Downloaded 16 times







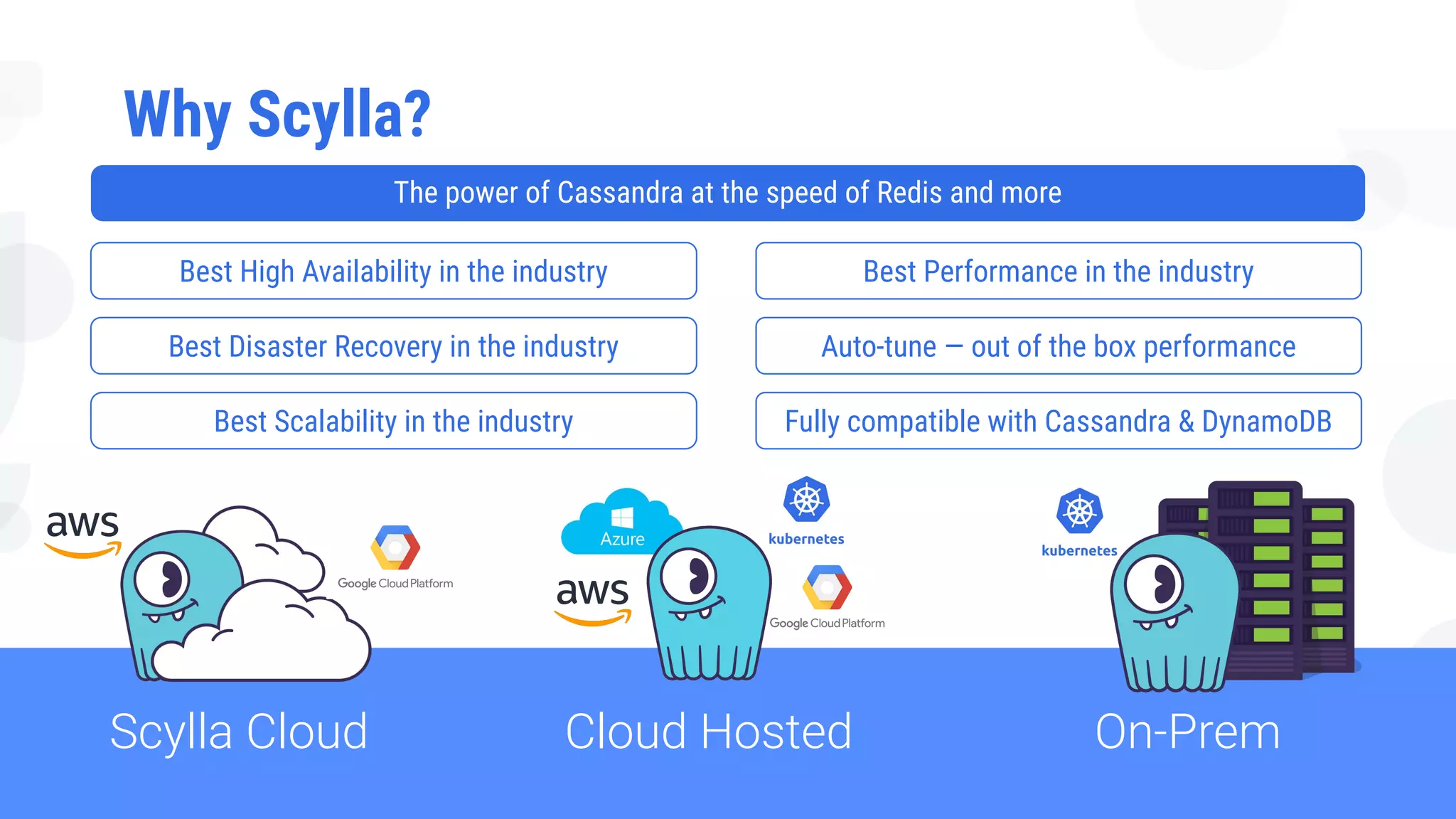

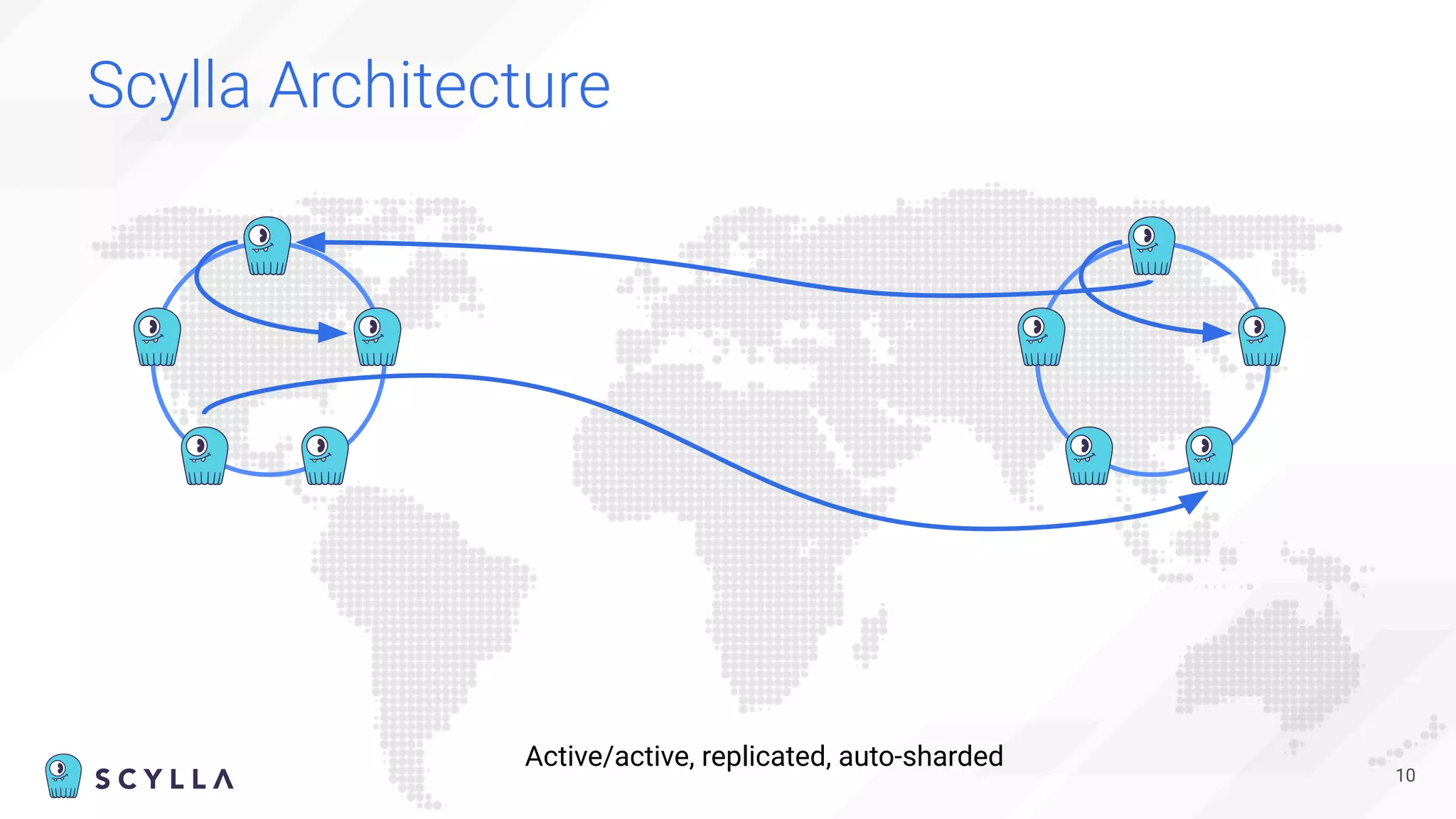

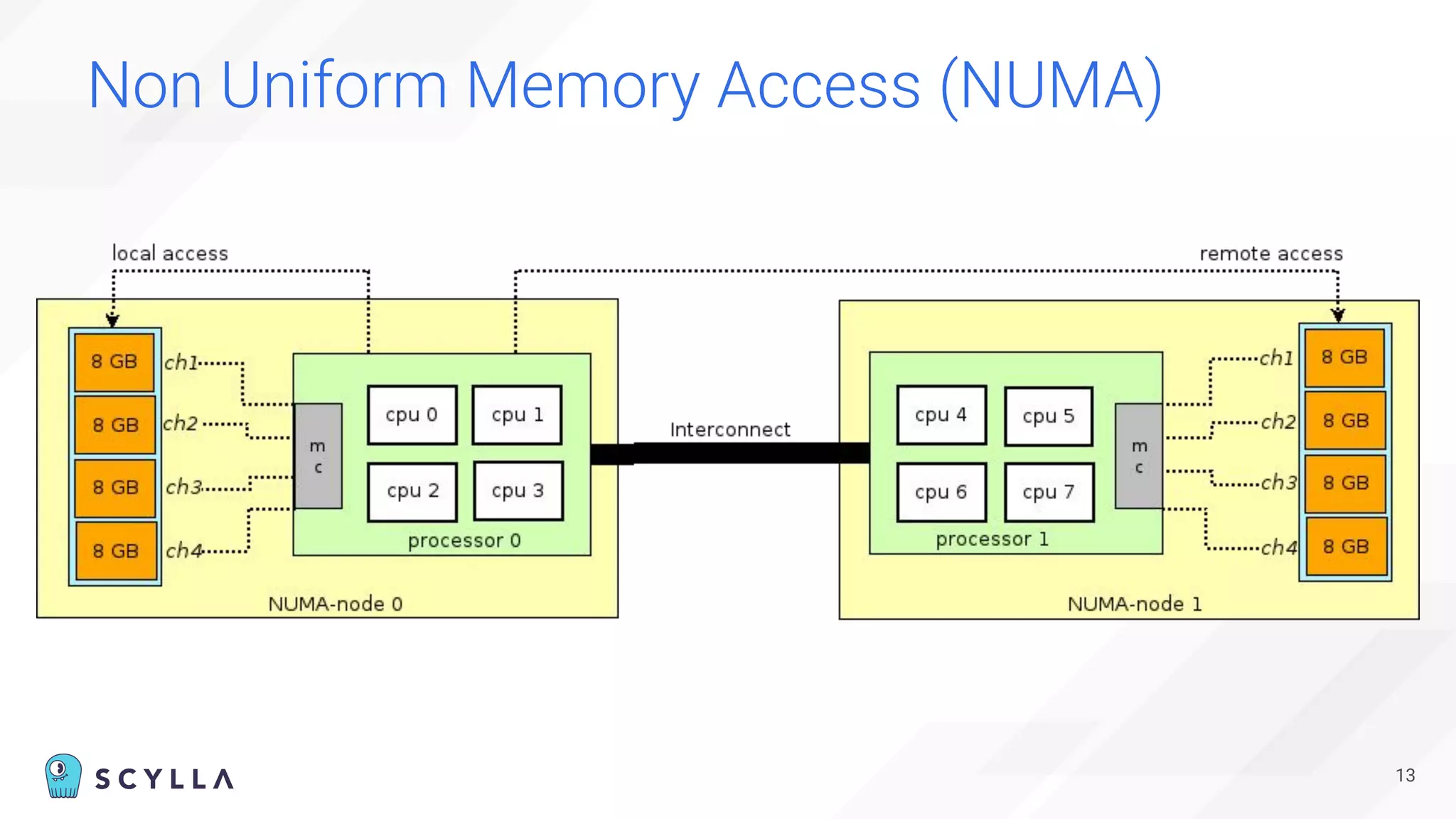

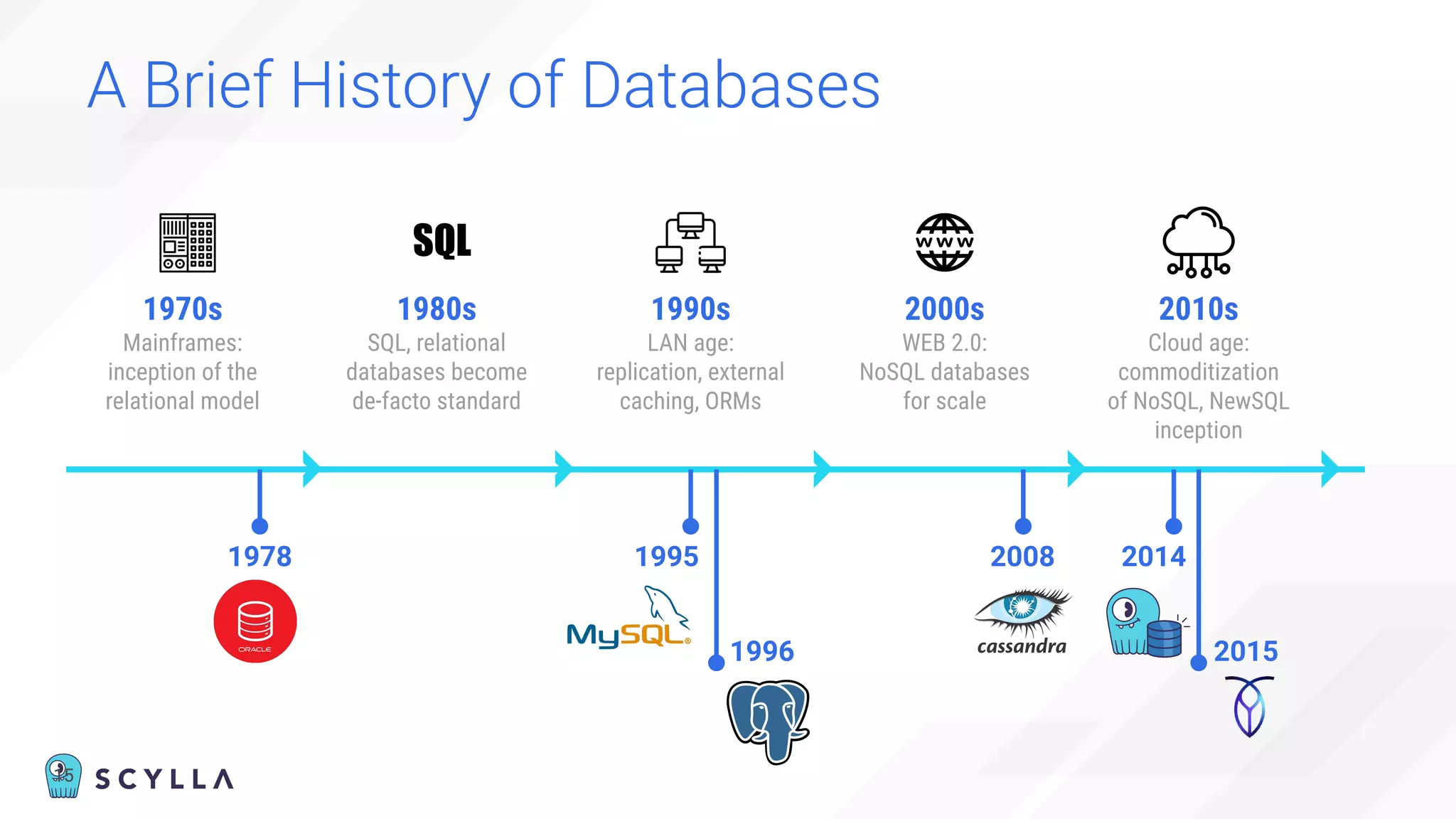
