Downloaded 10 times






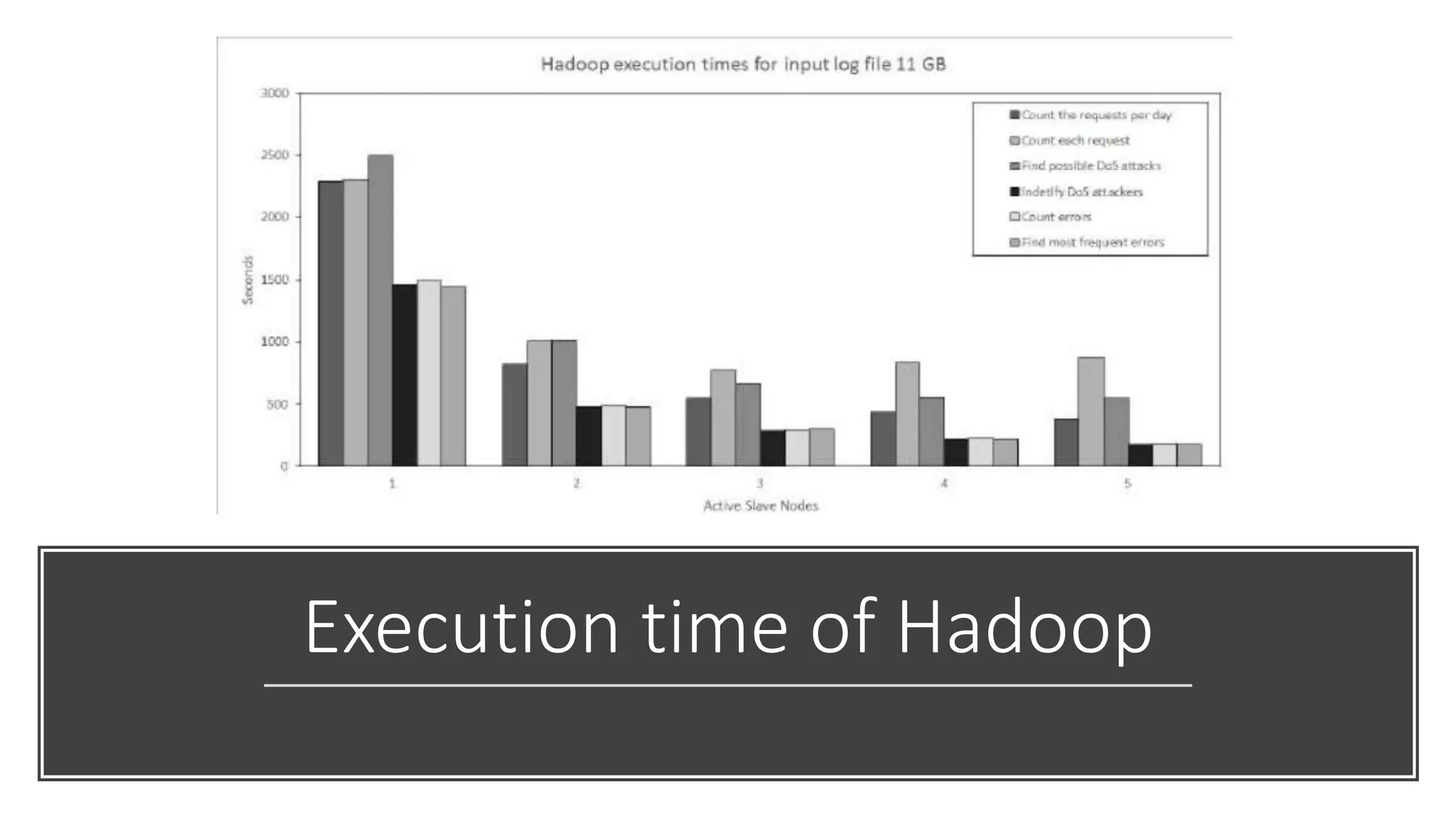
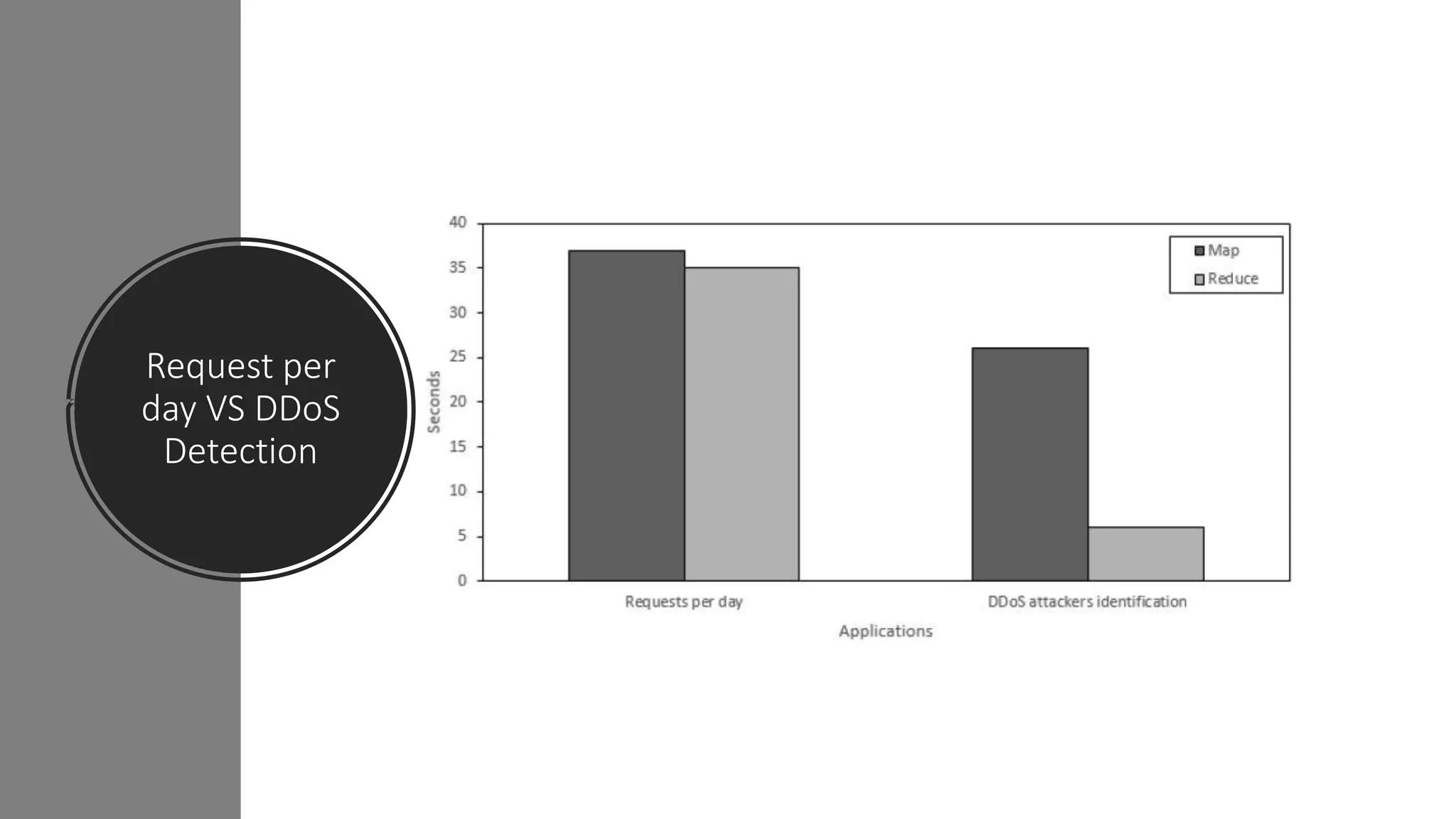
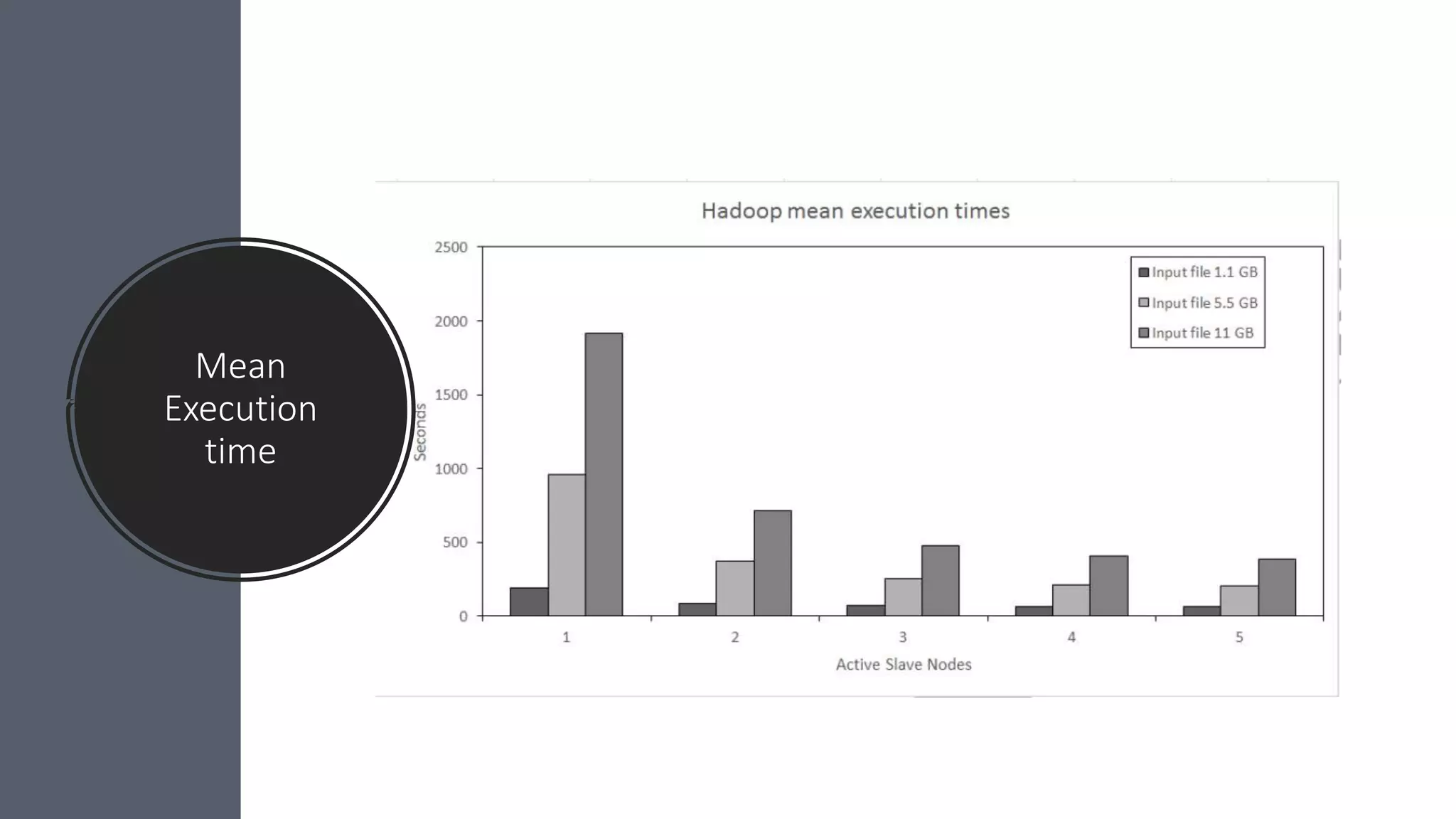
