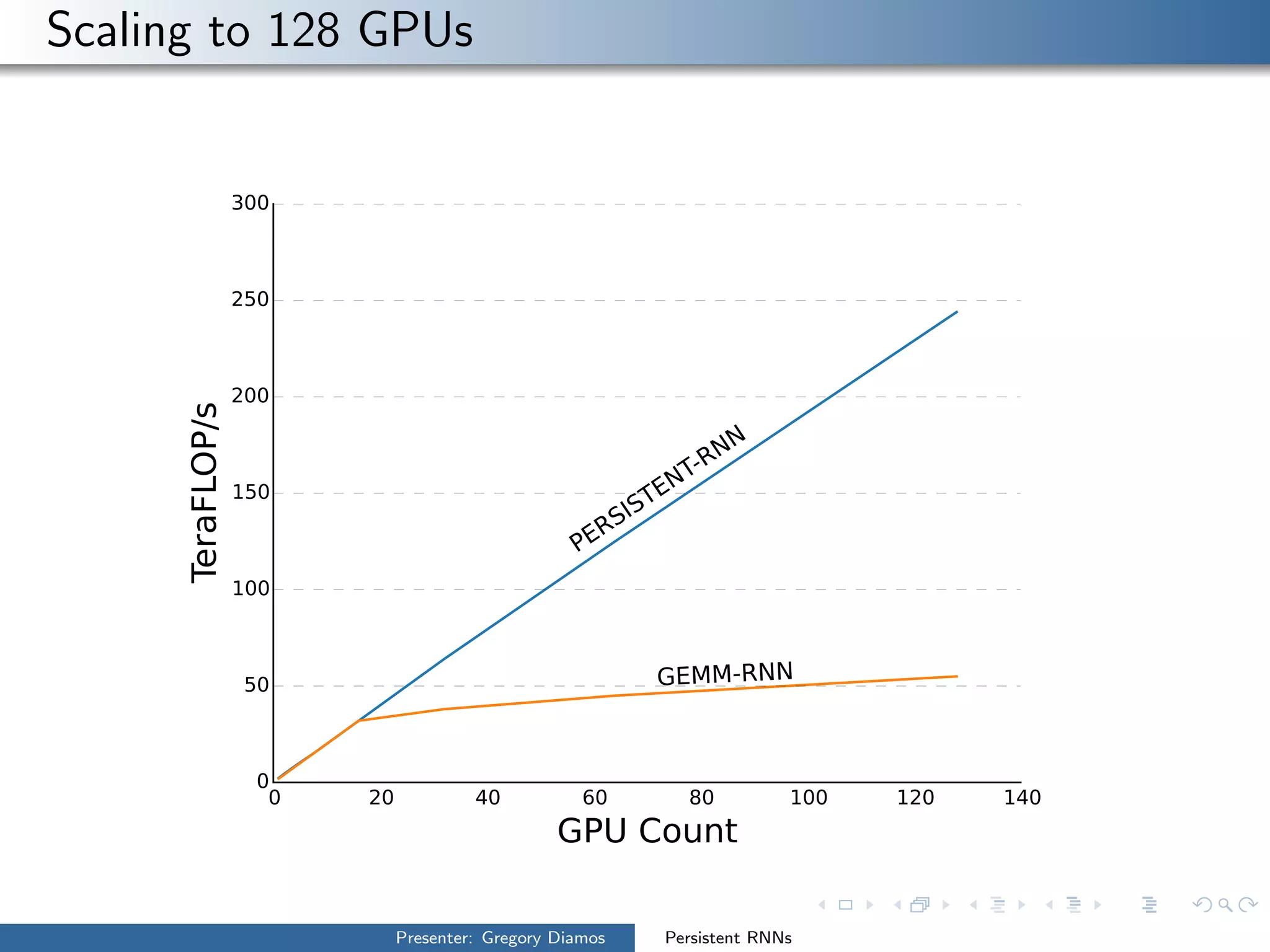
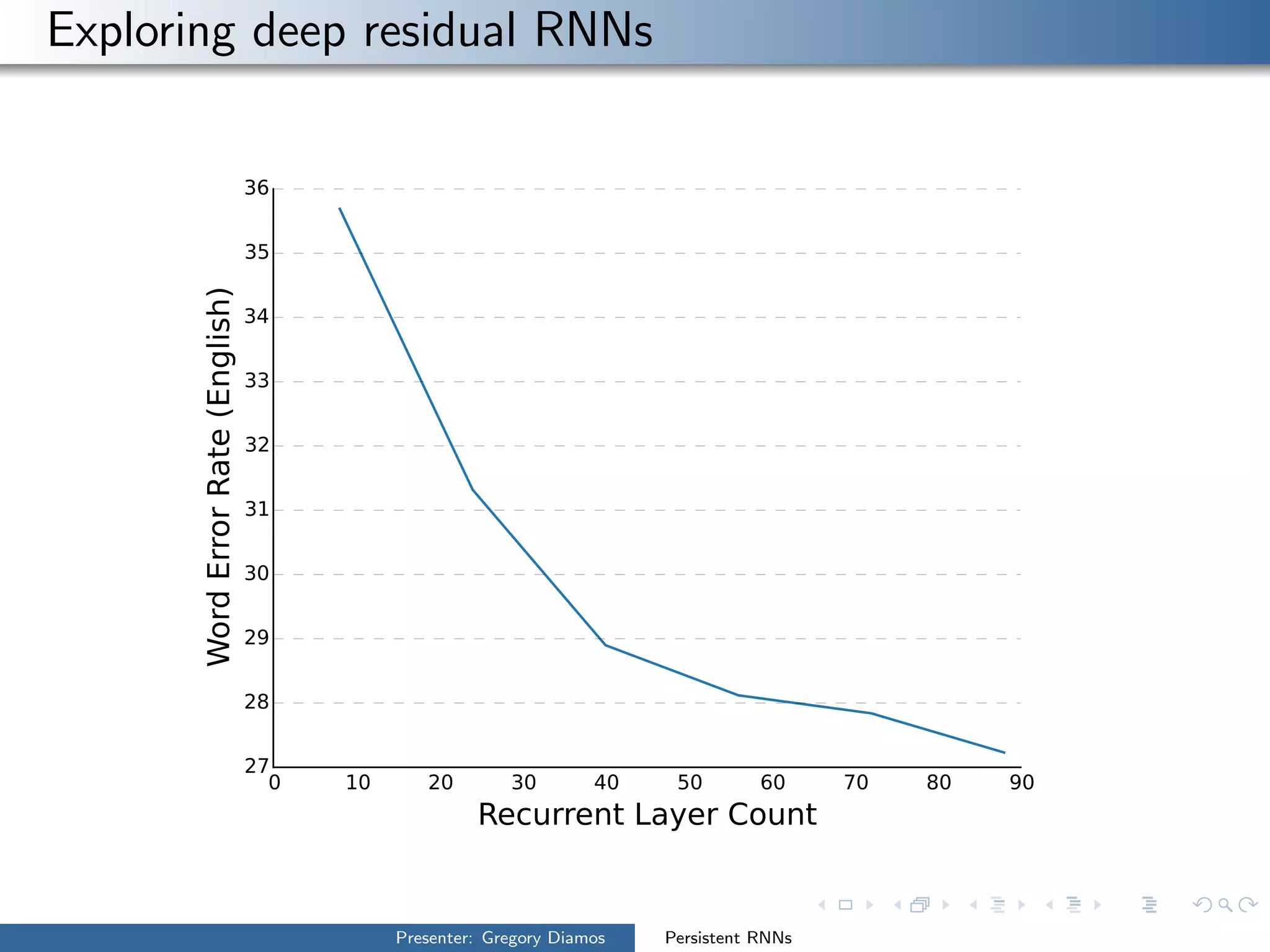
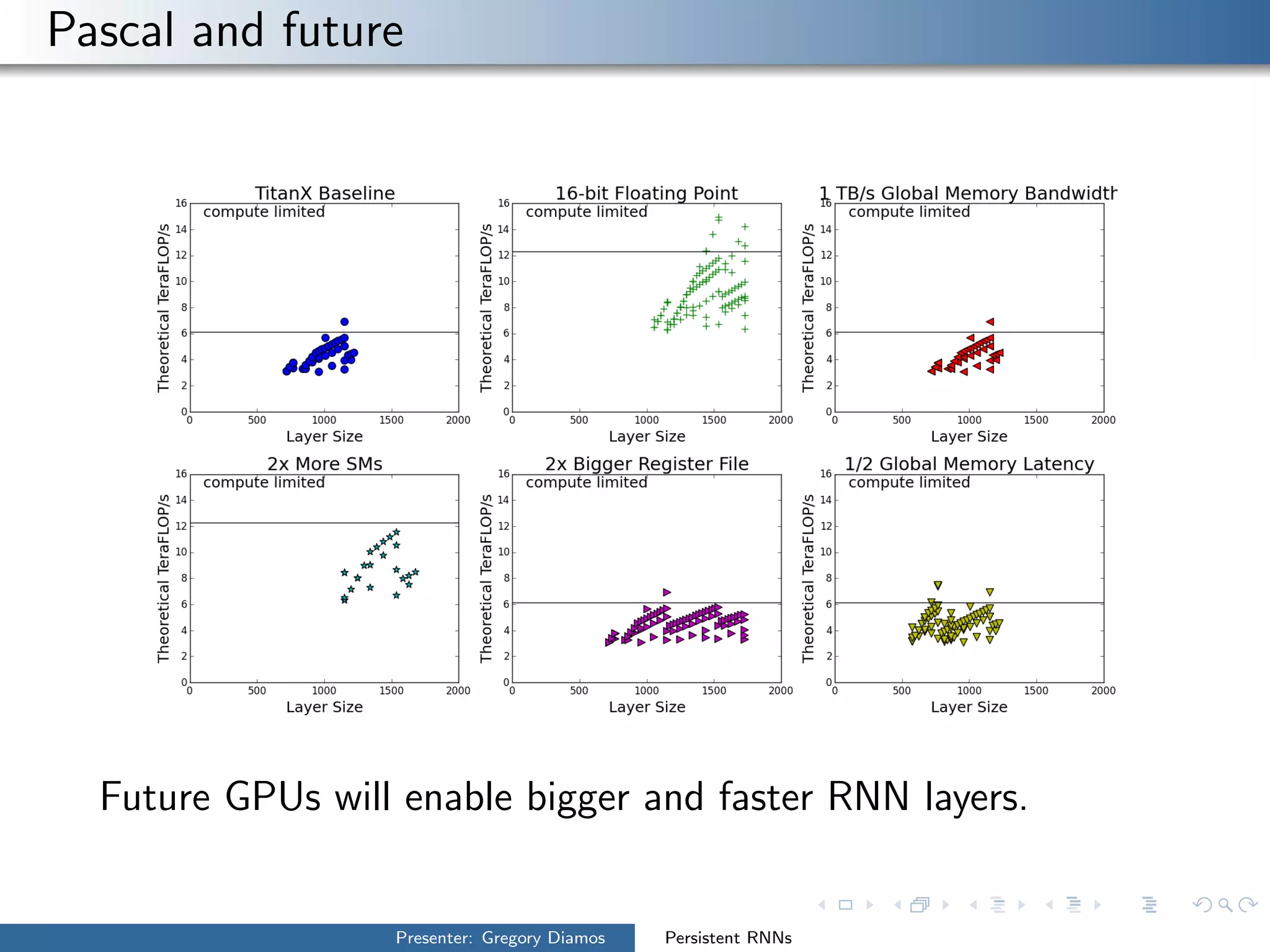





The presentation by Gregory Diamos discusses how persistent RNNs can enhance machine learning performance by efficiently utilizing GPU resources, particularly addressing the issues of data-parallelism and optimization limits. It emphasizes the potential of scaling RNNs with upcoming GPU technology while encouraging the development of more efficient algorithms. The speaker advocates for pushing performance boundaries towards achieving significant computational outputs with minimal energy consumption.










![Bio—chip ] sensor](https://cdn.slidesharecdn.com/ss_thumbnails/biochipsensor-160414183218-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