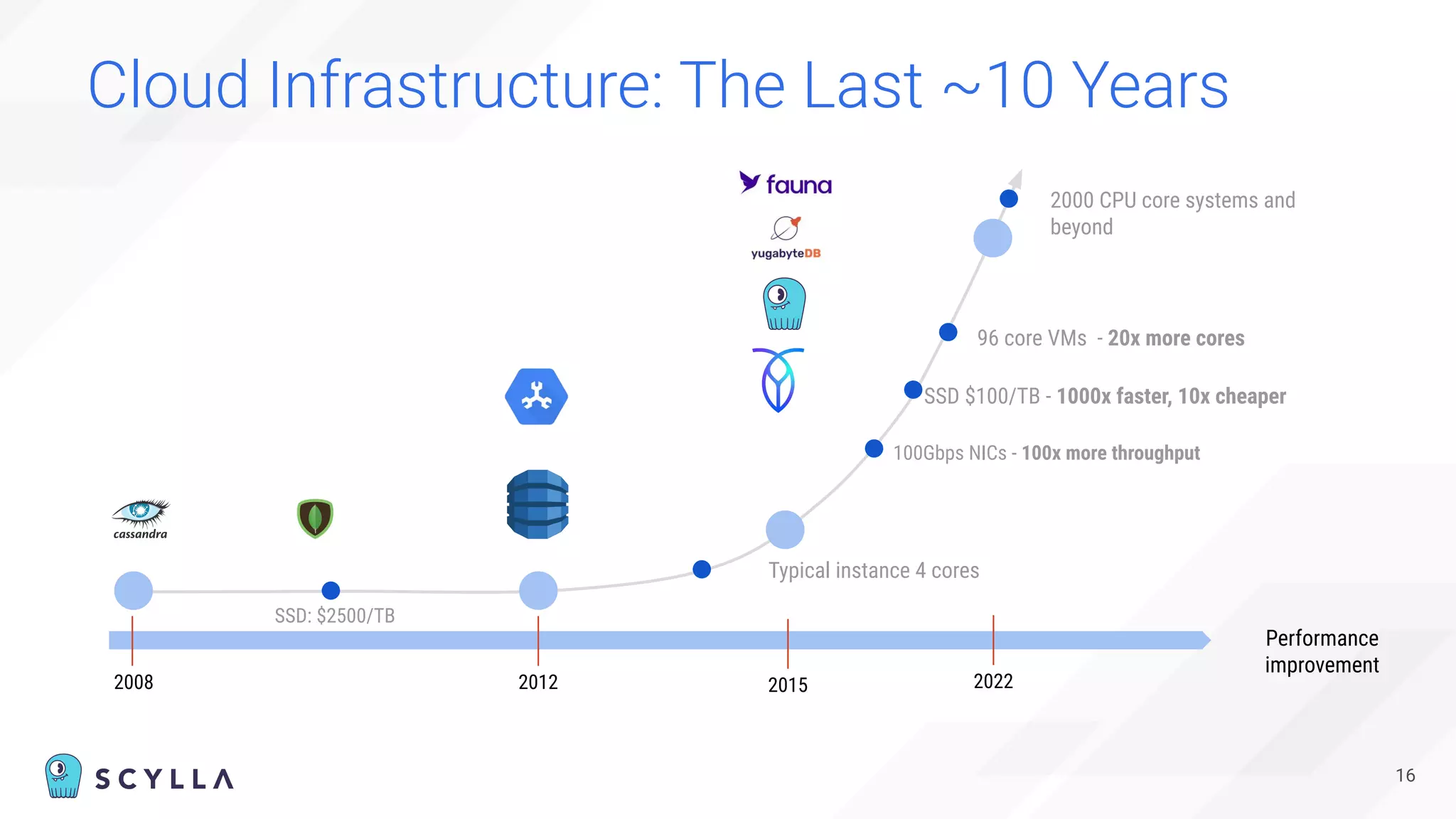

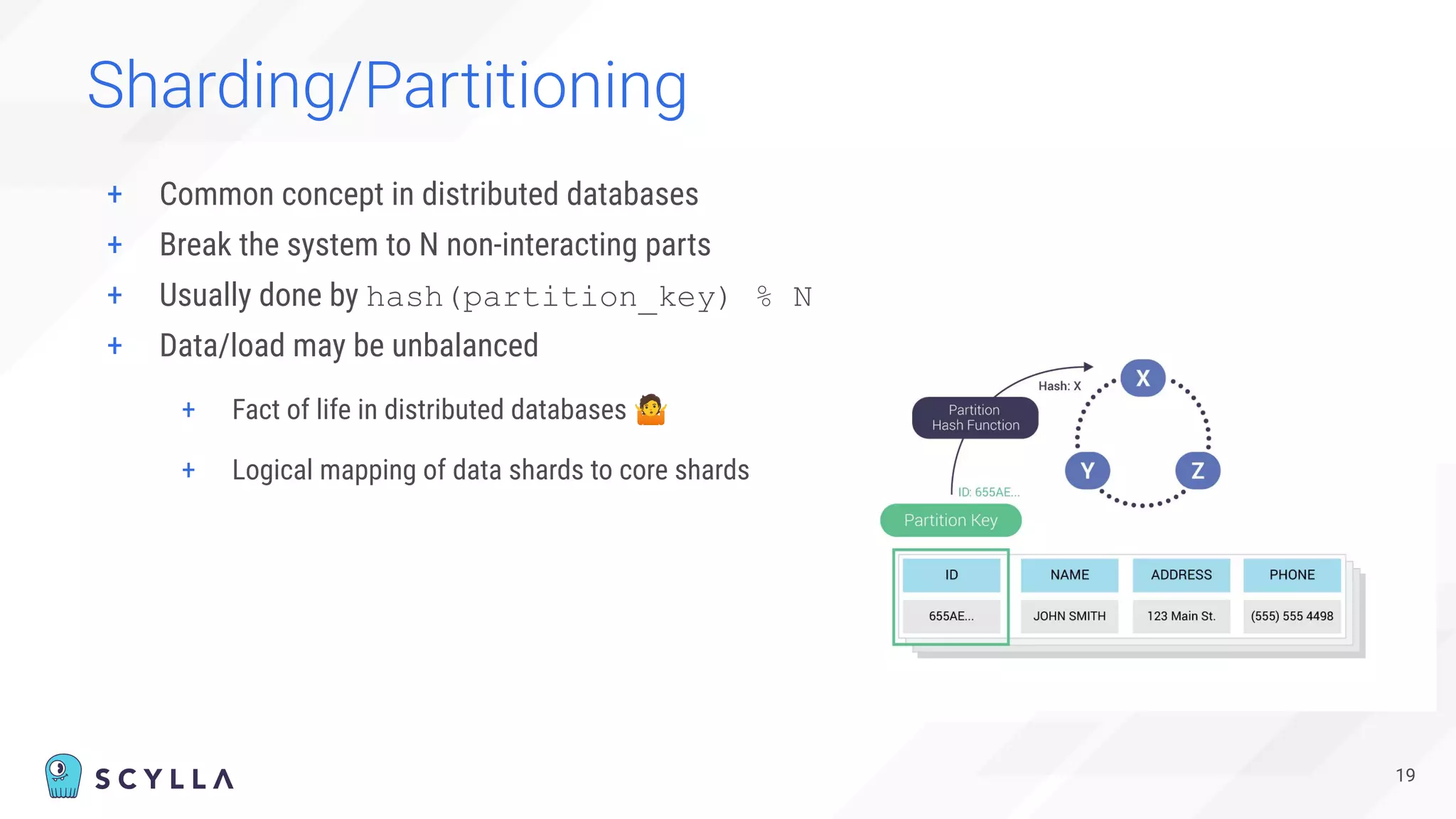
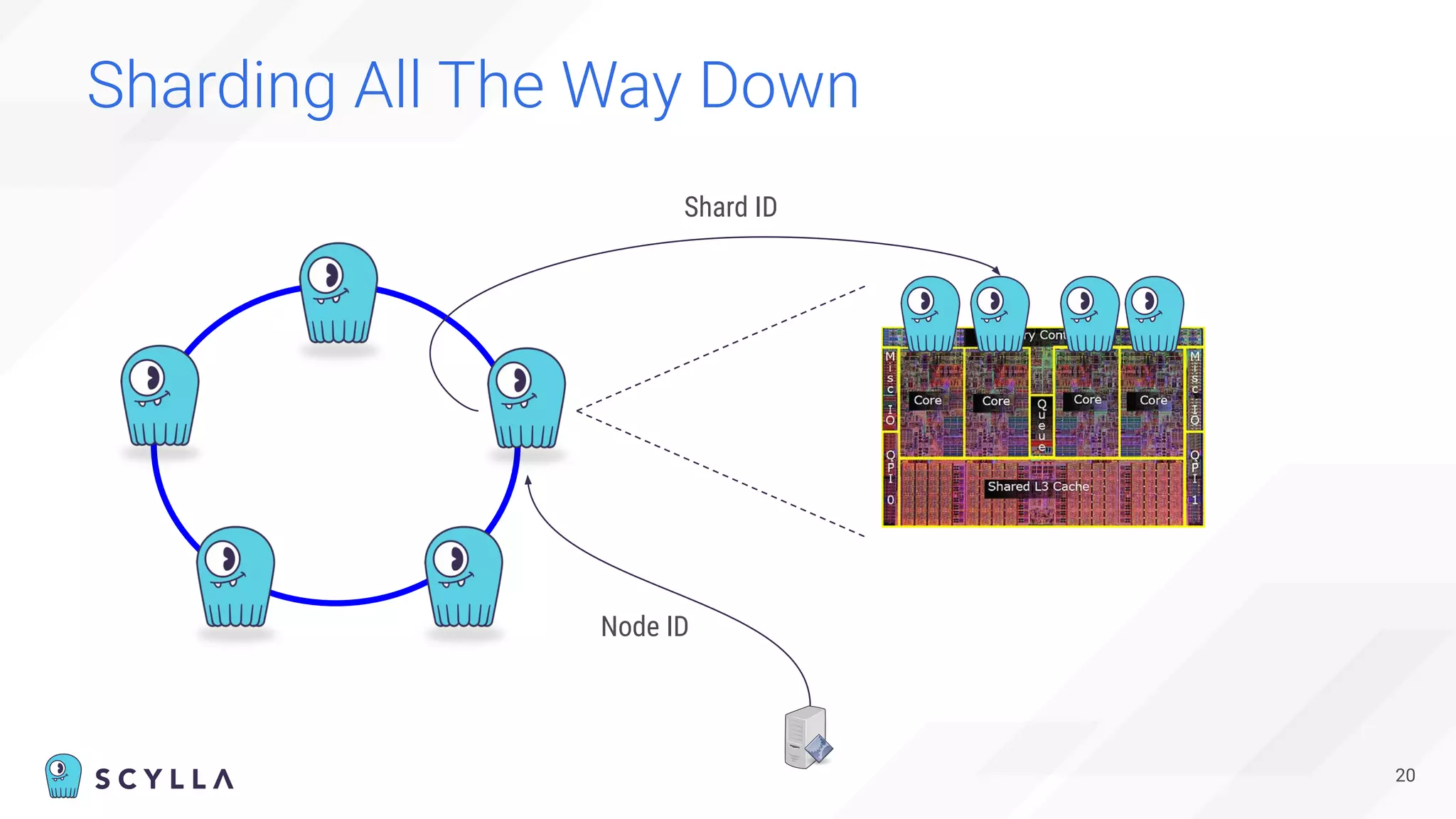
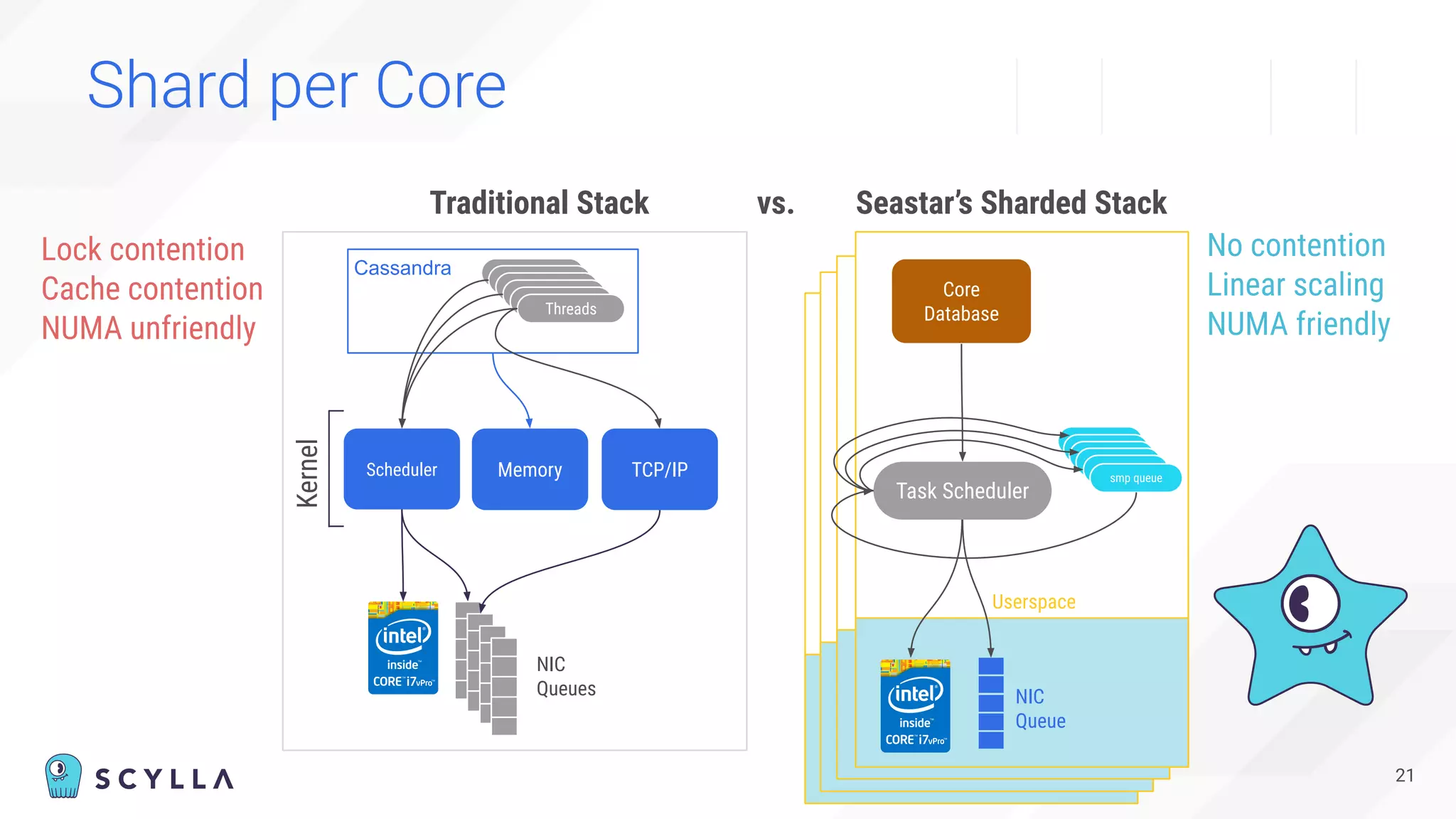