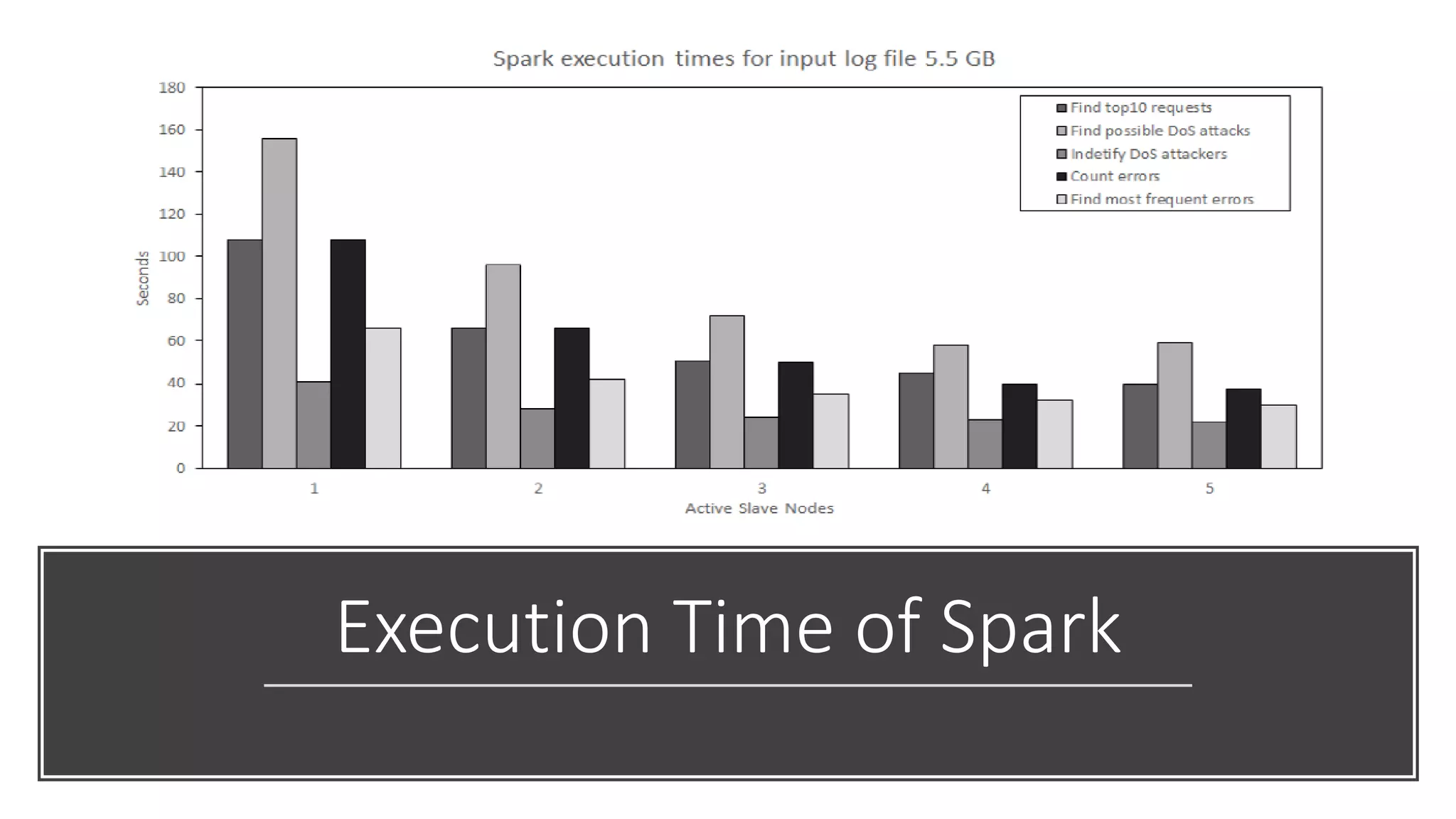
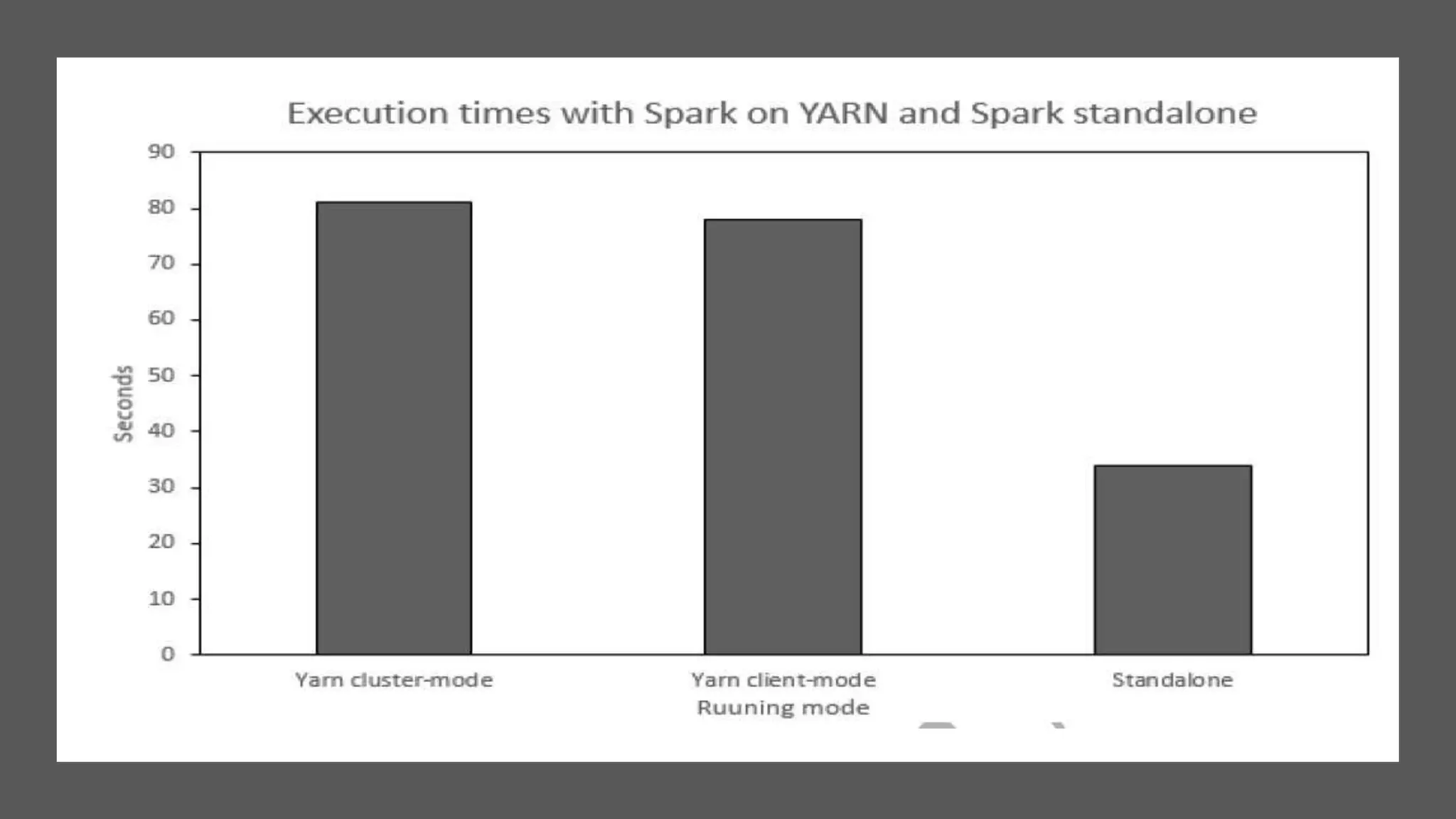
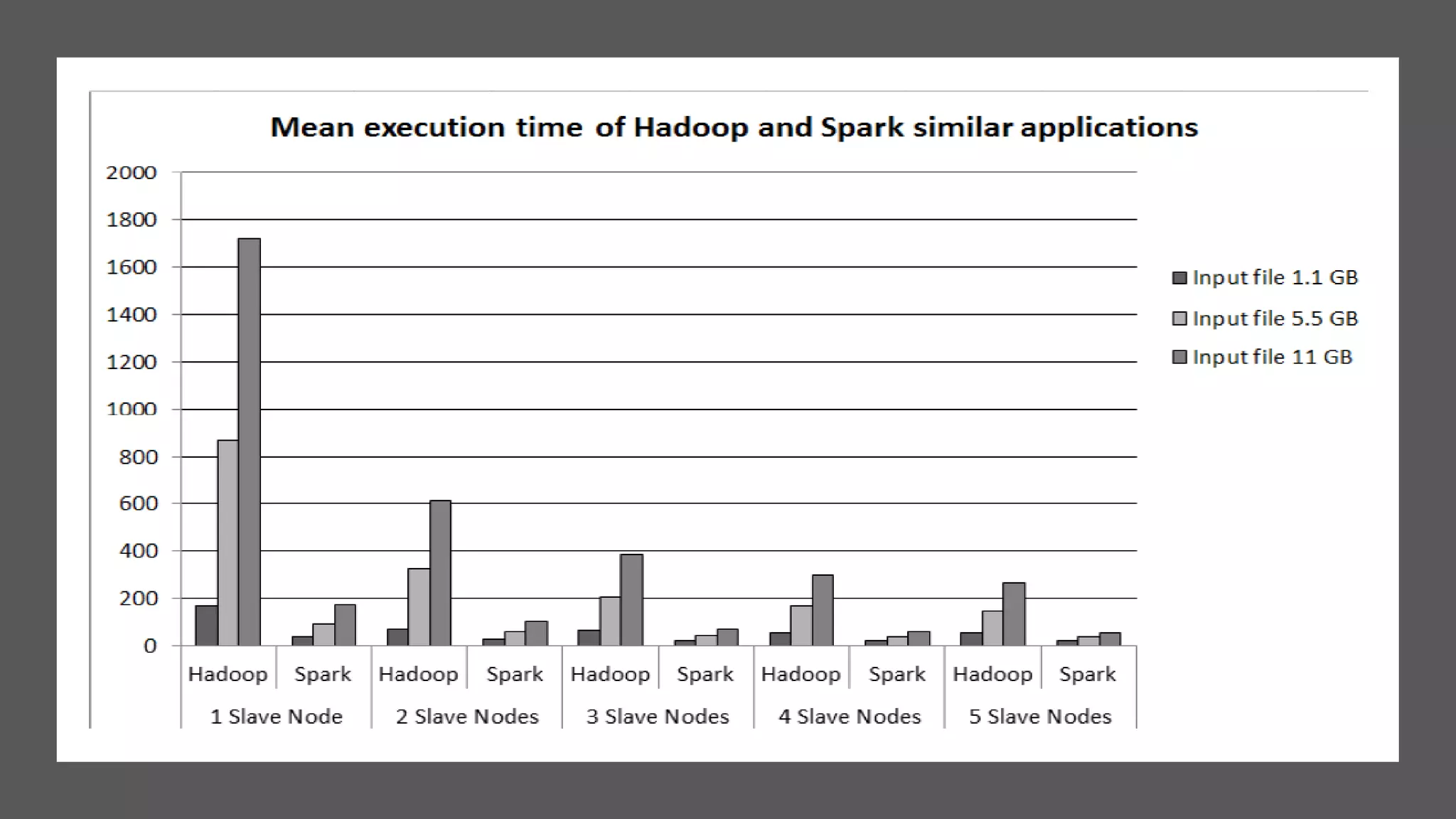
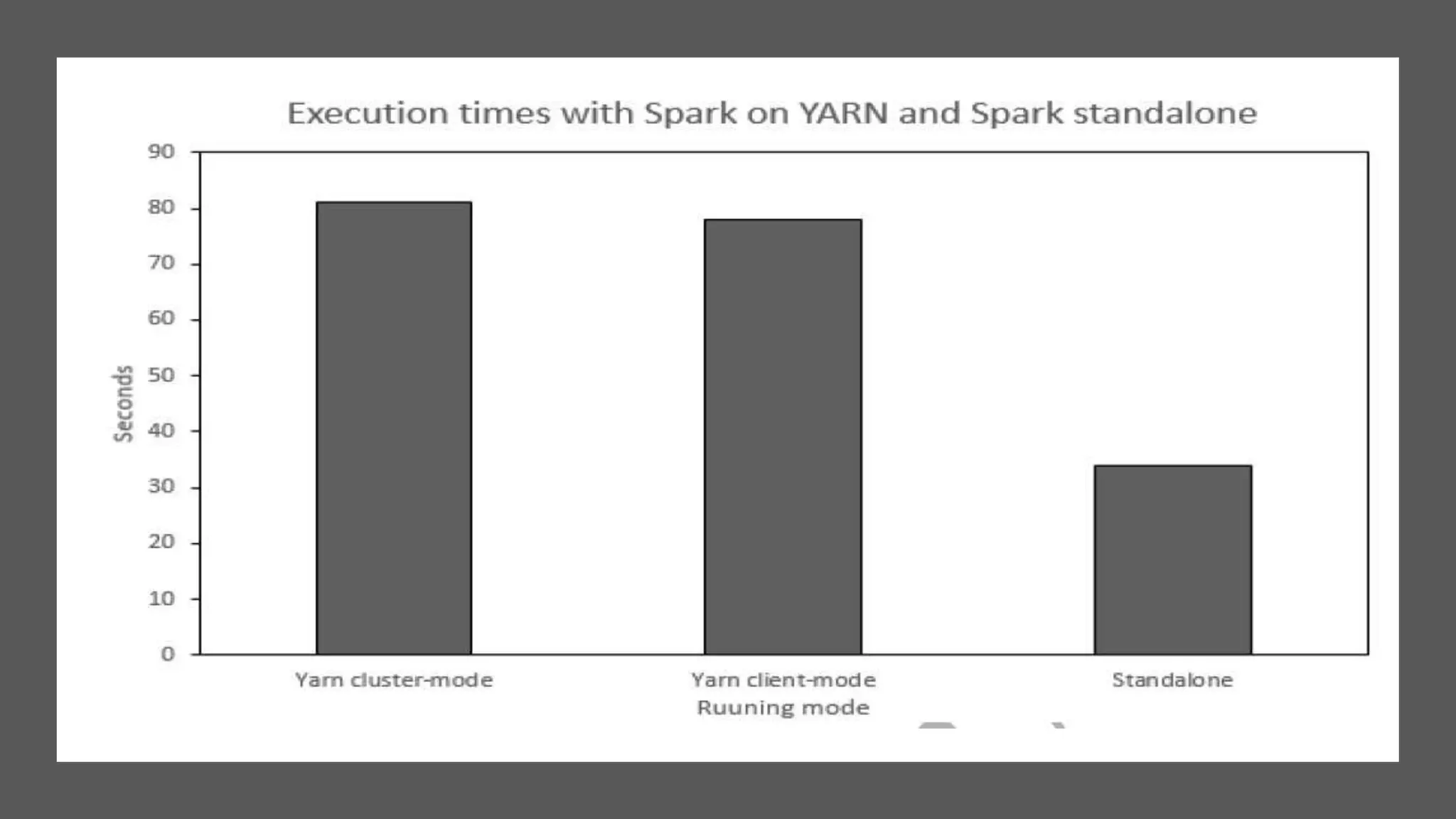