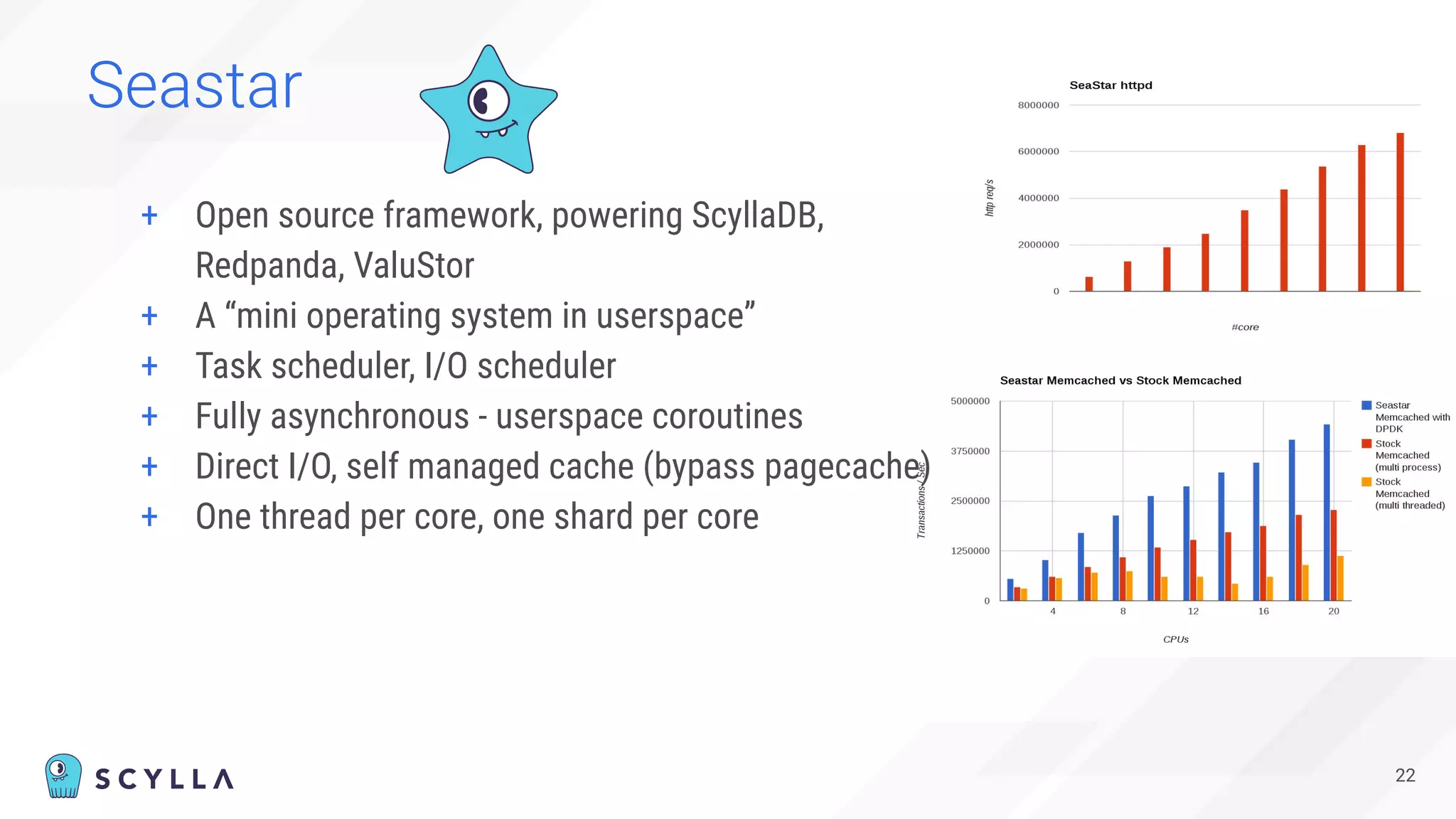



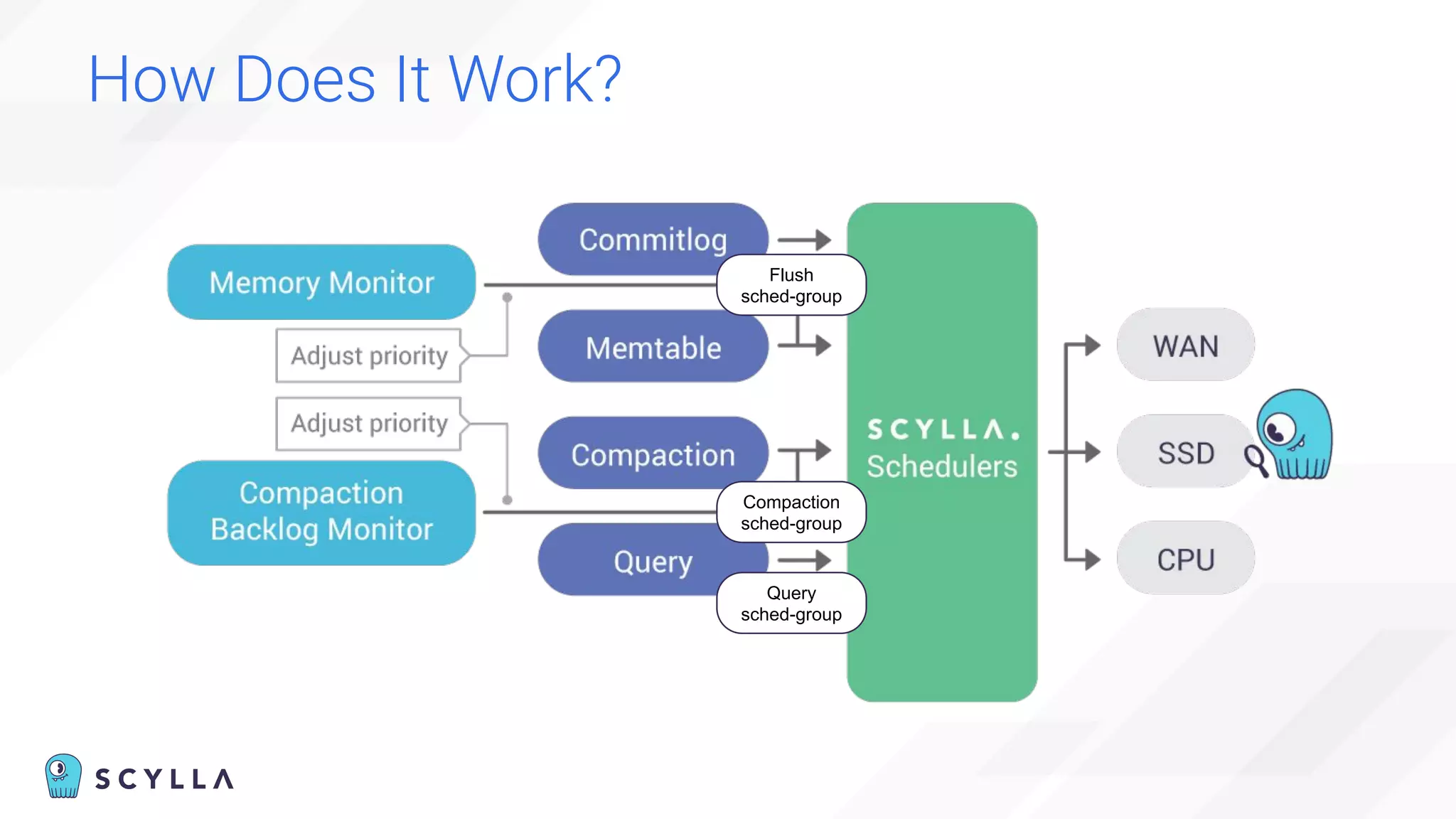
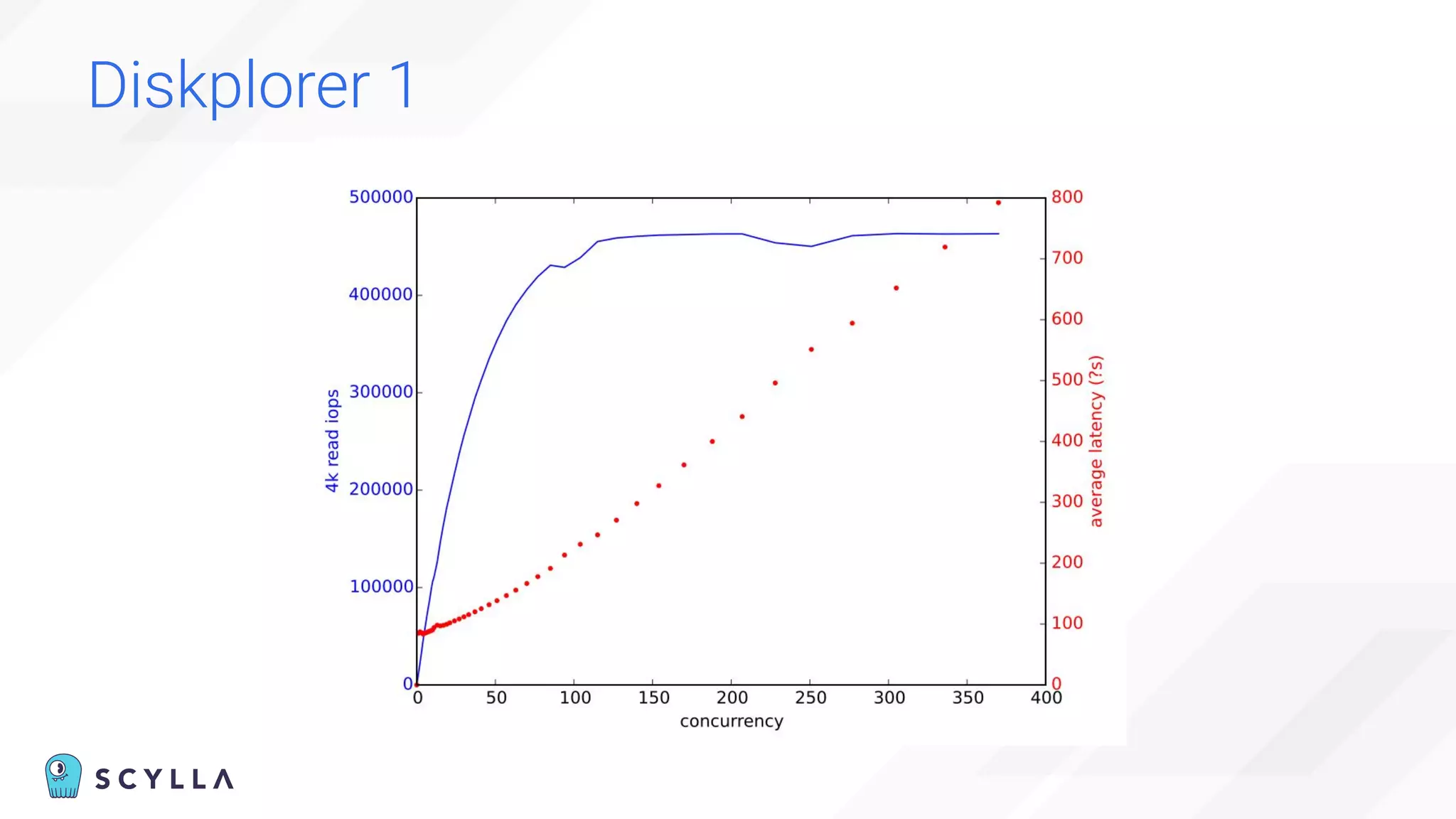
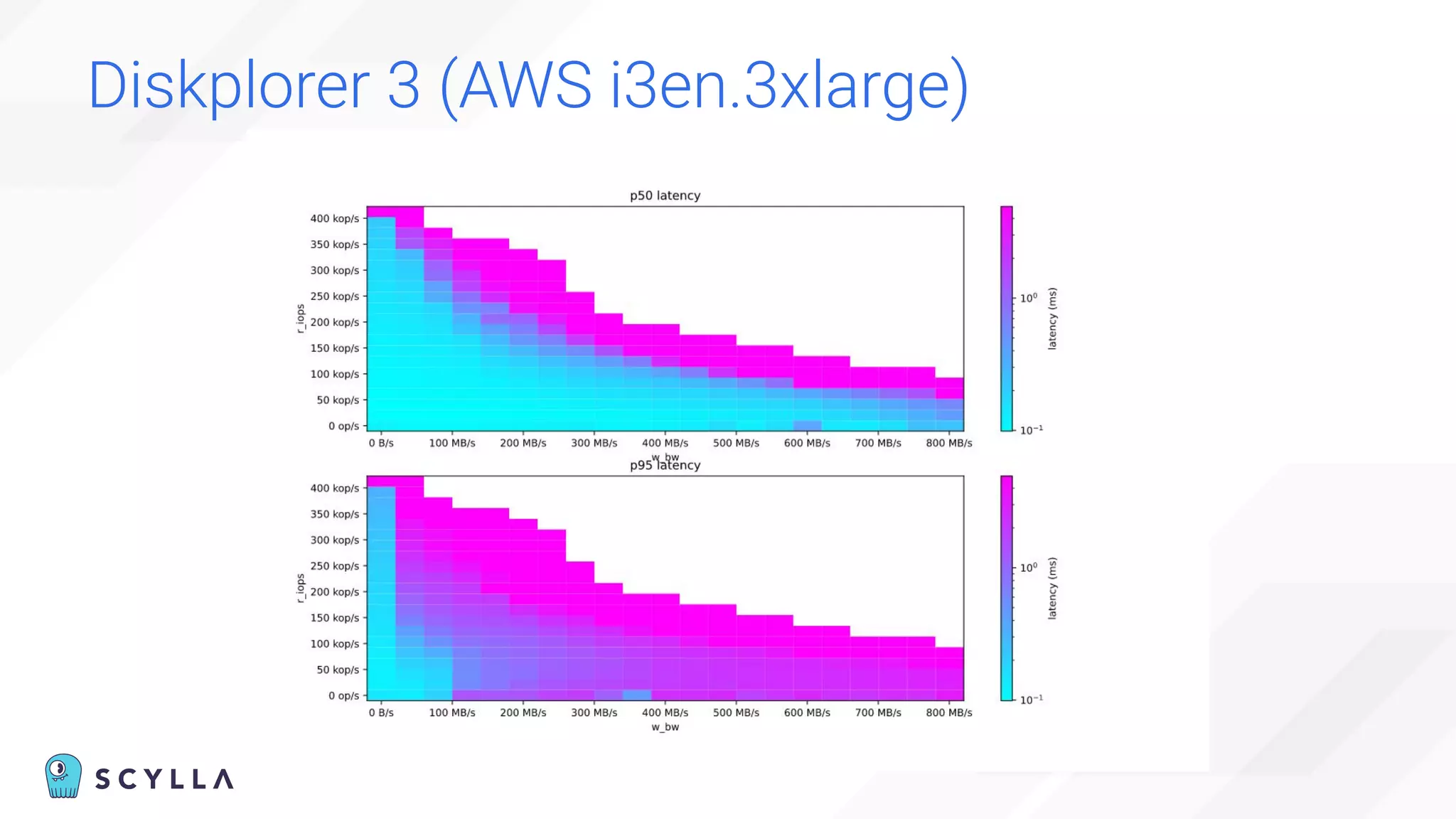


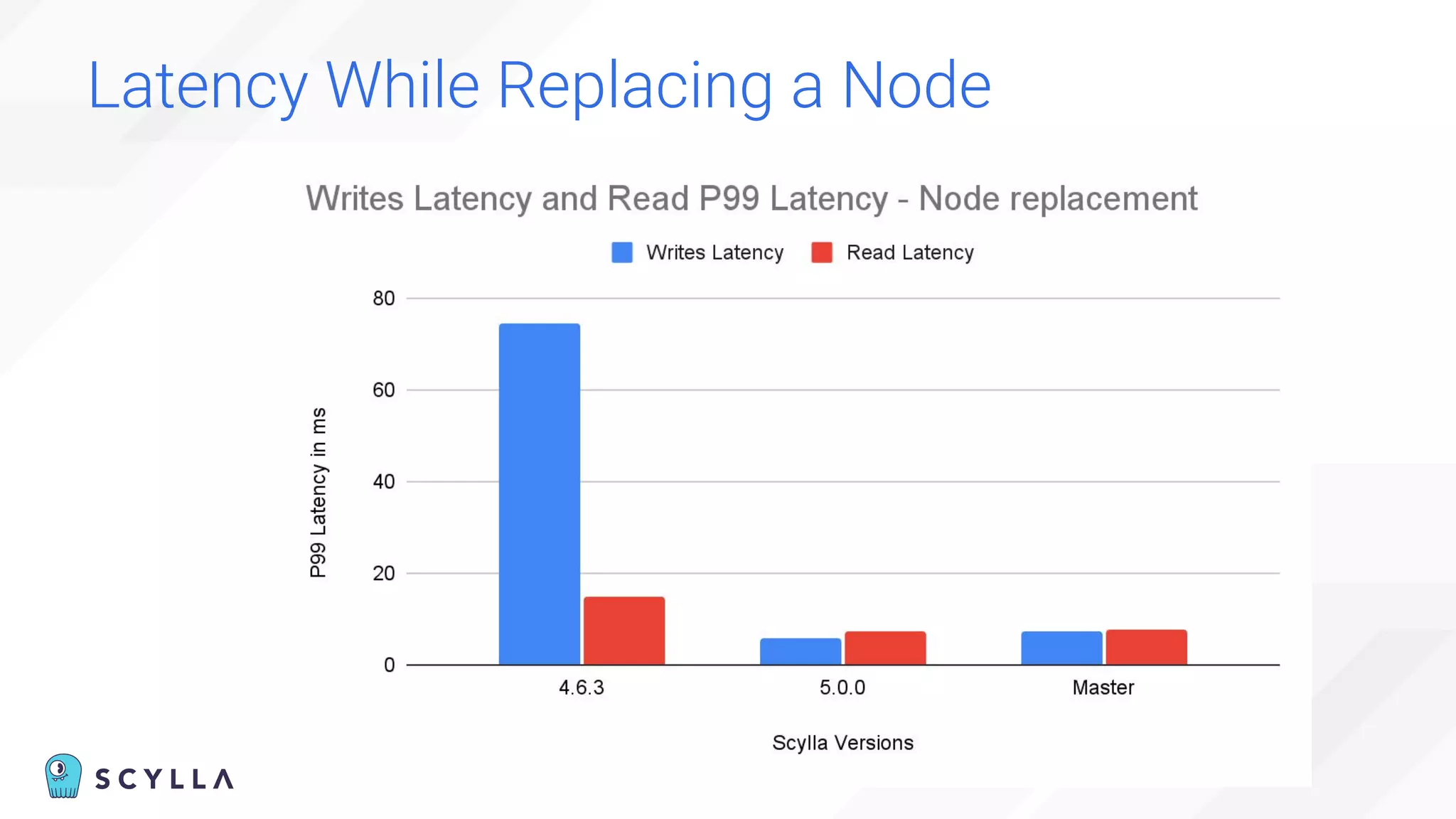
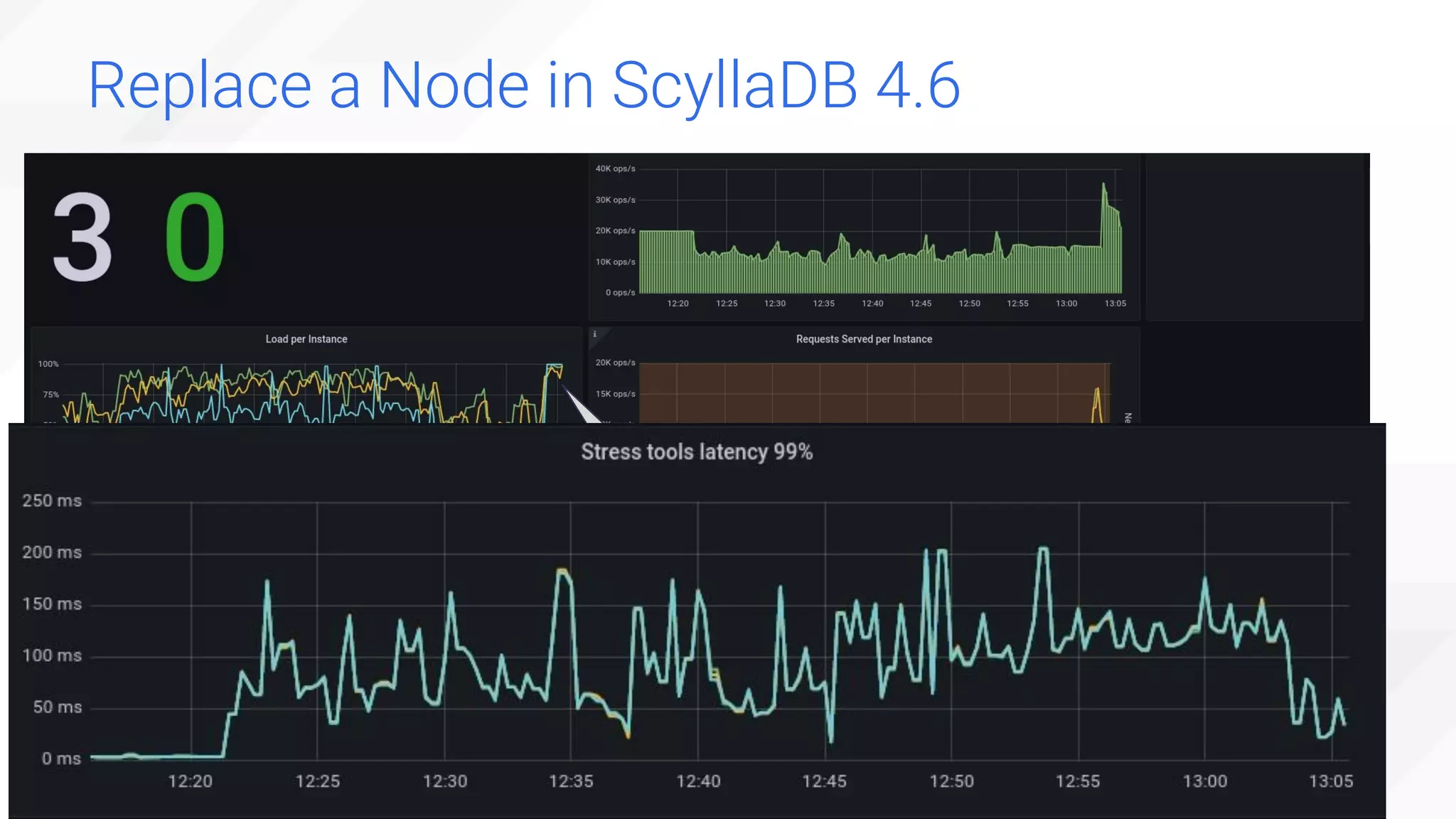
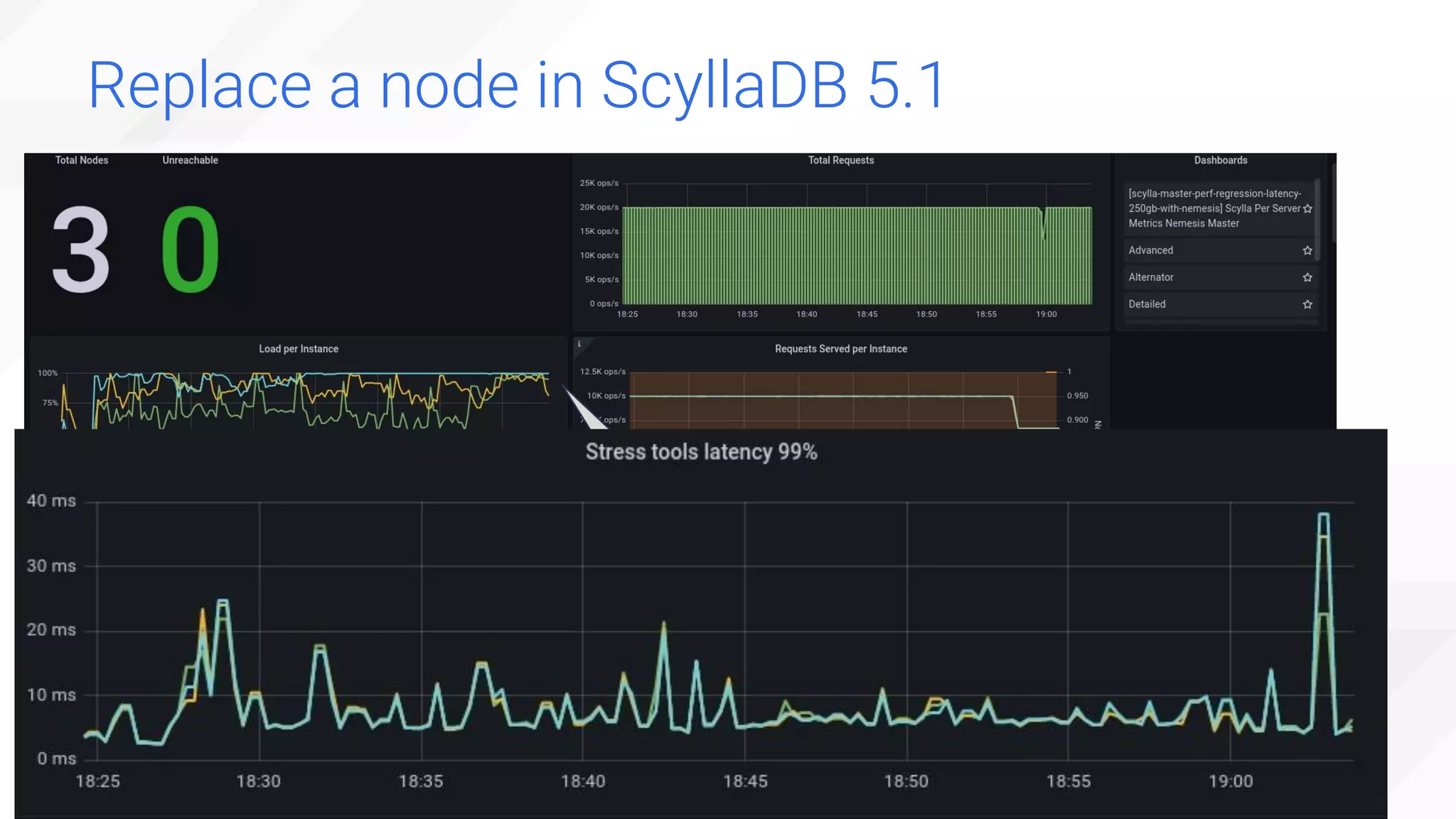

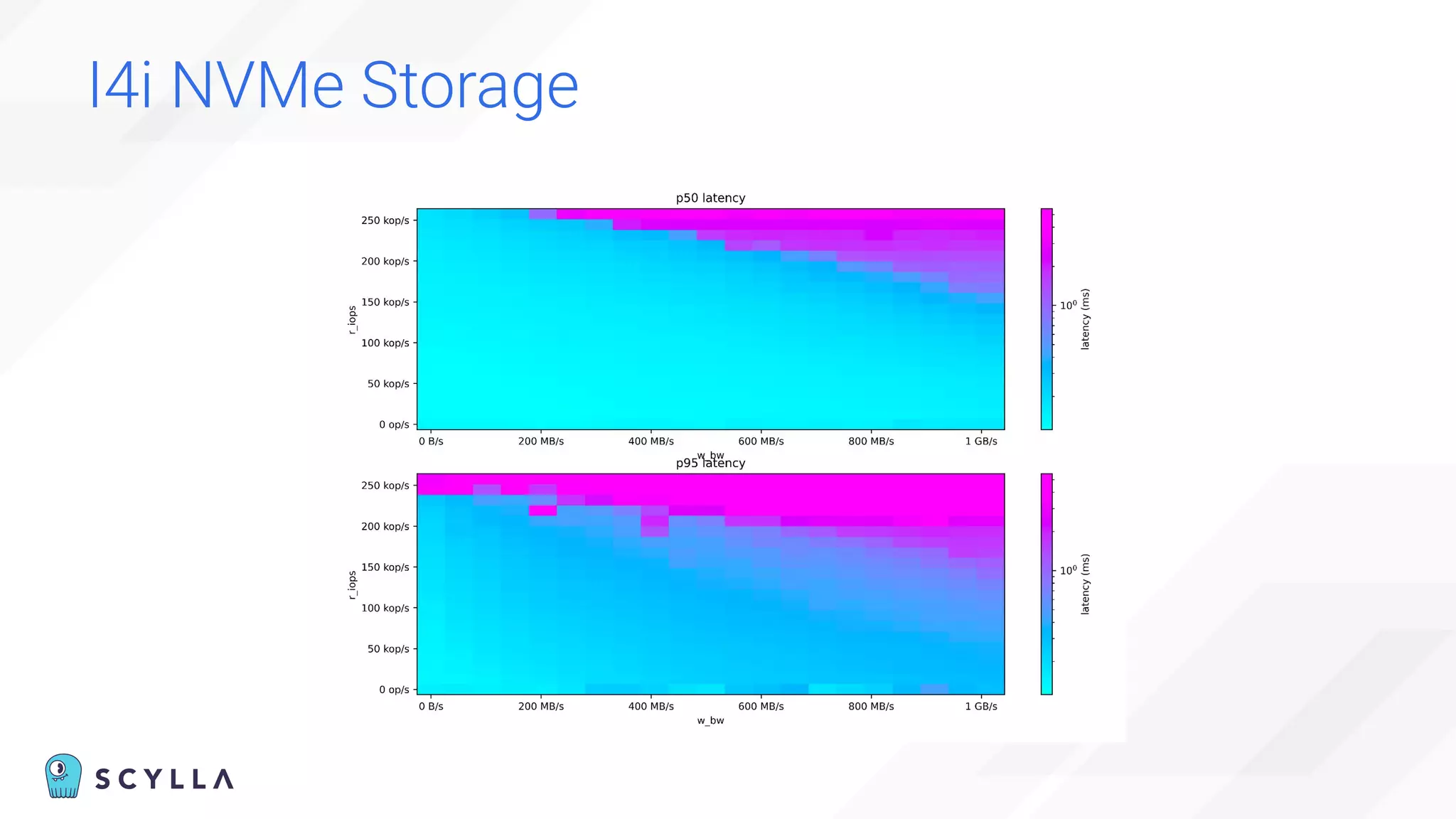