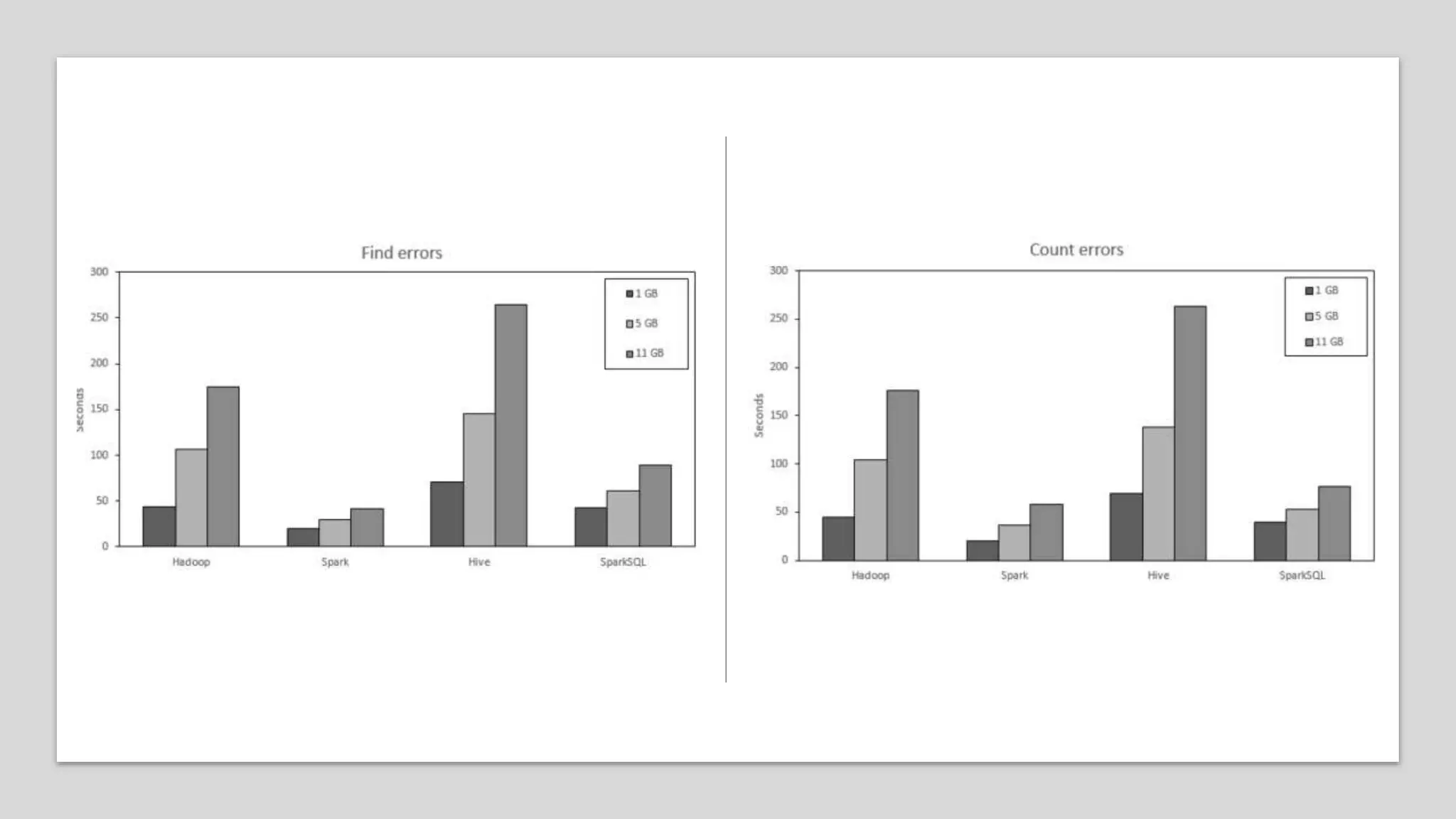
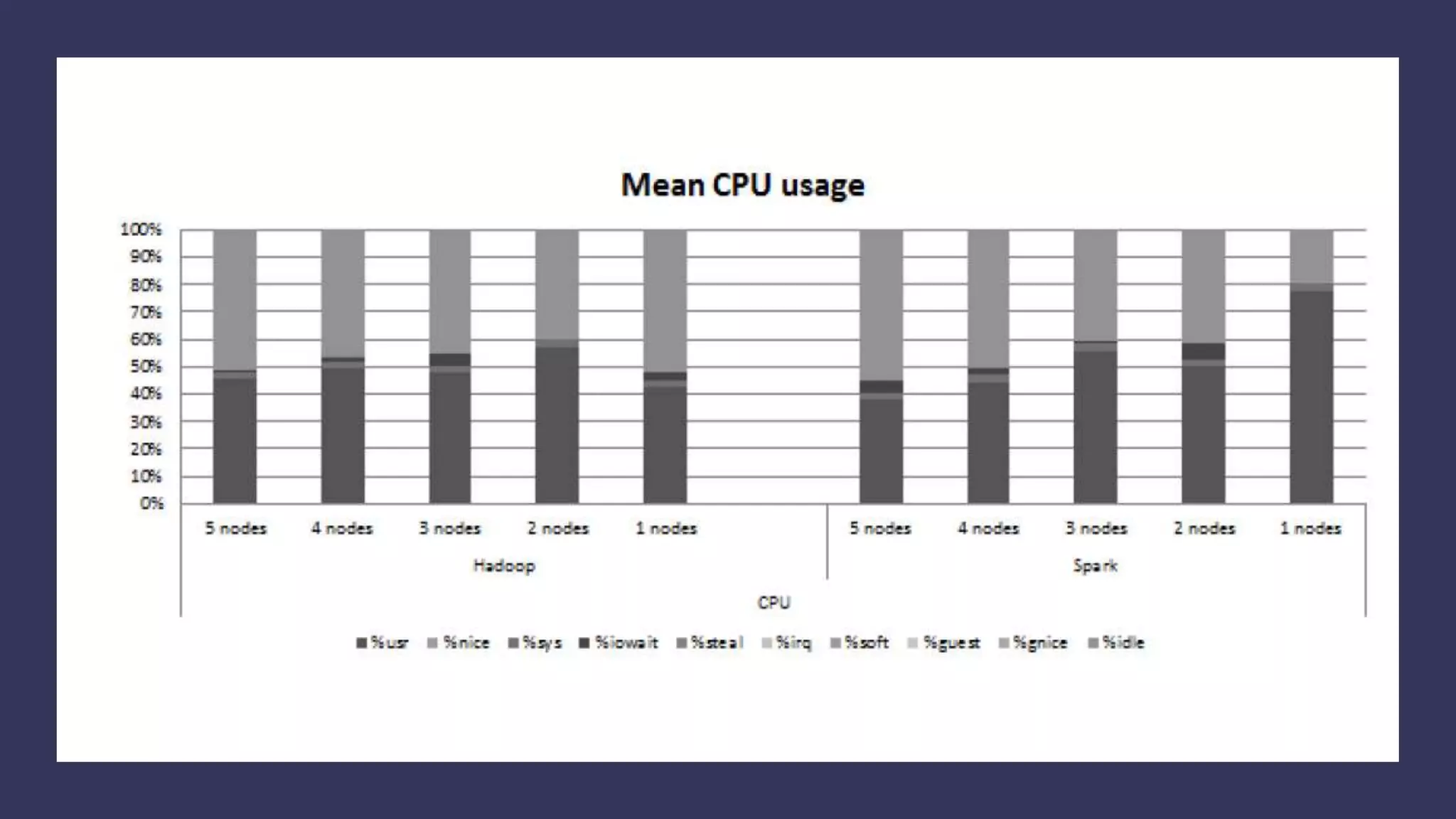
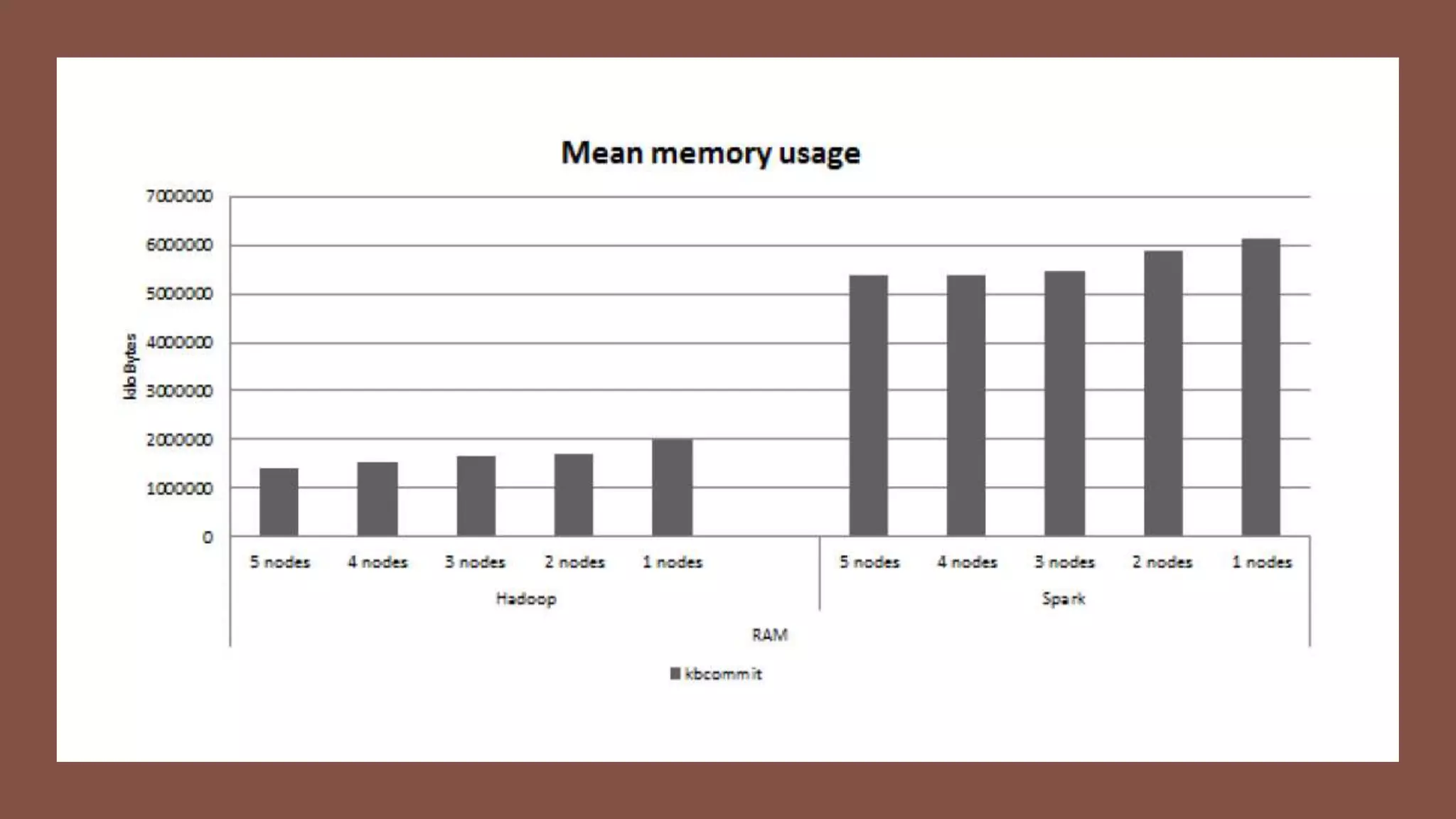
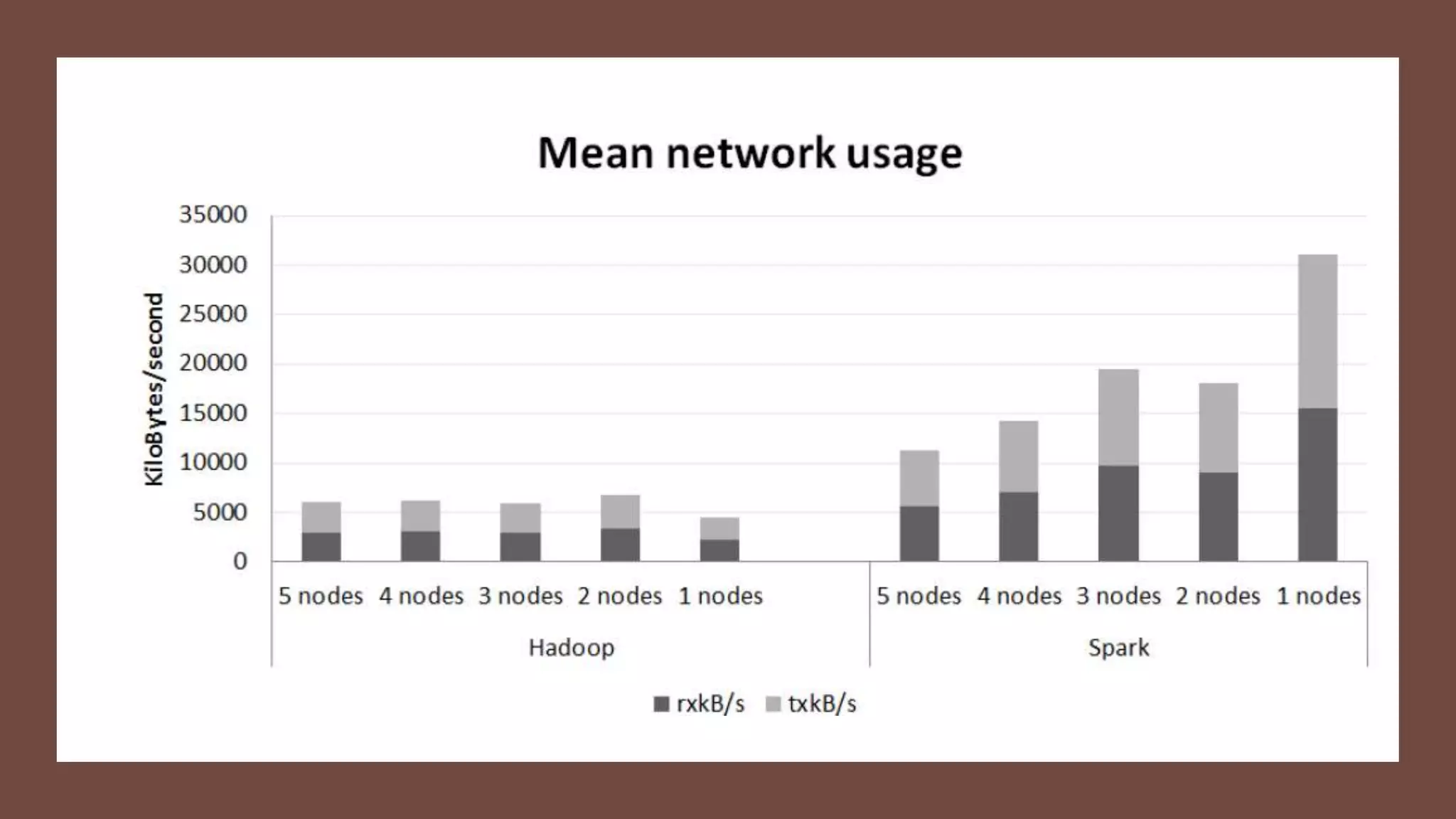