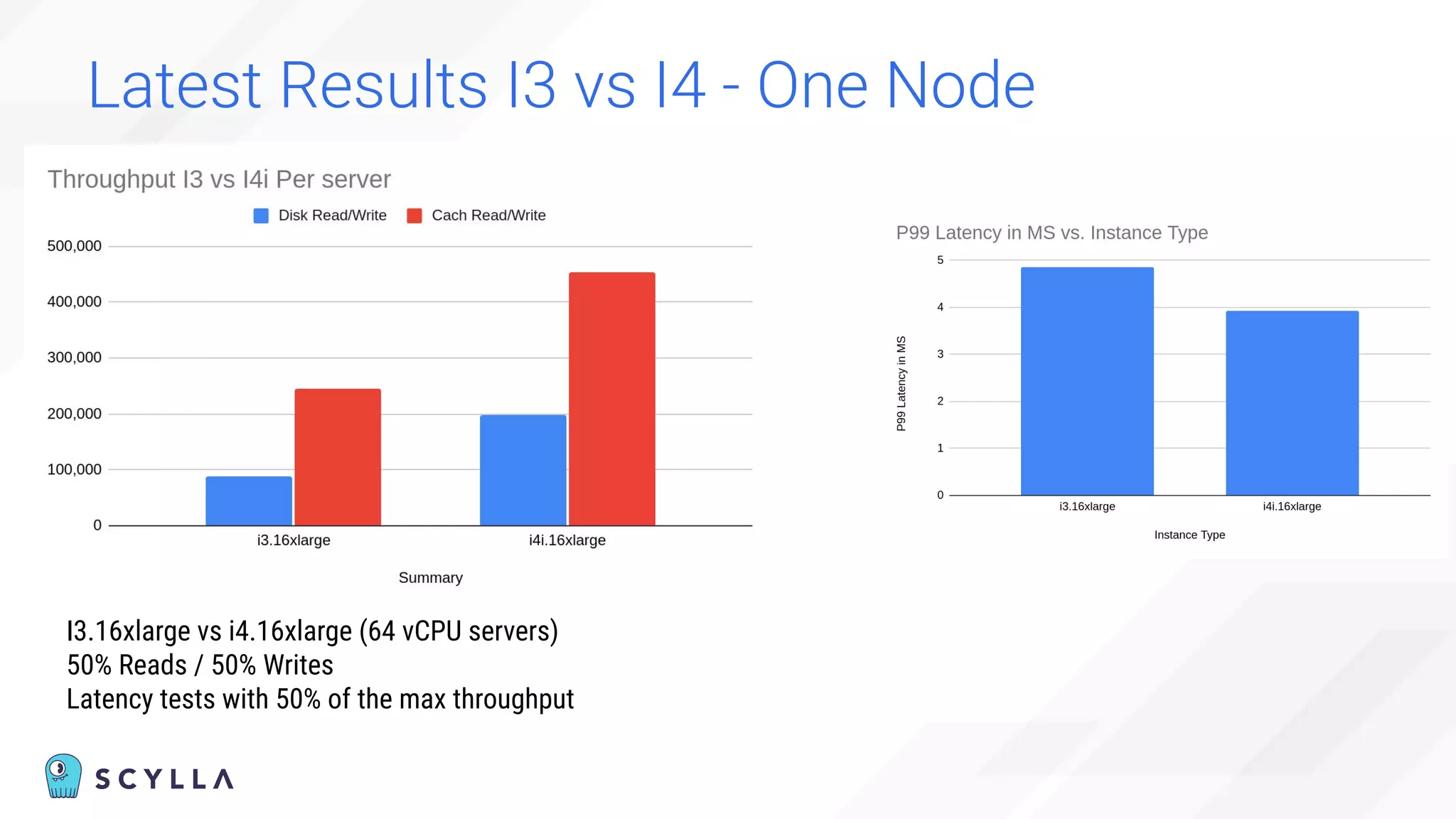
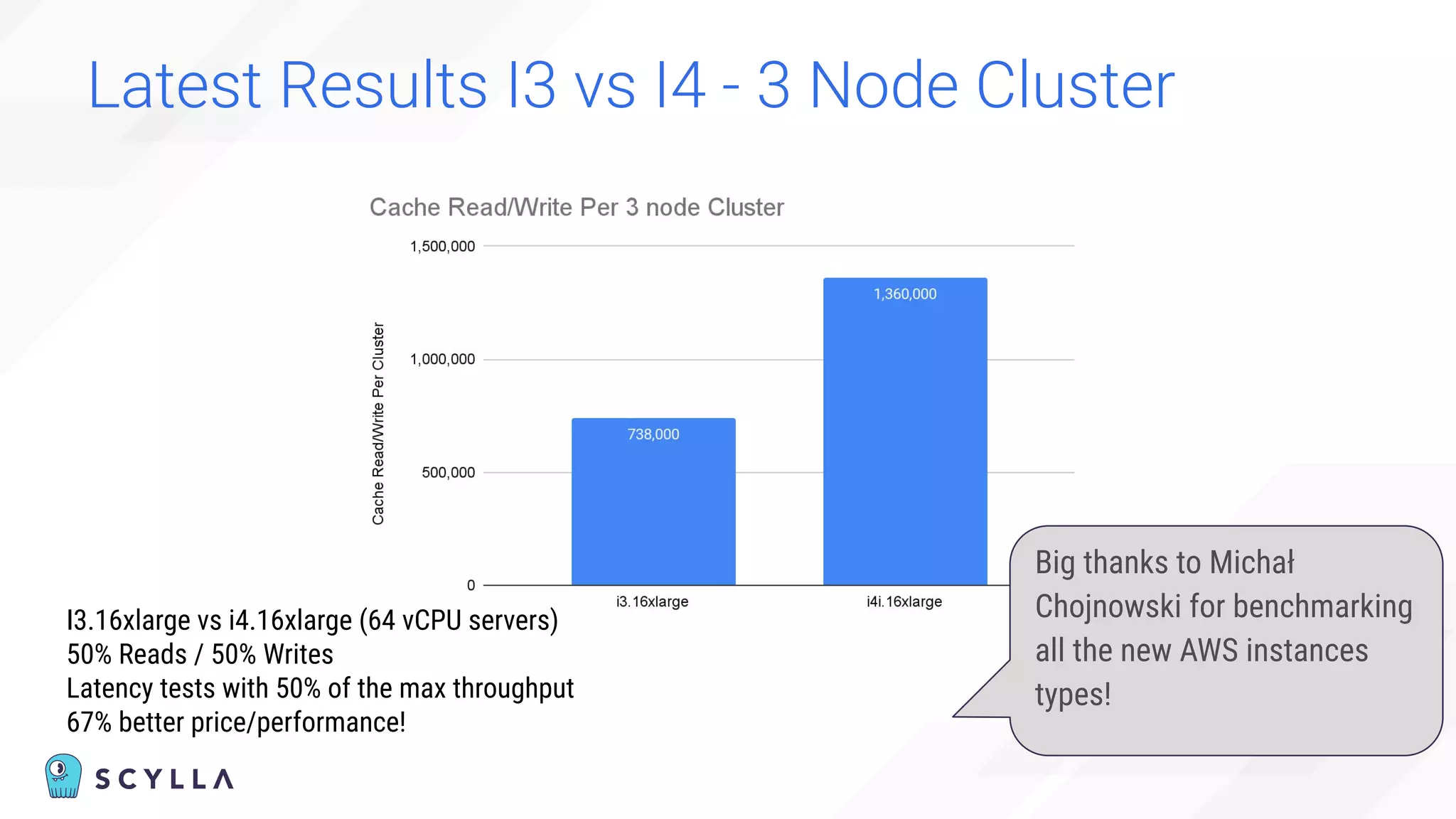


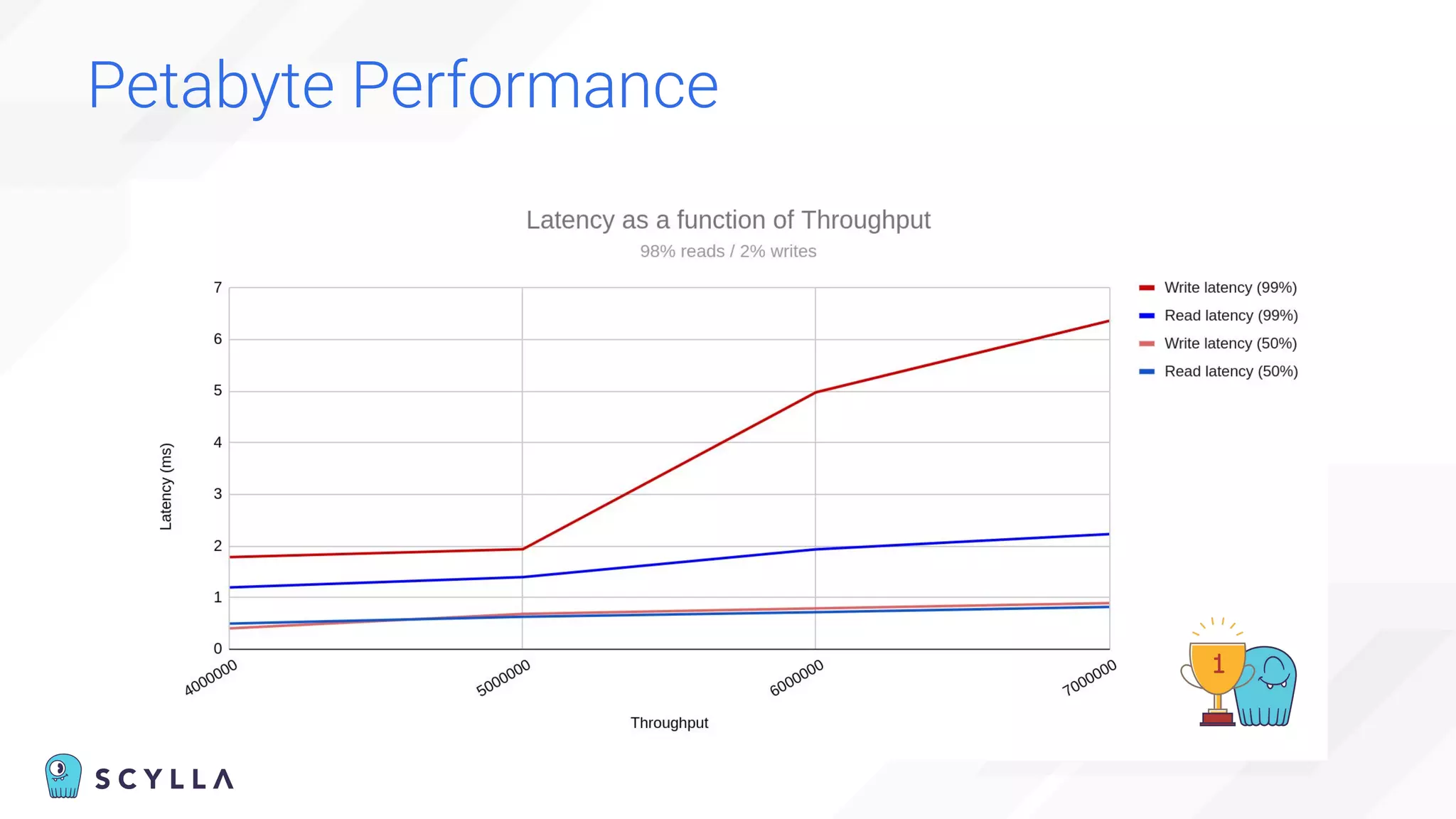









The document is a presentation overview by Benny Halevy and Tzach Livyatan regarding ScyllaDB, emphasizing its innovative database architecture designed for high performance and scalability. It highlights performance benchmarks showing ScyllaDB's superiority over legacy NoSQL databases, offering significant improvements in throughput and latency at a lower total cost of ownership. Additionally, it discusses technical aspects, historical context, and use cases demonstrating ScyllaDB's capabilities across various industries.



































