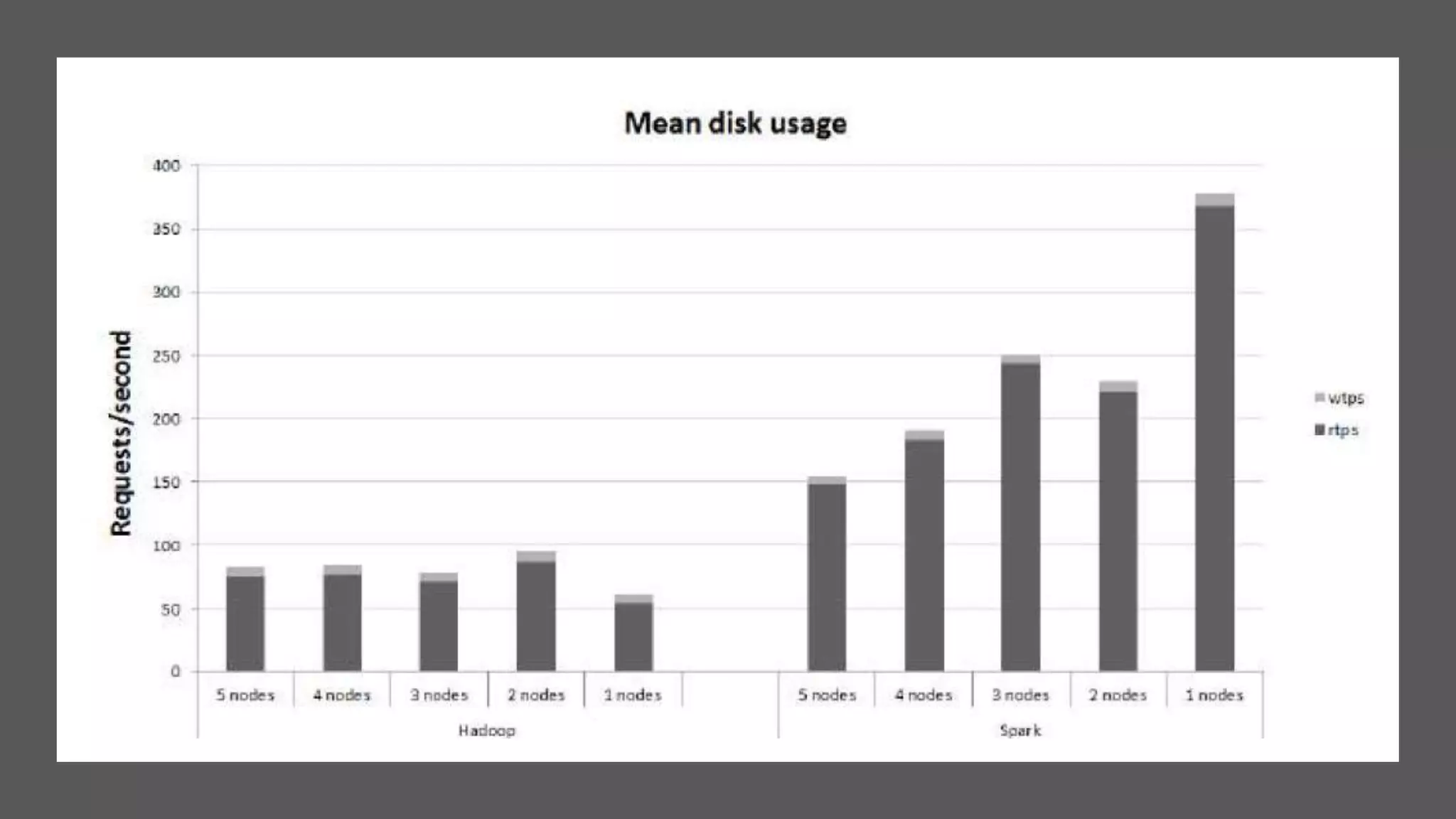






This paper evaluates the performance of Apache Hadoop and Apache Spark for log file analysis on cloud computing systems. The paper presents 6 experimental scenarios analyzing Apache HTTP server log files, including measuring request trends, popular requests, detecting distributed denial of service attacks, and error analysis. The experiments found that Spark performed the analyses faster than Hadoop in most cases but Hadoop was more efficient in terms of energy consumption. The paper concludes that Hadoop and Spark can both be useful for log file analysis on cloud systems, with Spark preferred for time performance and Hadoop preferred when considering energy costs.























































































